
요약: 이번 3편에서는 기업 데이터 관점에서 Generative AI와 Google Cloud의 강점을 소개합니다. Generative AI의 이해를 돕기 위해 데이터 유형별 사용 패턴과 Google Cloud의 생태계를 설명합니다. Google Cloud의 다양한 제품과 Generative AI의 시너지로 기업이 데이터를 효과적으로 활용할 수 있는 방법을 강조합니다.
시작하며
안녕하세요. 카카오페이 SRE팀 이든입니다. 저는 카카오페이의 Observability를 담당하고 있으며 장애 탐지, 장애 복구, 재발 방지 등을 위한 업무를 수행하고 있습니다.
앞서 콘텐츠를 작성해 주신 제임스, 데이브 그리고 다음 콘텐츠에 등장할 썬과 함께 라스베가스에서 열린 Google Cloud Next 2024에 참관하였는데요. 컨퍼런스 중간에 문득 대부분의 세션이 Google Cloud의 Generative AI(생성형 AI)의 모델인 Gemini를 활용하여 기업의 데이터를 분석하고 가치를 창출해 내기 위한 방법을 소개하고 있다는 생각이 들었습니다. 그리고 평소에 생각해보지 못했던 기업이 가진 데이터를 Generative AI에서 활용하려면 어떻게 해야 되는지, 그 과정에서 Google Cloud가 어떤 강점을 가질 수 있을지에 대한 궁금함이 생겼습니다.
따라서 이번 포스팅에서는 기업 데이터 관점에서 바라본 Generative AI, Google Cloud가 가진 강점에 대한 개인적인 생각 그리고 인상 깊었던 컨퍼런스 세션을 공유해보려고 합니다. 평소 Generative AI에 큰 관심이 없던 제가 Generative AI에 대해 하나씩 이해하고 정리해 나가는 과정에 따라 작성한 글이기 때문에 이미 전문적인 지식을 가진 분들에게는 도움이 되지 않을 수도 있습니다. 하지만 저와 비슷한 연차 혹은 저처럼 Generative AI가 아직은 생소한 분들에게 조금이나마 도움이 됐으면 좋겠습니다.
기업 데이터 관점에서 Generative AI 이해하기
기업 데이터 관점에서 Generative AI를 이해하기 위해 개인적으로 가장 도움이 됐던 방법은 데이터를 성격에 따라 분류하고, 데이터 유형 별로 Generative AI 사용 패턴을 정리해 보는 것이었습니다.
데이터 형태(format)에 따른 분류와 Generative AI 사용 패턴
먼저 데이터는 형태에 따라 정형 데이터(structured data), 반정형 데이터(semi-structured data), 비정형 데이터(unstructured data)로 분류됩니다. Generative AI Application 중에서 가장 범용적으로 사용되고 있는 ChatGPT-4o를 통해 각 데이터 형태의 정의와 대표적인 저장소를 알아보겠습니다.
| 형태 | 설명 | 예시 | 대표 저장소 |
| :-----------: | ------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------- | ---------------------------------------------------- |
| 정형 데이터 | 고정된 필드나 형식을 갖춘 데이터로, 테이블 형식으로 저장되고 체계적으로 관리할 수 있음. | 관계형 데이터베이스 테이블
예: 고객 정보 테이블 | MySQL, PostgreSQL, Oracle |
| 반정형 데이터 | 고정된 스키마가 없지만, 태그나 다른 마커를 사용하여 구조화된 정보를 포함하는 데이터. | JSON, XML
예: JSON {"id": 1, "name": "홍길동", "age": 30, "email": "hong@example.com"} | MongoDB, CouchDB, Elasticsearch |
| 비정형 데이터 | 고정된 구조가 없는 데이터로, 텍스트 문서, 이미지, 비디오, 로그 파일 등 다양한 형식을 포함. | 텍스트 문서 (워드 문서, PDF 파일)
미디어 파일 (이미지, 비디오, 오디오)
로그 파일 (서버 로그, 애플리케이션 로그)
이메일 본문 | MySQL, PostgreSQL, Oracle | Hadoop HDFS, AWS S3, Apache Cassandra, Elasticsearch |
일상에서 Generative AI를 사용할 때 사용자는 주로 데이터를 제공하지 않고 질문만 하거나, 제공하더라도 소량의 비정형 데이터가 주를 이룹니다. 텍스트 파일의 내용을 복사-붙여넣기 하여 요약해 달라는 것과 숫자를 제공한 뒤 계산해 달라는 것 모두 비정형 데이터를 제공한 케이스에 해당합니다. Generative AI는 학습을 통해 이미 알고 있는 지식과 사용자가 제공한 데이터를 활용하여 응답합니다. 일상에서는 비정형 데이터를 주로 다루기 때문에, 이러한 Generative AI 사용 패턴은 어떻게 보면 매우 당연합니다.
반면 기업에서는 정형 데이터, 반정형 데이터, 비정형 데이터 모든 형태의 데이터를 다룹니다. 정형 데이터와 반정형 데이터를 Generative AI에 제공하려면 어떻게 해야 할까요? 정형 데이터와 반정형 데이터는 스키마와 함께 저장되어 사용되는데, 스키마와 데이터를 같이 넣어주어야 할까요? 스키마 문제뿐만 아니라 제공해야 하는 데이터의 양도 일상에서와는 비교할 수 없이 크기 때문에 당연히 Generative AI 사용 패턴도 달라집니다. 더 이상 복사-붙여넣기 만으로는 Generative AI에 필요한 데이터를 제공할 수 없습니다.
