요약: 이 블로그는 셜록과 클로이가 AWS re:Invent 2023에 참석한 경험을 나눕니다. 이번 AWS re:Invent 2023 주요 키워드는 Generative AI로, Amazon Q와 Amazon Bedrock 같은 새로운 제품과 기능들이 소개됩니다. 셜록은 Aurora Limitless Database의 대규모 데이터 처리 능력에 중점을 두고, 클로이는 Amplify를 통한 서버리스 웹앱 개발의 편리함을 강조합니다. 또한, 두 사람은 각 세션에서의 개인적인 경험과 인사이트를 공유합니다. 셜록은 AWS re:Invent의 Chalk Talk 세션에서 다양한 국적의 엔지니어들과 아이디어를 공유하는 것이 매우 유익했다고 느꼈습니다. 클로이는 프론트엔드 개발 전략을 AWS 서비스와 연결하는 방법에 대한 세션에서 많은 영감을 받았다고 말합니다.
시작하며
안녕하세요. 카카오페이 자산플랫폼파티 셜록, 허브FE유닛 클로이, 인프라플랫폼팀 빌리, 기술전략팀 댄입니다. 저희는 카카오페이 기술 직군을 대표하여 2023년 11월 26일부터 12월 1일까지 5일 동안 개최된 AWS re:Invent 2023에 참석하게 되었습니다. 저희는 각자 다른 팀에서 일하고 있는데요, 이 글에서는 공동 저자 각자의 지극히 개인적인 관심 주제를 기준으로 Aurora DB, Amplify, Cost Optimization과 Observability에 대해 정리하고 느낀 점을 공유해보고자 합니다.

이 글의 내용은 1편과 2편으로 나누어져서 게재하며, 본편은 1편으로 Aurora DB, Amplify에 대해서 이야기하겠습니다.
2편 글은 아래 바로가기를 확인해 주세요!
👉🏻 AWS re:Invent 2023, 관심 세션을 중심으로 (2편): Cost Optimization, Observability 바로가기
본격적으로 후기를 공유하기에 앞서 AWS re:Invent 2023 키워드를 살펴보겠습니다. 이번 AWS re:Invent 키노트와 여러 세션들을 살펴보면, 주인공은 Generative AI임이 분명합니다. 이에 더해 기존 제품들에 새로운 기능을 추가하거나, 새로운 제품의 베타 버전을 공개했어요.
기존의 다양한 엔드투엔드(end-to-end) 라인업 솔루션에서 새로운 기능이나 업그레이드된 기능들을 소개하면서, AWS의 Generative AI 솔루션들을 특히 강조하고 있는데요. 이러한 다양한 AWS 솔루션들은 생성형 AI 기반 어시스턴트인 Amazon Q에 연결되어 더욱 강력한 사용자 경험을 제공하고 있습니다. (참고)
또한, Amazon Q를 위한 머신러닝 엔진을 제공하는 도구로 Amazon Bedrock을 소개하고 있는데 이 제품은 머신러닝 모델을 선택하여 원하는 형태로 커스터마이징 할 수 있다는 점을 강조하고 있습니다. 즉, Amazon Bedrock을 통해 이 제품에서 제공하는 다양한 머신러닝 모델 중 내가 원하는 서비스에 적합한 모델을 선택하여 서비스에 적용할 수 있게 됩니다. 그럼 AWS re:Invent 2023 키워드 소개는 이것으로 마치고, Aurora DB 관련 세션 후기부터 공유드리겠습니다.
Aurora DB
카카오페이의 자산플랫폼파티에서 마이데이터 백엔드 개발을 하고 있는 셜록입니다.
이번 AWS re:Invent 2023은 모두들 Generative AI가 주인공이라고 얘기하지만, 백엔드 개발자인 저는 첫날 Peter Desantis의 키노트에 등장한 새로운 서버리스(Serverless) 제품의 소개에 관심이 갔습니다.
