시작하며
안녕하세요, 카카오페이 머신러닝 엔지니어 카일입니다.
카카오페이 데이터 프로덕트 팀에서는 얼굴 인식, OCR(Optical Character Recognition) 등의 기술을 활용하여 여러 서비스를 실시간으로 제공하고 있습니다. 서비스 목적에 따라 다양해지는 모델과 높아지는 서비스 요구사항(낮은 지연시간과 높은 처리량)을 반영하기 위해 효율적인 모델 서빙1 프레임워크의 도입을 고민했습니다.
본 포스팅에서는 카카오페이 상황에 맞는 최적의 모델 서빙 프레임워크 선정을 위하여 프레임워크들을 비교하고, 선정된 프레임워크의 서빙 성능 최적화를 위해 다양한 기능을 테스트한 결과를 공유해 드리려고 합니다. 테스트 결과는 모델 서빙 프레임워크를 도입하고자 하는 분들에게 좋은 벤치마킹 데이터가 되리라 생각합니다. 😊
기존 카카오페이에서의 모델 서빙은?
카카오페이에서 제공하는 여러 딥러닝 모델 중 얼굴 인식에 활용하는 모델을 예시로 설명을 드리려 합니다.
모델 서빙 구성
기존에는 각 개발 영역에서의 생산성을 위해 모델 개발을 하는 머신러닝 리서처는 파이썬을 이용했고, 모델을 서빙하는 백엔드 개발자는 코틀린+스프링부트로 직접 서버를 개발했습니다. 이는 각 엔지니어들의 개발 생산성은 높였지만 아래와 같은 어려운 점들이 있었습니다.
- 파이썬 기반의 모델 전/후처리 코드를 코틀린으로 변환하는 과정에서 추가적인 개발이 필요했고, 종종 변환 과정에서 결과의 정합성 이슈가 발생했습니다.
- 다양한 딥러닝 프레임워크(Tensorflow, PyTorch 등)로 개발된 모델은 정합성의 차이가 허용 가능한 선에서 인퍼런스 최적화를 위해 모델이 변환(ONNX, TensorRT 등) 될 수 있고, 최종적으로 모델별 최종 서빙 포맷이 다를 수 있었습니다. 하지만 다양한 포맷의 모델을 서빙하는 것은 개발 생산성, 운영 안정성 측면에서 문제가 있어, 최선의 선택은 아니지만 하나의 포맷으로 통일해서 서빙을 수행해야 했습니다.
- 직접 모델 서빙 서버를 개발할 경우, 서비스 요구사항을 만족시키기 위한 성능 개선과 튜닝 작업에 많은 시간과 비용이 소요되었습니다.
개발 언어 간 변환 과정에서 발생하는 문제점을 해소하기 위해 모델 학습, 개발 및 서빙을 위한 언어를 파이썬으로 통일하기로 결정했습니다. 그리고 모델 서빙 프레임워크를 도입함으로써 나머지 문제점을 해소하고자 했습니다.
모델 인퍼런스 최적화 도입
카카오페이 내 모델은 대부분 Tensorflow 기반으로 학습되었고 모델 서빙에 활용되었습니다. 하지만, Tensorflow 모델만으로는 원하는 수준만큼의 인퍼런스 속도가 나오지 않는 경우도 존재했습니다. 이를 개선하기 위해 모델 인퍼런스 최적화 및 가속화 엔진을 활용하여 최적화된 모델들을 확보했습니다. 대표적으로 알려져 있는 ONNX(Open Neural Network Exchange)와 TensorRT를 활용했습니다.
ONNX는 각기 다른 딥러닝 프레임워크로 학습된 모델을 서로 호환할 수 있도록 해주는 표준 역할을 합니다. Tensorflow, PyTorch 등으로 학습된 모델은 대부분 문제없이 ONNX로 변환할 수 있으며, 변환하는 과정에서 모델의 그래프가 최적화됩니다. ONNX로 변환된 모델은 ONNX Runtime 엔진이라는 고성능 인퍼런스 엔진을 통해 다양한 하드웨어에서 활용될 수 있고, 일반적으로 인퍼런스 성능 개선의 효과를 볼 수 있습니다.
TensorRT는 NVIDIA에서 개발한 모델 최적화 엔진으로, NVIDIA GPU 상에서 기존 대비 인퍼런스 속도를 수배~수십 배까지 향상시킬 수 있습니다. Graph Optimization, Quantization 등의 기법을 이용하여 모델을 최적화하고 실제 서비스에 활용될 하드웨어에 특화된 가속화를 제공합니다.