데이터 변동성(volatility)에 따른 분류와 Generative AI 사용 패턴
데이터 변동성에 따라 사용 패턴을 알아보는 것도 기업 데이터 관점에서 Generative AI를 이해하는데 도움이 됩니다. 데이터는 변동성에 따라 정적 데이터(static data), 동적 데이터(dynamic data)로 분류됩니다. ChatGPT-4o는 정적 데이터와 동적 데이터를 아래와 같이 정의하고 있습니다.
| 정적 데이터 (Static Data) | 동적 데이터 (Dynamic Data) | |
|---|---|---|
| 정의 | 변하지 않거나 자주 변경되지 않는 데이터를 의미합니다. 사전에 수집되고 처리된 후, 모델의 훈련 과정에서 사용되어 그 내용이 모델 파라미터에 고정적으로 인코딩 됩니다. | 시간이 지남에 따라 자주 변하거나 업데이트되는 데이터를 의미합니다. 새로운 정보나 최신 트렌드, 뉴스 사건 등을 포함할 수 있습니다. |
| 특징 | 시간에 따라 내용이 바뀌지 않으므로, 한 번 모델에 학습되면 해당 정보는 모델 업데이트가 이루어지기 전까지 변경되지 않습니다. | 지속적으로 업데이트가 필요하며, 동적 데이터를 기반으로 모델을 훈련시키거나 파인 튜닝하는 작업은 주기적으로 이루어져야 합니다. |
| 예시 | 역사적 사실, 고전 문학 작품, 일반적인 언어 규칙 등. 이러한 정보는 시간이 지나도 그 자체로 변하지 않으며, 모델이 이러한 정보를 학습하는 데 유용합니다. | 최신 뉴스 기사, 주식 시장 데이터, 소셜 미디어 트렌드 등. 이러한 정보는 매우 빠르게 변화하므로, 모델이 최신 상태의 정보를 반영하도록 지속적으로 업데이트해야 합니다. |
Generative AI는 학습 기반이기 때문에 동적 데이터보다 정적 데이터를 다루는데 훨씬 유리합니다. 동적 데이터의 범주에는 학습 이후에 만들어진 최신 데이터도 포함됩니다. Generative AI는 동적 데이터와 관련된 질문을 처리할 때 주로 외부 저장소에 의존합니다. 예를 들어 ‘2023 롤드컵 우승 팀이 어디야?‘라는 질문에 Generative AI는 바로 응답하지 못하고 외부 저장소(웹 사이트 등)에 검색을 실행합니다. 만약 외부 저장소에 원하는 데이터가 업데이트되어있지 않거나 Generative AI가 업데이트된 데이터를 응답하지 못한다면 사용자는 올바른 응답을 받을 수 없습니다.
일상에서는 올바른 응답을 받지 못하더라도 크게 문제가 되지 않습니다. 어차피 Generative AI의 답변을 중요한 곳에 사용하지 않기 때문입니다. ‘역대 롤드컵 우승팀 미드라이너 평균 나이가 어떻게 돼?‘라는 질문에 Generative AI가 대답을 못하거나 부정확한 결과를 생성하더라도 사용자의 호기심을 충족시켜주지 못했을 뿐입니다. 반면 기업에서는 동적 데이터를 대상으로도 정확한 응답을 요구합니다. Generative AI의 답변이 마케팅 전략 등 중요한 의사 결정의 기준으로 활용되기 때문입니다. 따라서 연동된 저장소는 항상 최신 데이터를 유지할 수 있어야 하고, Generative AI에서도 해당 저장소에 있는 모든 데이터를 실시간으로 이해할 수 있어야 합니다.
Generative AI에 기업 데이터 연동하기
그렇다면 어떻게 이러한 Generative AI 사용 패턴을 모두 만족시키면서, 기업의 데이터를 활용할 수 있을까요?
SaaS로 이용하는 제품을 제외하면 보통 기업은 데이터 저장소를 직접 운영하고 있습니다. 여기서 ‘직접 운영한다’라는 표현은 퍼블릭/프라이빗 클라우드 구분 없이 데이터 저장소의 엔드포인트를 가지고 있고, 직접 접근할 수 있다는 의미입니다. 다행히 대부분의 Generative AI Application에서는 데이터 저장소를 연동할 수 있는 기능을 제공하는데, 이 기능을 활용하면 간단하게 Generative AI에서 기업의 데이터를 활용할 수 있습니다. 가장 친숙한 ChatGPT에도 MySQL, Mongodb 등의 저장소를 연동할 수 있는 기능이 플러그인 형태로 제공되고 있었습니다. 간단해 보이기도 하고, 텍스트로만 소개하는 것보다 실습 내용으로 전달하는 편이 더 좋을 것 같아 직접 연동해 보았습니다.
실습 1) AskYourDatabase 플러그인으로 Generative AI에 MySQL 데이터 연동해 보기
- 연동할 저장소를 구성하고 테스트 데이터를 생성합니다. (저는 도커를 사용하였습니다.)
| 이름 | 나이 | 국적 | 직업 |
|---|---|---|---|
| James Smith | 34 | USA | Developer |
| Sun Park | 31 | South Korea | Planner |
| Alice Brown | 27 | UK | Developer |
| Laura Müller | 33 | Germany | Engineer |
| Yuki Tanaka | 32 | Japan | Developer |
- AskYourDatabase1 플러그인을 로컬에 다운로드하고, 앞서 만든 저장소를 연동합니다.
- 자연어로 질문하면 SQL로 변환되어 저장된 데이터를 읽고, Generative AI는 질문과 해당 데이터를 조합하여 응답합니다. 하지만 저장소 연동이 되더라도 Generative AI가 문맥을 이해하지 못한다면 SQL을 생성하지 못하거나 제대로 된 응답을 할 수 없습니다.
실습 과정에서 사용된 기술을 SQL Powered RAG2라고 하는데, 동작 과정을 간단하게 요약하면 다음과 같습니다.
- 사용자의 질문 입력
- 사용자의 질문과 연동된 저장소의 메타데이터를 바탕으로 적절한 SQL을 생성
- SQL 쿼리 실행 및 데이터 확보
- 사용자의 질문과 3번에서 확보한 데이터를 함께 Generative AI에 질의
- Generative AI의 응답을 사용자에게 리턴
핵심은 Generative AI에서 기업의 데이터를 활용하기 위해선 기업의 데이터 저장소를 연동할 수 있어야 하며, Generative AI가 전체적인 문맥(사용자의 자연어 질의와 스키마, 데이터 등)을 이해할 수 있어야 합니다.