서버리스 컴퓨팅은 고객이 직접 서버를 관리할 필요 없이 애플리케이션을 빌드하고 실행할 수 있어 보다 효율적으로 애플리케이션을 출시하는데 집중할 수 있게 합니다. AWS는 다양한 영역으로 서버리스 기술을 확장해 왔는데 이번 키노트를 통해 Amazon Aurora Limitless Database, Amazon ElastiCache Serverless, Amazon Redshift Serverless 제품을 선보였어요.
저는 카카오페이에서 마이데이터 플랫폼을 개발하는 업무를 담당하고 있기 때문에 대용량 데이터 처리에 대한 고민을 항상 하고 있었고, 이 고민을 해결해 줄 또 하나의 방법인 Aurora Limitless Database에 대해 간단하게 정리해보려 합니다.
기존의 Aurora Database와 샤딩
기존의 Aurora Database 최대 볼륨 크기는 128 tebibytes(TiB)였어요(1 TiB = 1024 GiB). 처음에 마이데이터 플랫폼의 데이터베이스로 Aurora를 고려했을 때 우려되었던 점들 중 하나는 최대 볼륨 크기였는데요. 그 이유는 카카오페이의 수많은 고객들의 금융데이터를 저장하기 위해서 128 TiB보다 더 큰 용량이 필요할 수도 있었기 때문입니다. 또한 데이터 규모가 커지면 커질수록, 트래픽이 많아지면 많아질수록 데이터베이스의 부담이 증가하기 때문에 대부분의 경우 샤딩(Sharding)을 구현해 더 많은 트래픽과, 더 많은 데이터를 관리하는 것을 고려하게 됩니다.
샤딩은 기본적으로 매우 복잡하고 관리가 어려운데요. 예를 들어 처음에 샤딩을 한 후에 데이터가 각 샤드에 고르게 분배되지 않아 특정 샤드가 너무 커졌을 경우, 이 샤드를 분산시키기 위해서 또다시 샤딩을 하는 재샤딩(re-sharding) 이슈가 있습니다. 카카오페이와 같이 24/7 서비스를 제공해야 하는 회사에서는 서비스를 운영하며 실시간으로 다시 샤딩을 적용해야 하기 때문에 매우 부담스러울 수밖에 없어요. 이런 이슈를 피하기 위해 아예 재샤딩이 일어나지 않도록 넉넉한 공간을 미리 할당하는 등의 방법을 사용합니다. 하지만 이런 방법은 사용되지 않는 리소스를 미리 할당하기 때문에 효율적인 방법이라고 볼 수는 없습니다.
또 다른 이슈로는 DDL(Data Definition Language) 이슈가 있습니다. 테이블의 특정 컬럼을 변경하거나 새로운 컬럼을 추가한다면, 샤딩된 모든 데이터베이스에 일관성 있게 DDL을 수행할 수 있는 방법이 필요합니다. 이 외에도 샤드 간 조인, 여러 샤드의 데이터 업데이트, 분산 트랜잭션의 백업 이슈 등 여러 복잡한 관리 포인트들이 발생하게 됩니다.
Aurora Limitless Database
Aurora Limitless Database의 등장으로 이제는 페타바이트 규모의 데이터를 관리할 수 있으며 초당 수백만 건의 쓰기 트랜잭션을 처리할 수 있게 되어서 Database 및 플랫폼 아키텍처의 선택의 폭이 더 넓어지게 되었습니다.
그렇다면 Aurora Limitless Database는 어떻게 이렇게 큰 규모의 데이터를 관리하고 많은 트래픽을 처리할 수 있을까요?
저는 AWS re:Invent의 여러 세션을 통해 Aurora의 설계에 대해 알아볼 수 있었습니다. Aurora Limitless Database는 내부적으로 샤딩을 구현하고 있는데요. 샤딩을 구현했기 때문에 샤딩이 가지는 장점들도 대부분 누릴 수 있었고, 샤딩을 직접 구현하면서 불편하고 어려웠던 점들도 일부 해결하고 있습니다.
세션의 설명에 따르면 Aurora Limitless Database는 샤딩을 더 쉽게 만들도록 설계되었습니다.