실제로 저희가 학습한 Tensorflow 모델을 두 최적화 엔진으로 변환 및 인퍼런스 속도를 테스트 수행했을 때, 대체적으로 TensorRT > ONNX > Tensorflow 순서로 속도가 빨랐습니다. 대부분의 기업에서는 NVIDIA GPU를 활용하고 있기 때문에, 하드웨어 가속화까지 수행된 TensorRT 모델의 성능이 좋았던 것이죠.
하지만 Tensorflow 모델을 ONNX, TensorRT로 변환 시 속도와 함께 정합성 또한 고려해야 합니다. TensorRT의 경우 지원하지 않는 Operation과 Layer들이 존재하며, 모델 구조에 따라서는 정합성이 맞지 않는 경우도 존재했습니다. 이를 해결하기 위해서는 지원하지 않는 Operation을 직접 개발하여 추가하거나 호환되는 Operation의 조합으로 대체하도록 모델 구조의 수정이 필요하지만 이는 상당한 공수가 들어가는 작업이었습니다.
결론적으로 인퍼런스 최적화 작업은 인퍼런스 속도와 정합성 모두를 고려해야 했으며, 이로 인해 모델별 최적의 포맷은 각각 달랐습니다. 예를 들면 Tensorflow 모델을 ONNX 또는 TensorRT로 변환하여 인퍼런스 속도를 개선하더라도, 모델의 정합성이 서비스 특성에 따라 정의된 임계치를 벗어난다면 속도를 희생하더라도 변환 없이 Tensorflow를 사용해야 했습니다. 이렇게 모델별 최적의 포맷이 다른 상황은 여러 개의 모델을 서빙하는 인공지능 서비스에서 개발 생산성 저하와 운영의 부담을 가중시키게 됩니다. 실제로 실무에서는 개발 및 운영의 효율성을 위해 최적은 아니지만 하나의 포맷으로 통일하여 모델 서빙 시스템을 구성하기도 합니다.
모델 서빙 프레임워크 비교
설명해드린 현재 상황에서 모델 서빙 프레임워크들을 비교해보고, 적절한 프레임워크를 선정한 과정을 소개해드리려 합니다.
모델 서빙에 활용할 수 있는 프레임워크는 다양합니다. 아주 간단하게 파이썬 웹 프레임워크를 이용하여 직접 서버를 개발하는 방법도 있고, Tensorflow나 PyTorch에서 제공하는 서빙 프레임워크를 활용하는 방법도 존재합니다. 또는 범용적으로 사용할 수 있는 NVIDIA Triton도 존재하죠.
저희는 모델 서빙 프레임워크를 비교하기 위해 모델은 Tensorflow 모델로 고정하고, 최소한의 기능만 개발하여 테스트를 수행했습니다. 프레임워크 비교 테스트를 수행하면서 아래 세 가지를 요소를 중점적으로 평가했습니다.
- 직접 모델 서빙 서버를 개발하는 것 대비 높은 처리량과 낮은 지연시간
- 모델 서빙 서버의 성능 개선을 위한 최적화 및 튜닝 비용 (시간과 노력)
- 실제 운영할 수 있을 정도의 안정성
비교 후보
위에서 언급한 모델 서빙 프레임워크 중 세 가지를 선정하여 테스트를 수행했습니다.
- FastAPI: 파이썬 웹 프레임워크를 이용한 직접 서버 구축
- Tensorflow Serving: 대부분의 모델이 Tensorflow로 구현되어 있으므로, 이를 그대로 서빙할 수 있는 프레임워크
- Triton: 다양한 딥러닝 모델 포맷을 지원하는 모델 서빙 프레임워크
FastAPI는 최근 각광받는 파이썬 웹 프레임워크 중 하나로, 기존에 많이 사용되던 Flask보다 성능적으로 우수하다고 알려져 있습니다. 본 테스트에서는 FastAPI를 이용하여 Tensorflow 모델을 로드하고 이를 이용하여 이미지 입력이 들어왔을 때, 인퍼런스 하여 결과값을 응답하는 간단한 API를 구현했습니다. 이 방법은 모델 서빙 프레임워크와의 성능 비교를 위한 베이스라인의 역할을 합니다.
Tensorflow Serving과 Triton은 모델만 있다면 직접 서버를 구현하지 않더라도 손쉽게 모델 API를 배포할 수 있는 대표적인 모델 서빙 프레임워크입니다. 해당 프레임워크들은 서빙 성능 개선을 위한 다양한 기능들을 제공하고 있습니다. 두 프레임워크의 가장 큰 차이는 지원하는 모델 서빙 포맷의 종류입니다. Tensorflow Serving은 이름에서도 알 수 있듯이 Tensorflow에서 제공하는 모델 포맷만을 배포할 수 있지만 Triton은 다양한 모델 포맷을 배포할 수 있습니다.