이론과 실전 사이의 간극
실습 내용만 봤을 땐 모든 것이 간단하고 행복해 보이지만, 언제나 그렇듯 실전에서는 넘어야 할 과제들이 많습니다. 먼저 저장소 연동 측면에서 생각해 보면 기업에서는 매우 다양한 유형의 저장소를 관리하고 있는데 기업에서 사용하는 모든 유형의 저장소를 지원하는 플러그인(Agent라고도 합니다.)을 찾는 것은 어렵습니다. 실습에서 사용한 AskYourDatabase 플러그인만 보더라도 공식 문서 기준으로 PostgreSQL, MySQL, MongoDB, Snowflake 정도만 지원하고 있습니다. 조금 더 나아가서, 만약 모든 타입의 저장소를 하나의 Generative AI에 연동하고 싶다면 어떻게 해야 할까요? AskYourDatabase에서 사용된 SQL Powered RAG는 기술 명칭 그대로 스키마를 가진 정형 데이터 혹은 반정형 데이터를 다루는 데 사용됩니다. 비정형 데이터나 다양한 형식의 데이터를 통합하여 정보를 제공할 때는 RAG3라는 기술이 필요한데, SQL Powered RAG에 비해 상대적으로 복잡하고 적용이 어렵습니다. 무엇보다 기업에서 운영하는 저장소의 수와 데이터의 양 자체도 상당하기 때문에 모든 저장소를 하나하나 연동해 주는 작업은 쉽지 않아 보입니다.
Generative AI의 문맥 파악 관점에서도 간극이 존재합니다. 특정 기업 혹은 도메인에서만 사용하는 용어를 Generative AI에서 이해하지 못한다는 의미입니다. 대표적으로 기업에서 데이터를 저장할 때 흔히 사용하는 축약어도 문맥 파악 문제를 유발하는 원인 중 하나입니다. 만약 테이블 이름이나 컬럼이 축약어로 구성되어 있다면 단순히 연동하는 것만으로 Generative AI가 기업의 데이터를 활용할 수 있을까요? 실패하는 케이스도 직접 확인해 보고 겸사겸사 Generative AI Application framework로 유명한 langchain4도 써볼 겸 축약어로 구성된 테이블을 만들고 langchain을 통해 Generative AI와 연동해 보았습니다.
실습 2) langchain을 활용하여 Generative AI에 MySQL 연동해 보기(feat. 축약어로 인한 실패와 Description을 통한 해결)
- 연동할 저장소와 축약어로 구성된 테스트 데이터를 생성합니다. 저는 ChatGPT-4o에게 통신사에서 사용할만한 축약어로 구성된 테스트 데이터를 만들어달라고 요청했습니다.
| nwk | rsrp | sinr | dlth | ulth | lat | rssi | cqi | mcs | ta |
|---|---|---|---|---|---|---|---|---|---|
| 5G | -95 | 30 | 150.5 | 50.2 | 20 | -80 | 15 | 9 | 50 |
| 4G | -85 | 25 | 100.3 | 30.4 | 35 | -75 | 12 | 7 | 40 |
| 5G | -90 | 28 | 200.1 | 60.3 | 15 | -78 | 14 | 8 | 45 |
| 4G | -80 | 20 | 75.8 | 25.7 | 40 | -70 | 10 | 6 | 35 |
| 5G | -92 | 27 | 180.7 | 55.1 | 25 | -79 | 13 | 8 | 42 |
- API 연동을 위해 API Key를 생성합니다. 저는 gpt-3.5-turbo 모델을 사용했기 때문에, OpenAI API-Key Page에서 Key를 생성했습니다. Billing Page에서 카드 정보를 입력하고, 최소 5$ 크레딧을 충전해야 API Key를 사용할 수 있습니다.(ChatGPT 구독과 별도)
| 카드 등록 | 5$ 크레딧 충전 |
|---|---|
 |  |
- 파이썬 환경을 구성하고 코드를 작성합니다. 제가 테스트에 사용한 코드 전문입니다.
from langchain.utilities import SQLDatabase
from langchain.prompts.chat import HumanMessagePromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain_experimental.sql import SQLDatabaseChain
OPENAI_API_KEY = "{your_api_key}"
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0, api_key=OPENAI_API_KEY)
host = 'localhost'
port = '3306'
username = 'root'
password = 'password'