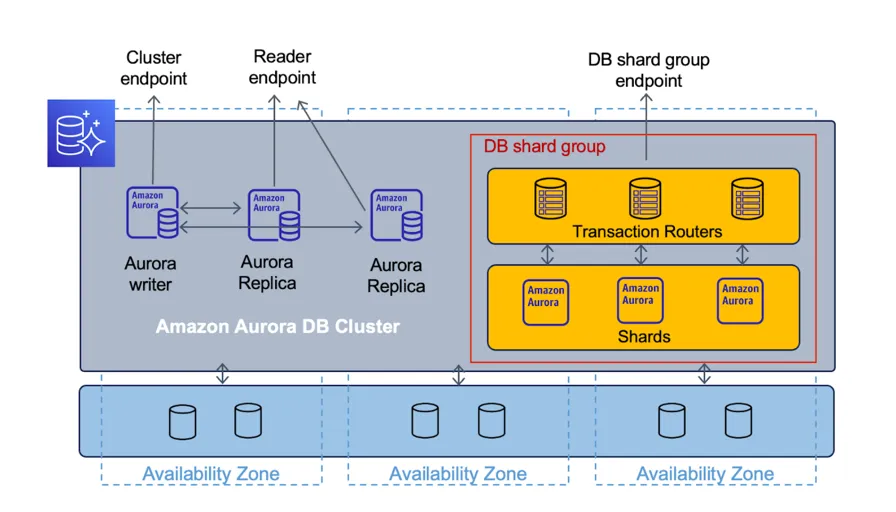
또한 DB shard group이라는 새로운 개념이 도입되었습니다. 샤드 그룹 내에는 Transaction Routers라는 핵심 계층이 존재하는데요. 이 계층에서는 샤딩된 테이블 전체를 쿼리 하는 데 사용할 수 있는 단일 엔드포인트를 제공하고, 여러 샤드에 걸친 쿼리를 처리하며, 데이터베이스 커넥션을 생성하는 등의 작업을 수행합니다. 그리고 부하에 따라 구성된 한도 내에서 리소스를 확장/축소하며 모든 샤드에서 데이터가 일관되게 처리되는지를 이 계층에서 처리하게 되는데요. 이를 통해 샤딩을 직접 구현할 때 고려해야 했던 많은 복잡성들을 해결할 수 있습니다.
샤드 그룹의 또 다른 계층인 Shards는 Aurora의 집합이라고 생각할 수 있는데요. 이를 통해 128 TiB의 볼륨 대신 128 TiB까지 확장 가능한 여러 개의 Aurora 클러스터를 가질 수 있게 되고, 이론적으로 무제한의 볼륨을 확보할 수 있습니다.
위와 같은 기능들을 제공하기 때문에 기존에 대용량 데이터를 다루기 위해 했던 수많은 고민들을 해소할 수 있을 것이라는 기대를 해볼 수 있었습니다. 대용량의 데이터를 관리하기 위한 방법들을 AWS에서도 해결하기 위해 노력했다는 것이 너무 흥미로웠고, 마이데이터 플랫폼에 적용할 수 있는 다양한 아이디어를 얻을 수 있었습니다. 앞으로 Aurora가 어떻게 발전해 나갈지 기대가 됩니다.🙂
Amplify
카카오페이의 허브FE유닛에서 프론트엔드 개발을 담당하고 있는 클로이입니다.
이번 컨퍼런스에 참석하면서 제 직군인 프론트엔드와 연관성이 있고, 평소 관심을 가지고 있기도 한 web과 mobile 세션들을 찾아보게 되었습니다. 관련하여 Amplify, AppSync, CloudFront 등을 주제로 하는 세션들이 있었는데요. 개발 중심적인 주제를 다루는 Amplify 세션들에 자연스레 관심이 가게 되었습니다.
Amplify는 클라우드 환경에서 풀스택 및 모바일 웹앱을 구축하는데 필요한 모든 것을 제공하는 서비스들의 집합으로, 프론트엔드 개발자가 백엔드, 프론트엔드, 배포, 호스팅까지 풀스택으로 애플리케이션을 빠르고 쉽게 구축할 수 있는 서버리스(serverless) 솔루션입니다. Amplify의 컨셉이나 서비스에 대한 자세한 소개는 이번에 개편된 문서를 참고해 주세요.