실험 구성
우선 테스트에 사용될 모델에 대해서 간단히 설명드리겠습니다. 현재 카카오페이 얼굴 인식 서비스에서 활용 중인 모델 중 하나로, ResNet50 + alpha로 구성되어 특정 태스크에 대해 Fine-Tuning한 모델입니다. 이미지를 입력받아 분류 결과를 응답하는 이미지 분류 모델 중 하나로 생각하시면 될 것 같습니다.
테스트를 위한 환경은 전부 AWS 클라우드에 구성하였습니다. 위에서 언급드린 세 가지의 모델 서빙 프레임워크의 서버는 AWS Elastic Container Service(ECS)에 구성하였으며, 실제 서비스에서 사용될 GPU 타입인 G4dn instance 타입을 각 서비스마다 동일하게 사용하였습니다. FastAPI로 구성된 서버의 경우, Gunicorn을 이용했으며 Worker를 4개로 설정했습니다. Tensorflow Serving과 Triton의 경우, 모든 기능은 기본값으로 설정하여 서버를 배포했습니다. 테스트 성능 측정에 사용될 클라이언트는 Locust를 이용하여 EC2(M5.2xlarge)에 구축했습니다.
용어 정의
테스트를 수행하기에 앞서, 자주 언급할 용어와 성능 지표에 대해서 정리하도록 하겠습니다.
- User: Locust에서 사용되는 용어로, 요청을 보내는 유저로 생각하시면 됩니다. 유저의 수만큼 클라이언트에서 서버로 동시에 요청을 보내게 됩니다.
- Throughput (RPS: Request Per Second): 초당 서버에서 평균적으로 처리한 요청 수를 의미합니다.
- Latency: 클라이언트에서 보낸 요청이 처리되어 응답받는 데까지 걸린 평균 시간을 의미합니다. 단위는 ms입니다.
프레임워크별 지원 기능 비교
먼저 각 프레임워크가 지원하는 여러 기능에 대해서 살펴보도록 하겠습니다. 프레임워크에서 많은 기능들을 지원하지만, 모델 서빙 관점에서 성능 개선과 운영 시 필요한 기능들 위주로 정리해 보았습니다.
| 프레임워크 | HTTP REST 지원 | gRPC 지원 | 지원하는 모델 포맷 | Concurrent Model Execution | Dynamic Batch Inference | 로깅 | 모델 버저닝 | 모델 관리 | 프로메테우스 모니터링 |
|---|---|---|---|---|---|---|---|---|---|
| FastAPI | O | 구현 필요 | 구현 필요 | 구현 필요 | 구현 필요 | 구현 필요 | 구현 필요 | 구현 필요 | 구현 필요 |
| Tensorflow Serving | O | O | Tensorflow | X | O | O | O | O | O |
| Triton | O | O | Tensorflow, PyTorch, ONNX, TensorRT, OpenVINO, TorchScript | O | O | O | O | O | O |
FastAPI는 기본적으로 파이썬 웹 프레임워크입니다. 위 체크리스트는 모델 서빙 프레임워크 기능들에 초점을 맞추다 보니, 대부분이 해당사항이 없었습니다. 물론 직접 구현을 통해 기능을 만들 수 있지만 개발에 대한 비용과 유지보수에 대한 비용이 클 수밖에 없습니다.
FastAPI와 다른 두 프레임워크와의 기능상 가장 큰 차이는 Dynamic Batch Inference 지원 여부입니다. 해당 기능은 모델 서빙 속도에 가장 큰 영향을 미치는 기능 중 하나이지만, FastAPI의 경우 기본적으로 지원되지 않는 부분입니다.