database_schema = 'google_cloud_next24'
mysql_uri = "mysql+pymysql://root:password@localhost:3306/google_cloud_next24"
db = SQLDatabase.from_uri(mysql_uri, include_tables=['NetworkMetrics'])
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
def retrieve_from_db(query: str) -> str:
db_context = db_chain(query)
db_context = db_context['result'].strip()
return db_context
def generate(query: str) -> str:
db_context = retrieve_from_db(query)
human_qry_template = HumanMessagePromptTemplate.from_template(
"""Input:
{human_input}
Context:
{db_context}
Output:
"""
)
messages = [
human_qry_template.format(human_input=query, db_context=db_context)
]
response = llm(messages).content
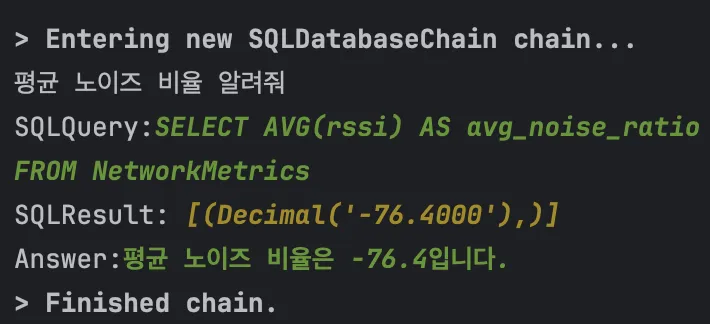
return response
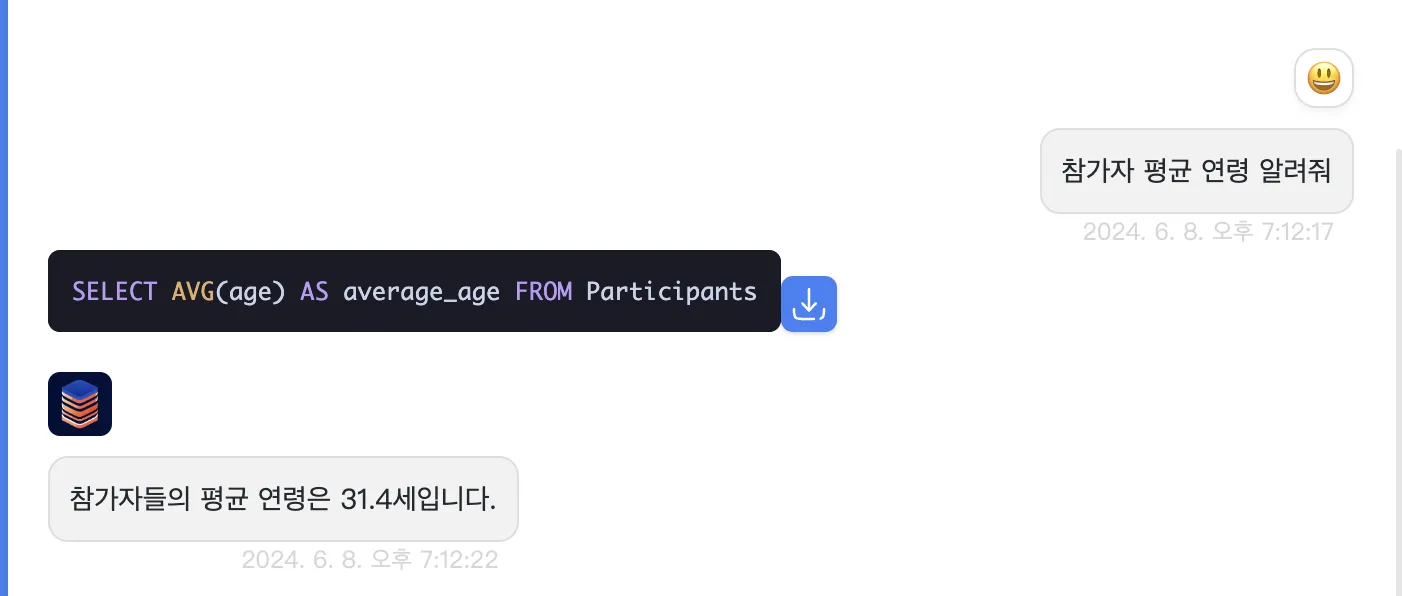
generate("평균 노이즈 비율 알려줘")- sinr 필드의 평균값을 구하기 위해 ‘평균 노이즈 비율 알려줘’라는 질문을 했지만, Generative AI는 이해하지 못하고 rssi 필드의 평균값을 응답하는 모습입니다.
- MySQL의 COMMENT 기능을 활용하여 축약어에 대한 설명을 추가합니다.
ALTER TABLE NetworkMetrics MODIFY nwk VARCHAR(50) COMMENT 'Network Type (e.g., 4G, 5G)';
ALTER TABLE NetworkMetrics MODIFY rsrp INT COMMENT 'Reference Signal Received Power';
ALTER TABLE NetworkMetrics MODIFY sinr INT COMMENT 'Signal to Interference plus Noise Ratio';
ALTER TABLE NetworkMetrics MODIFY dlth FLOAT COMMENT 'Downlink Throughput (Mbps)';
ALTER TABLE NetworkMetrics MODIFY ulth FLOAT COMMENT 'Uplink Throughput (Mbps)';
ALTER TABLE NetworkMetrics MODIFY lat INT COMMENT 'Latency (ms)';
ALTER TABLE NetworkMetrics MODIFY rssi INT COMMENT 'Received Signal Strength Indicator';
ALTER TABLE NetworkMetrics MODIFY cqi INT COMMENT 'Channel Quality Indicator';
ALTER TABLE NetworkMetrics MODIFY mcs INT COMMENT 'Modulation and Coding Scheme';
ALTER TABLE NetworkMetrics MODIFY ta INT COMMENT 'Timing Advance';- 설명을 추가하고 다시 실행해 보니, 동일한 질문에 다른 결과(원래 의도했던 sinr 필드의 평균값)를 받았습니다.

기업의 데이터를 Generative AI에서 사용하는 데 있어서 이론과 실전 사이의 간극에 대해 살펴보고 간단한 실습까지 진행해 보았습니다.
저장소 연동과 Generative AI의 문맥 파악 측면만 고려하더라도, Generative AI에서 기업의 데이터를 제대로 활용하기 위해서는 상당한 수준의 시간과 비용 투자가 필요해 보입니다.
Generative AI in Google Cloud
OpenAI, Facebook 등 다양한 기업에서 Generative AI에 투자하고 있습니다. Google Cloud 행사에 다녀왔으니 경쟁사와 비교해서 기업이 가진 데이터를 활용하는데 Google Cloud만이 가진 강점에 대해 생각해보고 싶었습니다.
Google Cloud가 Next 2024의 Keynote 세션5들을 통해 전달한 내용을 요약하면 다음과 같습니다.