저는 Amplify와 관련해서 다음 3개의 세션을 참석했는데요.
- Accelerate web and mobile development with AWS Amplify (FWM314)
- What’s new for web & mobile app developers with AWS Amplify (FWM306)
- Dive Deeper into web app development and hosting with AWS Amplify (FWM309)
위 세션들은 Amplify Gen2를 비롯하여 Amplify에 신규로 추가된 기능들에 대한 소개를 바탕으로 다양한 유즈케이스(use case)에 대한 데모가 함께 진행되었습니다. 개인적으로는 발표와 코드 베이스의 데모를 함께 볼 수 있어서 이해가 더 잘 되었던 것 같아요. 이번 파트에서는 Amplify에 새롭게 추가된 새로운 기능에 대한 소개와 흥미롭게 느꼈던 부분에 대해서 공유해보고자 합니다.
세 세션은 공통적으로 Amplify를 개발자 경험 향상, 배포 프로세스 개선, 확장가능성의 세 가지 관점에서 설명했는데요. 하나씩 살펴보겠습니다.
Accelerate development
Code-First Development Experience

Amplify에서 가장 큰 변화이자 이전 버전에서 크게 개선되었다고 할 수 있는 부분은 코드 우선 중심으로 개발자 경험을 향상했다는 점입니다. 세 세션에서는 공통적으로 Amplify Gen2에서 파일 기반 규칙으로 백엔드를 구성하고 프론트엔드까지 풀스택으로 구현할 수 있다는 점을 소개하고 있는데요. 별도의 CLI나 studio를 사용하여 인프라 프로비져닝을 진행해야 했던 Gen1과 달리 Gen2는 파일 기반 규칙에 맞게 코드를 작성하고 배포하면 백엔드 리소스가 자동으로 프로비저닝 됩니다. 이러한 개선은 Amplify의 이전 버전에 대한 사용자들의 피드백에서 영감을 받아 개선이 이루어졌다고 해요.
간단한 예시로 amplify/auth/resource.ts나 amplify/data/resource.ts와 같이 파일 기반 규칙을 따른 파일들을 생성한다면 경로나 이름에서도 유추할 수 있듯이 amplify/auth/resource.ts 파일에서는 인증에 대한 설정을, amplify/data/resource.ts 파일에서는 데이터 모델을 graphql을 통해 정의할 수 있습니다. 이후 별다른 설정 없이 작성한 코드를 배포하게 되면 AWS dynamoDB나 AWS RDS와 같은 리소스를 자동으로 할당받게 됩니다. 이런 워크플로우는 개발자가 코드에만 집중할 수 있게 만들고, 인프라를 크게 신경 쓰지 않고도 서비스를 빠르게 구축할 수 있게 합니다.
파일 기반 규칙뿐만 아니라 typescript의 풀스택 지원에 대해서도 중요하게 다루었는데요. 많은 프론트엔드 개발자들이 사용하고 있는 typescript라는 대중적인 언어를 지원하고 타입 안정성을 갖는 언어의 특성이 풀스택으로 비즈니스 로직을 작성하고 배포하는데 많은 도움을 줄 것이라고 강조합니다.
Faster local development
개발자 경험과 관련해 흥미로웠던 또 다른 부분은 개별 샌드박스 환경을 제공한다는 점입니다. 샌드박스 환경이 하나밖에 없다면, 동시에 개발이 진행되는 서비스의 경우 개발과 QA 과정에서 예상하지 못한 충돌이나 이슈가 발생하여 프로덕트의 개발 속도를 느리게 만들 수도 있는데요. Amplify팀은 이러한 고민을 해결하고자 각 개발자나 git branch별로 격리된 샌드박스 환경을 제공하여 변경 사항을 빠르게 테스트할 수 있도록 도와주며 신속한 프로덕트 개발 주기를 지원합니다. 이러한 변화는 이전 버전으로 배포하는 것보다 약 8배 정도 빠르다고 합니다.