- Gemini 1.5 Pro, Axion 등 신제품 소개 및 성능 측면에서의 강조
- Google Cloud 제품(GCP, GWS6 등)에서 Generative AI(Gemini)를 활용하는 방법과 Best Practice 소개
개인적으로 성능 측면에서는 경쟁사와 비교했을 때 Google Cloud만이 가진 강점을 찾기 어려웠습니다. 다만 Google Cloud가 가진 다양한 자사 제품(GCP, GWS 등)을 바탕으로 기업 데이터를 Generative AI에서 쉽게 활용할 수 있도록 생태계를 구성하는 측면에서는 확실히 유리한 부분이 있다는 생각이 들었습니다. 데이터 활용 측면뿐만 아니라 Google Cloud가 제공하는 Generative AI 생태계에는 직접 구현하거나 오픈 소스에서 찾기 힘든 어려운 기술들에 대한 지원도 포함됩니다. 본 포스팅에서 다룬 SQL Powered RAG, RAG를 포함하여 모델 학습, 파인 튜닝 그리고 대용량 데이터를 다루기 위한 샤딩 등 어려운 기술들을 몇 번의 클릭만으로 혹은 최대한 간단하게 적용할 수 있도록 도움을 주는 제품들을 선보이고 있었습니다. 그리고 이러한 생태계 측면에서의 강점은 기업에게 있어서 Generative AI에서 데이터를 활용하기 위해 투자해야 하는 시간과 비용을 감소시키는 효과와 이어집니다. (기업에서 필요로 하는 기술이 어려워질수록 퍼블릭 클라우드가 유리해지는 것 같다는 생각도 잠깐 해봤습니다.)
실제로 IntelliJ와 같은 Jetbrain 제품을 제외하면 대부분의 세션에서 Google Cloud 자사 제품에 어려운 기술들을 비교적 쉽게 적용하여 기업의 데이터를 Gemini에서 활용할 수 있도록 한 데모를 선보였습니다. 가장 인상 깊었던 데모 두 가지만 간단하게 살펴보고 마무리하겠습니다.
세션 1) Learn how to use Gemini for observability data on Google Cloud
해당 세션에서는 Observability 영역에서 수집되는 데이터를 Gemini에서 활용하는 방법에 대해 소개하고 데모를 보여주었는데요. 제가 Observability를 담당하고 있어서 그런지 유독 기억에 남았습니다.
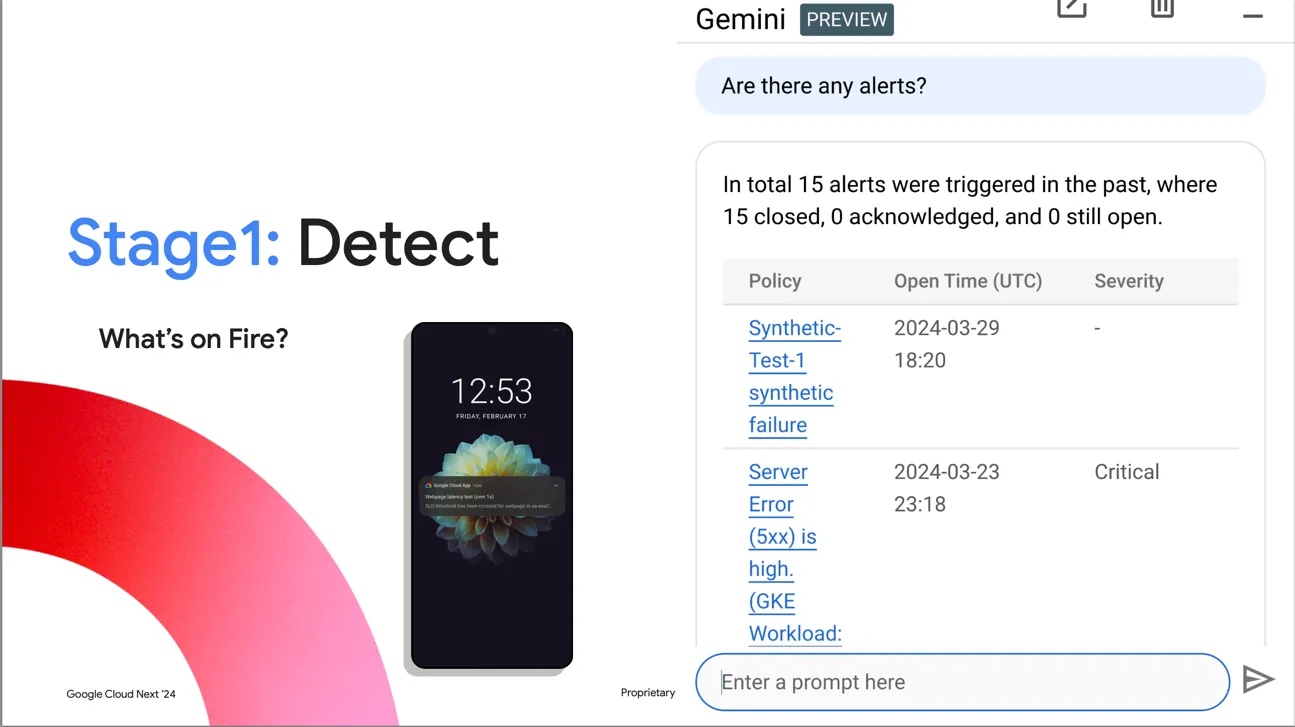
자연어로 질의하니 Gemini가 최근에 울린 얼럿 리스트와 상태를 보여줍니다. 그라파나7 기준으로 생각해 보면 얼럿에 대한 정보는 정형 데이터 저장소에 저장이 되는데, Gemini에 얼럿과 연관된 정형 데이터 저장소만 연동해 주면 SQL Powered RAG 기능을 활용하여 응답을 주는 것이 아닐까 추측해 봅니다.