New AWS Amplify JS Library v6 (JavaScript v6)
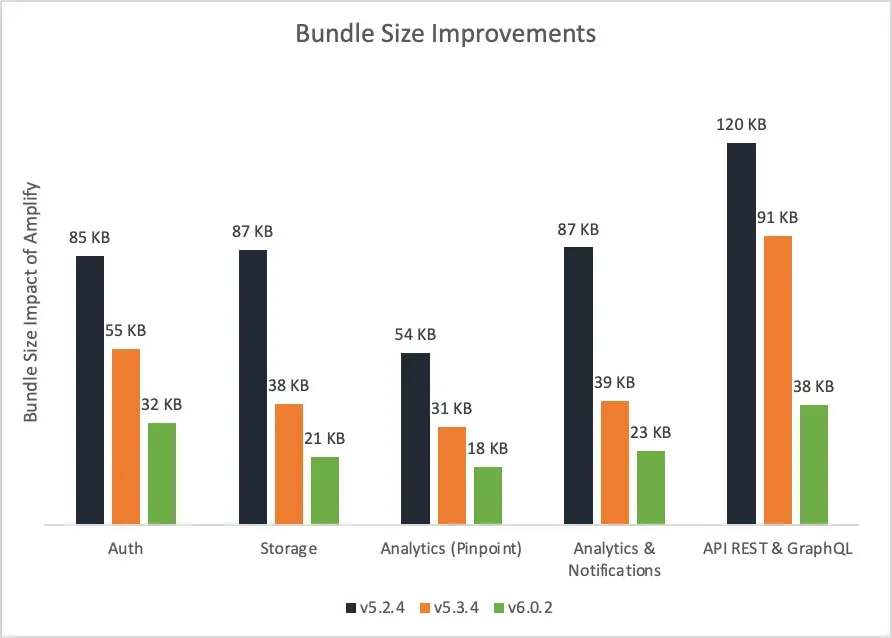
Amplify JS Library v6에서는 많은 사용자들이 요구했던 기능 중 하나인 번들 사이즈 최적화가 이루어졌는데요. tree shaking을 개선하여 기능에 따라 원하는 js 파일을 로드할 수 있습니다. 데이터만 원할 경우 데이터 부분의 js만 로드하고 인증만 원할 경우 인증과 관련된 js를 로드하도록 합니다. 이러한 최적화는 Rest API와 graphql과 관련된 데이터 js 번들 사이즈의 경우 v5와 비교 시 약 58%가 감소되는 효과를 보여주었습니다.
v6에 포함되는 또 다른 기능 중 하나는 typescript와 next.js 프레임워크에 대한 지원을 향상했다는 점인데요. next.js의 경우 app router와 page router를 모두 지원하고 middleware를 사용할 수 있습니다. 즉, next.js를 어떠한 식으로 구축하든지 Amplify 라이브러리와 함께 사용할 수 있다는 것을 의미합니다.
CodeWhisperer와 Amazon Q
이번 AWS re:Invent의 핵심 주제는 Generative AI였고 expo에서도 AI 관련 여러 파트너사들의 참여를 볼 수 있었는데요. 그만큼 전 세계적으로 AI가 뜨거운 관심 속에 있음을 느낄 수 있었습니다.
이런 AI에 대한 관심은 Amplify에서도 찾아볼 수 있었는데요. Amplify에서는 AI기반의 CodeWhisperer와 Amazon Q로 개발 경험과 속도 향상에 도움을 줄 수 있습니다. 예를 들면 데이터 모델을 정의하는 grpahql 코드 작성 시 특정 필드명을 입력하면 Amplify 데이터로 학습된 CodeWhisperer는 필드명을 보고 데이터 타입을 유추해 낼 수 있습니다. FWM306 세션 발표를 진행했던 연사자 Ali는 CodeWhipsperer의 도움으로 새로운 애플리케이션을 구축하는 프로세스의 속도가 빨라졌다고 강조했습니다.
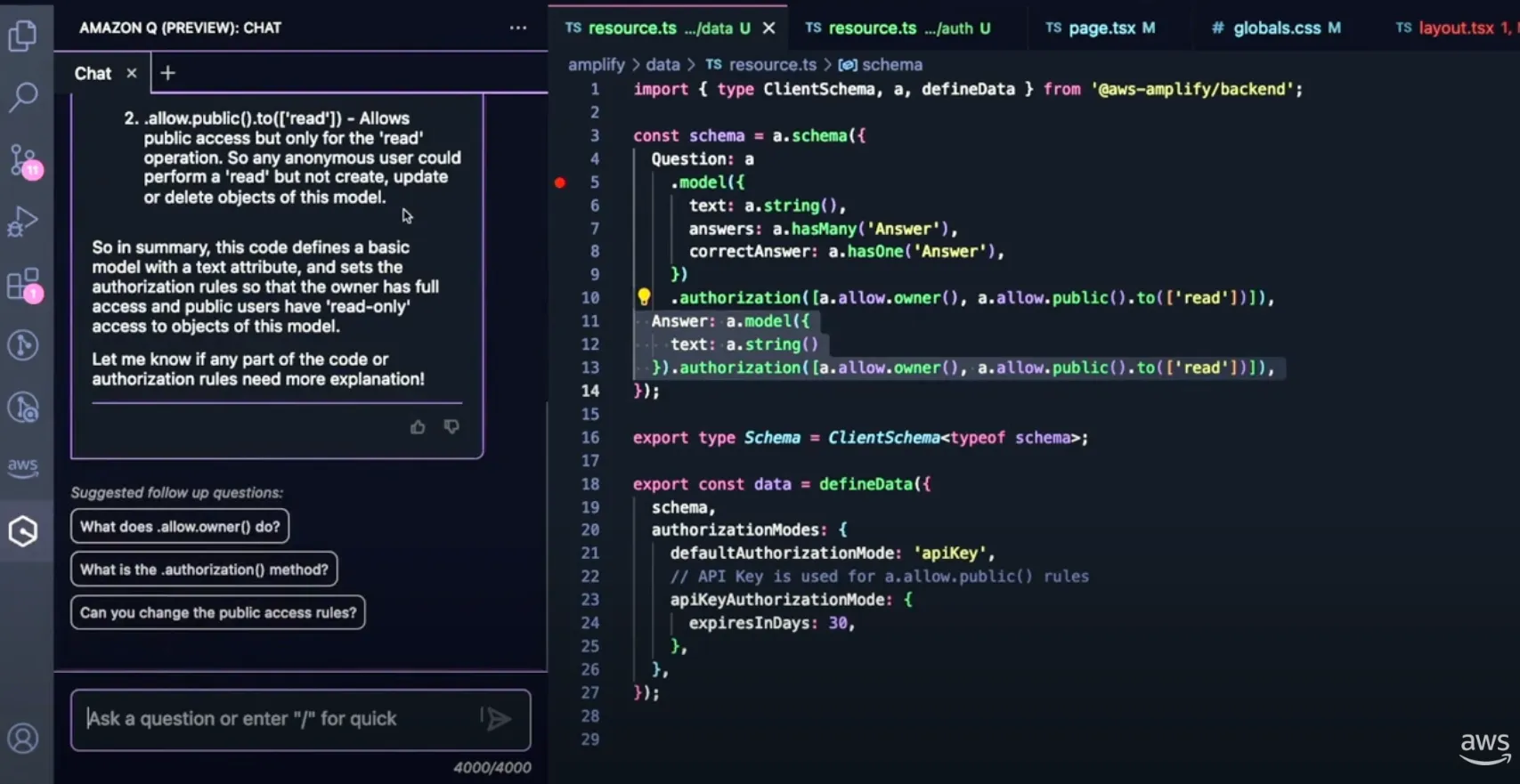
Amazon Q를 통해 개발에 가속화를 더할 수도 있습니다. VScode의 extension으로 Q Chat을 사용할 수 있으며 Amplify 코드 라인에 대한 설명을 질문하면 이 코드가 수행하는 작업이 무엇인지 설명해 줍니다. 위의 예시의 경우 데이터 모델과 인증 규칙에 대한 부분을 Q Chat이 설명해 주는 것을 볼 수 있습니다.