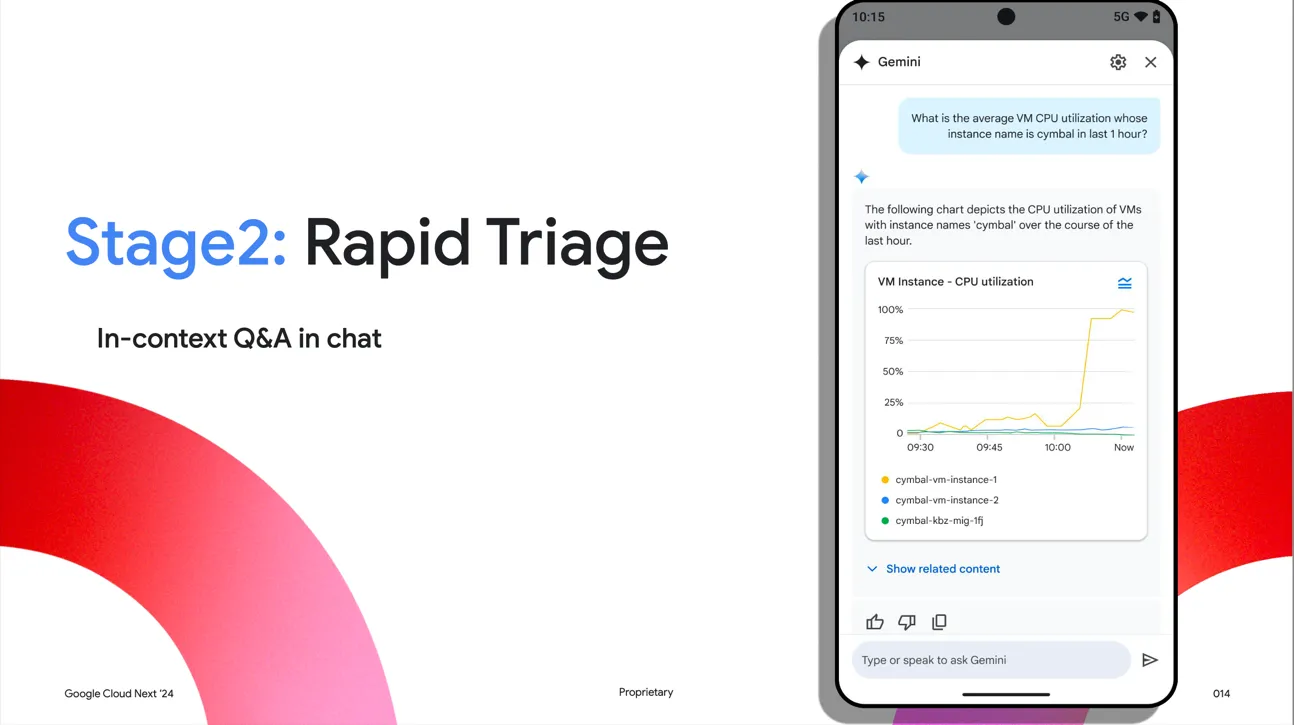
cymbal이라는 이름을 가진 instance의 CPU 사용량을 자연어로 질의하니 Gemini가 그래프를 생성해 주었습니다. Google Cloud에서는 SQL뿐만 아니라 자연어 to PromQL8도 제공한다고 하는데요. Observability 업무를 수행하면서 가장 고민이 많았던 부분이 PromQL의 높은 러닝커브였는데 이 데모만 보면 더 이상 걱정하지 않아도 될 것 같네요.

마지막은 에러 로그가 어떤 의미인지 설명해 달라고 요청했더니 Gemini가 에러 로그에 대해 설명하고, 연결된 Playbook을 에러 로그와 매칭하여 트러블 슈팅까지 진행하고 있습니다. 물론 Playbook을 정의하고 연동하는 부분을 직접 해보면 어려울 것 같긴 하지만 Observability 영역에서 Gemini를 이렇게도 활용할 수 있다 정도를 알게 된 것만 하더라도 굉장히 큰 소득인 것 같습니다.
세션 2) Gemini in Google Meet: Smarter Meetings, Better Outcomes
GWS의 모든 제품에서 Gemini를 기반으로 새로운 기능을 선보였는데, 그중에서 Google Meet의 Take notes for me, Translate for me 기능이 개인적으로 가장 인상 깊었습니다.
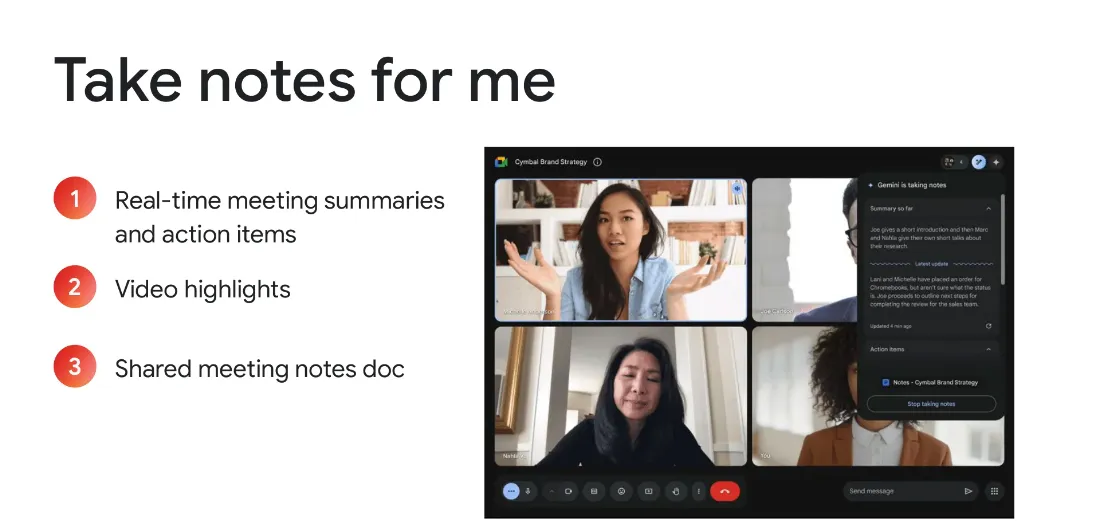
Gemini가 회의 내용을 자동으로 기록하고 요약해 주는 기능입니다. (이 기능을 사용해 보기 위해서라도, 재택을 해봐야 되는 걸까요?)