이 밖에도 패스워드 변경 컴포넌트, 사용자 삭제 컴포넌트와 같은 UI 컴포넌트가 새롭게 추가되었고 로그인이나 가입 등의 워크플로우가 포함된 pre-built UI 컴포넌트 등을 제공하여 개발자 경험과 개발 속도 향상에 도움을 줍니다.
Ship with confidence
Fullstack Git-Based Deploys
Amplify Gen2에서는 git 기반으로 백엔드부터 프론트엔드까지 풀스택 배포를 진행할 수 있게 됩니다.
코드 우선 중심의 컨셉에 따라 별다른 설정 없이 git branch가 1:1로 배포 환경과 매칭되는데요. 풀스택 환경을 설정하기 위해 CLI나 콘솔에서 여러 단계를 구성해야 했던 이전 버전과 다르게 Gen2의 제로컨피그 컨셉은 개발자가 git repository만 잘 관리한다면 큰 어려움을 겪지 않고도 배포를 할 수 있어 보였습니다. 데모를 통해 git과 Amplify가 서로 연동되어 git push가 일어날 때마다 풀스택 배포가 진행되는 모습을 확인할 수 있었는데요. 개인적으로 사이드 프로젝트에서 진행했던 remix app을 vercel을 이용해 배포해 보았을 때와 비슷한 경험이라고 느꼈습니다.
프론트엔드 git repository는 서비스의 성격에 따라 monorepo로 구성할 수도 있는데요. Gen2뿐만 아니라 Gen1에서도 yarn workspace나 NX로 구성된 monorepo의 호스팅을 완벽하게 지원합니다.
Host Any SSR Apps
프론트엔드에서는 CSR(Client Side Rendering), SSR(Server Side Rendering), SSG(Static Site Generation) 등 여러 가지 렌더링 전략으로 서비스를 개발하고 배포할 수 있습니다. 이전 버전까지는 SSR 렌더링 전략을 사용하는 대표적인 프레임워크인 next.js만 배포가 가능했었는데요, 이제는 모든 SSR 프레임워크에 대해 없이 호스팅이 가능해졌습니다. 이미 최신 버전의 Nuxt app은 Amplify 지원을 제공하고 있는데요. 평소 SSR 렌더링 전략에 관심을 많이 가지고 있는 저에게는 next.js에 국한되지 않고 여러 SSR 프레임워크에 대한 호스팅이 가능하다는 점이 매력적으로 다가왔습니다.
Scale
애플리케이션을 개발하고 호스팅 한 후 어떤 부분을 더 해볼 수 있을까요? 바로 확장 가능성에 대한 이야기를 빼놓을 수 없을 것 같은데요. Amplify Gen2는 Amazon CDK(Cloud Development Kit) 위에서 완전하게 구축되어 있어 다른 AWS 서비스들로의 확장이 쉽다는 점을 강조하고 있습니다. 만약, 서비스를 구성하다가 지도나 지오펜싱과 같은 위치와 관련된 기능에 대한 구현이 필요하다면 다음과 같이 코드를 추가하는 것만으로 AWS Location Service 리소스를 할당받을 수 있고 서비스를 확장해 나갈 수 있습니다.
import { CfnOutput, Stack, StackProps } from 'aws-cdk-lib';
import * as locations from 'aws-cdk-lib/aws-location';
import { Construct } from 'constructs';
export class LocationMapStack extends Stack {
constructor(scope: Construct, id: string, props?: StackProps) {
super(scope, id, props);
// Create the map resource
const map = new locations.CfnMap(this, 'LocationMap', {
configuration: {
style: 'VectorEsriStreets', // map style
},
description: 'My Location Map',
mapName: 'MyMap',
});
new CfnOutput(this, 'mapArn', {
value: map.attrArn,
exportName: 'mapArn',
});
}
}지금까지 Amplify에 신규로 추가된 기능들과 함께 애플리케이션을 개발하고 배포 및 호스팅 하고 확장하는 흐름에 대해서 간략하게 살펴보았는데요. 무엇보다도 인상적이었던 부분은 코드 우선 중심으로 개발자 경험을 향상했다는 점과 제로컨피그 컨셉으로 배포와 호스팅에 큰 시간을 들이지 않고 서비스를 빠르게 빌드하고 구축할 수 있다는 점이었습니다. 그리고 여러 세션에 참여하면서 Amplify팀이 어떠한 고민으로 개발자 및 사용자 경험을 개선시키려고 했는지 느낄 수 있었습니다.
개인적으로는 실무에 어떻게 활용해 보면 좋을지 생각해 보는 시간도 가져보았는데요. 아직 Amplify를 실무에서 사용해 본 적은 없지만 빠른 서비스 프로토타이핑이 필요하거나 백엔드 도움 없이 빠른 서비스 구축이 필요할 경우 사용해 보면 좋겠다는 생각이 들었습니다. 앞으로 고도화될 Amplify 서비스가 매우 기대되고 이번 세션들에서 여러 인사이트를 얻을 수 있어서 값진 경험이었습니다.
마치며
AWS re:Invent 2023은 5개의 호텔에서 진행되었는데요. 라스베가스에서 위치한 각 호텔들의 규모가 굉장히 커서 많은 세션들이 동시에 진행될 수 있었어요. 이러한 큰 규모의 행사에 전 세계의 다양한 사람들과 함께하며 같이 호흡한다는 것만으로도 좋은 경험이 아니었나 생각됩니다. 추후 해당 행사에 참여하실 분들은 호텔 간의 거리와 이동 시간을 잘 체크하시고 세션 참여 계획을 잘 세우시길 바랍니다. Expo(업체 부스)에 참석하면 트렌드 파악에도 도움이 되니 참석하셔서 각 회사들의 이야기를 듣는 것도 추천드려요!
이상으로 공동 저자 셜록과 클로이의 AWS re:Invent 2023 관심주제인 Aurora DB와 Amplify를 살펴보았는데요, 저희가 정리한 내용들이 해당 주제들에 관심이 있으신 분들께 조금이나마 도움이 되었으면 좋겠습니다.
2편 내용이 궁금하신 분들께서는 아래 바로가기를 확인해 주세요!
👉🏻 AWS re:Invent 2023, 관심 세션을 중심으로 (2편): Cost Optimization, Observability 바로가기
개인별 경험 공유
sherlock.hoons (Aurora DB)
저는 Chalk Talk 세션이 너무 재미있었어요. 회사에서도 화이트보드 앞에 모여 앉아 아이디어를 공유하고 토론하는 것을 좋아하는데요, AWS 행사에서 여러 국적의 엔지니어들과 모여 앉아 서로의 관심사를 공유하는 경험이 너무 좋았습니다. 외국인들은 고가용성(four nines, five nines availability)에 대한 질문을 많이 한다는 것도 흥미로웠어요 :)
chloe.ykim (Amplify)
감사하게도 좋은 기회가 주어져서 이번 행사에 참가할 수 있었는데요. 배지 픽업, 키노트, 각 호텔에서 열리는 세션들, expo 등의 참여 하나하나가 매우 흥미롭고 재미있었습니다. 여러 행사들을 참석하면서 IT업계의 트렌드나 관심이 어디에 쏠려 있는지 느낄 수도 있었어요. 개인적으로는 AWS 프론트엔드 개발자와 프로덕트 매니저가 프론트엔드 렌더링 전략을 AWS 다양한 서비스들과 어떻게 매칭하여 서비스를 구축할 수 있는지에 대해 화이트보드에 그림을 그려서 설명해 주었던 세션이 매우 인상 깊었습니다. 멋진 크루들과 아름다운 추억들을 쌓을 수 있었음에 다시 한번 감사드립니다!