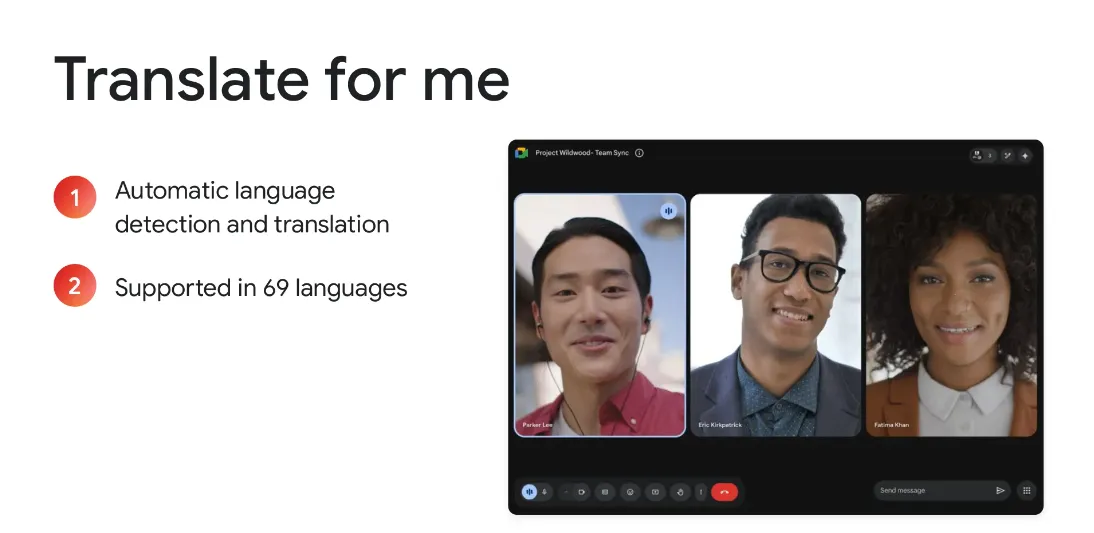
Gemini가 자동으로 언어를 식별하고 번역해 줍니다. 현재 약 70개의 언어를 지원한다고 하는데, 한국어도 포함이 되어있습니다. (이제 영어 때문에 구글 안 가는 거다라는 말도 안 통하겠군요..)
마치며
실습과 데모를 포함해서 기업의 데이터를 Generative AI에서 활용하는 방법과 Google Cloud가 가진 강점에 대한 생각을 정리해 보았습니다. 사실 기업의 데이터라는 표현보다도 Generative AI가 학습하지 못한 내가 가진 모든 데이터라는 표현이 더 적절해 보이기도 합니다. Generative AI를 그냥 사용하는 것과 내가 가진 데이터를 제공하며 사용하는 것은 완전히 다릅니다. 예를 들어 Generative AI를 이용하여 코드를 작성할 때에도, 그냥 코드를 작성해 달라고 요청하는 것과 Generative AI에 프로젝트 전체 코드의 맥락을 이해시킨 뒤 요청하는 것은 응답 퀄리티, 사용성 등 모든 측면에서 비교할 수 없을 만큼 차이가 발생합니다. 개인적으로 이 글을 통해 Generative AI에 익숙하지 않은 분들이 이러한 차이에 대해 인지하게 되고, Generative AI에 조금이나마 더 익숙해지는 계기가 됐으면 좋겠습니다.
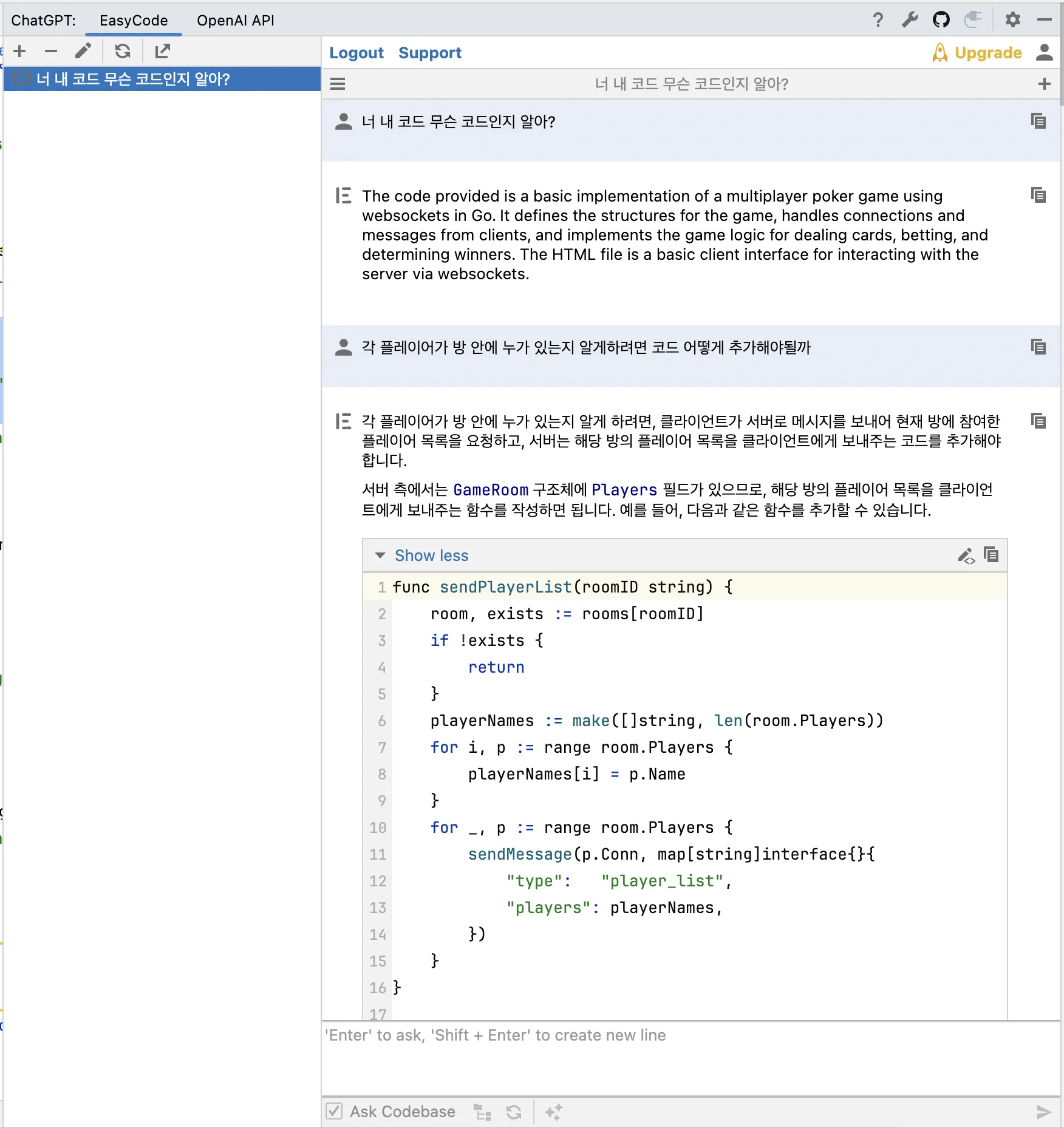
기업 데이터에는 우리가 회사에서 작성하는 코드도 포함됩니다. Ask Codebase 기능을 활용하여 Generative AI에 전체 코드 데이터를 주입해 주었습니다. 주입된 코드 데이터를 통해 Generative AI가 이미 프로젝트 전체 코드의 맥락을 이해하고 있기 때문에, 질의를 할 때 따로 코드를 붙여 넣거나 설명해주지 않아도 됩니다. 답변의 퀄리티와 사용성이 비약적으로 높아집니다.
요약
- 데이터를 적절하게 분류하고 사용 패턴을 정리해 보는 것은 Generative AI를 이해하는데 큰 도움이 됩니다.
- Generative AI에서 기업 데이터를 활용하기 위해선 저장소를 연동할 수 있어야 하며, Generative AI가 질문과 데이터에 대한 맥락을 이해할 수 있어야 합니다.
- 저장소 연동, Generative AI의 질문과 데이터에 대한 맥락 이해 모두 이론과 실전 사이의 간극을 채우기 위한 기업의 시간과 비용 투자가 필요합니다.
- Google Cloud는 GCP, GWS 등 자사의 다양한 제품과 Generative AI의 시너지를 통해 기업이 Generative AI에서 데이터를 활용하기 위해 투자해야 되는 시간과 비용을 줄일 수 있는 생태계를 구성하는데 강점을 갖는 것 같습니다.
- Generative AI를 그냥 활용하는 것과 내가 가진 데이터를 제공하며 사용하는 것은 완전히 다릅니다.
맺음말
저는 해외에 나갈 때 치안을 제일 중요하게 생각해서 미국은 선호도가 낮았고, Late Adaptor 성향이 강해서 Generative AI에도 크게 관심이 없었습니다. 그래서 처음 Google Cloud Next 2024에 가게 되었다는 소식을 들었을 때 어떻게 하면 안 갈 수 있을지 일주일 넘게 고민했던 것 같습니다. (저희 팀장님이 저의 이런 성향을 잘 알고 계셔서 저에게 안 좋은 소식이 있다면서 말씀해 주셨던 게 기억에 남네요…)
하지만 라스베가스는 생각보다 훨씬 안전했고, AI를 포함한 라스베가스에서 경험한 다양한 기술들은 지금 당장 트렌드를 쫓기 시작하더라도 너무 늦었다는 생각이 들었을 정도로 매우 빠르게 변화하고 있었습니다. 몇 년 동안 가지고 있던 저만의 고정관념들이 일주일도 채 안 되는 시간에 바뀐다는 것이 너무 신기했고 이번 출장을 통해 얻은 가장 큰 소득이라고 생각하고 있습니다. 덕분에 귀국 후 지금이라도 Generative AI 생태계를 따라가 보자라는 방향성을 설정했습니다. 어려운 분야라 이해가 쉽지는 않지만 langchain, RAG 등을 활용하여 저만의 Generative AI Application을 만들어보고 있습니다.
개인적으로 저처럼 주니어에서 시니어로 넘어가는 과정에 있는 개발자 분들은 자신과 연관이 없거나 선호하지 않는 분야라 하더라도 이런 기회가 주어진다면 꼭 한 번 경험해 보셨으면 좋겠고, 회사에서도 이런 기회를 많이 제공해주었으면 하는 마음을 끝으로 글을 마치겠습니다.
참고자료
- https://medium.com/@shivansh.kaushik/talk-to-your-database-using-rag-and-llms-42eb852d2a3c
- https://assets.swoogo.com/uploads/3784351-66186b07c3c68.pdf
- https://assets.swoogo.com/uploads/3771525-6615c5799a90e.pdf
Footnotes
-
AskYourDatabase는 SQL 지식이 없는 사용자도 데이터베이스와 쉽게 상호작용할 수 있도록 설계된 플러그인입니다 ↩
-
대형 언어 모델이 구조화된 데이터베이스에서 SQL 쿼리를 통해 관련 정보를 검색하여 응답 생성을 보조하는 기술입니다. ↩
-
Retrieval-Augmented Generation의 약자로, 외부 데이터베이스에서 관련 정보를 검색하여 대형 언어 모델의 응답 생성을 보조하는 기술입니다. ↩
-
대형 언어 모델(LLM)과 API, 데이터베이스 등을 연결하여 복잡한 언어 처리 작업을 자동화하는 프레임워크입니다. ↩
-
1일 차 Opening Keynote: The new way to cloud, 2일 차 Developer Keynote: Fast. Simple. Cutting dege. Pick three. ↩
-
Google Workspace로 Gmail, Meet, Drive 등을 포함한 구글의 클라우드 기반 생산성 및 협업 도구 모음입니다. ↩
-
다양한 데이터 소스의 데이터를 시각화하고 모니터링할 수 있는 오픈 소스 대시보드 및 그래프 편집 도구입니다. ↩
-
Prometheus 데이터베이스에서 시계열 데이터를 쿼리하기 위해 사용되는 쿼리 언어입니다. ↩