Tensorflow Serving과 Triton의 가장 큰 차이는 표에서 볼 수 있듯이, 지원하는 모델 포맷의 종류입니다. 아래는 Triton의 구조를 간략히 보여주는 그림입니다.2
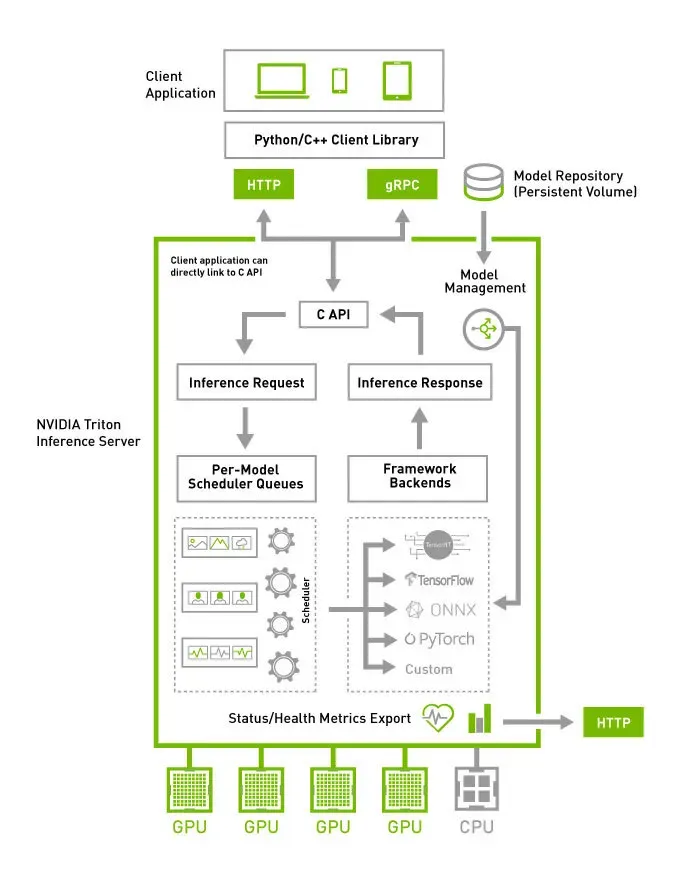
Triton은 여러 가지 딥러닝, 머신러닝 모델을 실행할 수 있도록 랩핑(wrapping)한 구조로 벡엔드가 구성되어 있습니다. 그렇기에 Tensorflow 이외에도 여러 모델 포맷을 지원할 수 있고, 이는 Tensorflow에서 학습된 모델 포맷만을 지원하는 Tensorflow Serving과의 가장 큰 차별점입니다.
모델 서빙 성능 비교
우선 HTTP 프로토콜에서의 세 가지 프레임워크의 모델 서빙 성능을 비교했습니다.
Locust를 이용하여 동등한 조건하에서 동기 방식(Synchronous)으로 각 서버에 요청을 보냈을 때, 각 프레임워크가 처리할 수 있는 최대 RPS와 Latency를 확인했습니다. Locust의 User 수는 20으로 수행하고, 각 User는 서버로 초당 10개의 요청을 보내도록 설정했습니다. Locust 클라이언트에서 요청을 보내는 방식은 각 프레임워크에서 공식적으로 제공하는 예제 코드를 참고했습니다. (Tensorflow Serving 예제 코드, Triton 예제 코드)
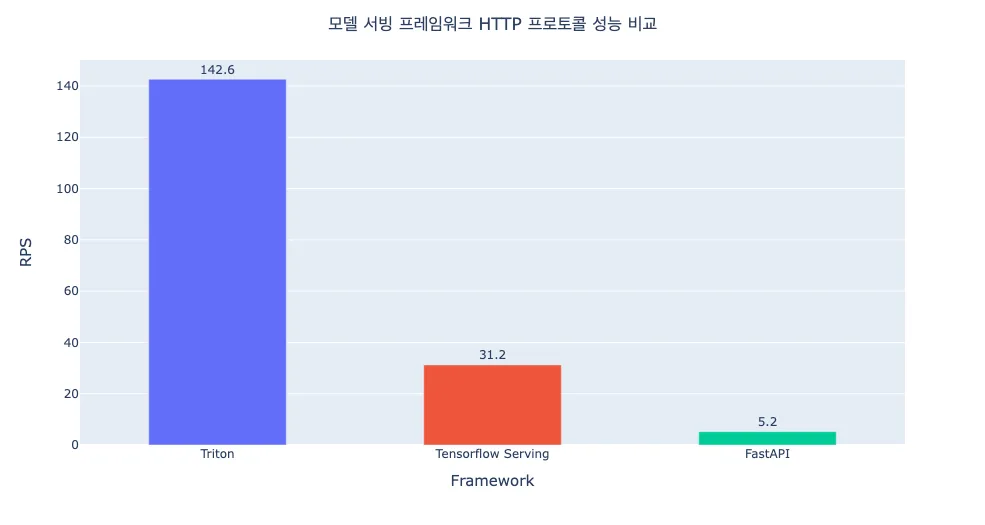
결과에서 알 수 있듯이, 성능은 Triton > Tensorflow Serving > FastAPI 순으로 좋은 것을 알 수 있습니다. 모델 서빙 프레임워크인 Tensorflow Serving과 Triton에서 큰 성능 차이가 발생하는 원인은 요청을 보내는 방식에 있습니다. Tensorflow Serving은 이미지 Tensor를 JSON 형태 그대로 전송하지만, Triton에서는 이미지를 바이너리 데이터로 변환하고 이를 Base64로 인코딩해서 전송합니다. 두 방식의 차이로 네트워크 오버헤드의 큰 차이가 발생했고 이것이 각 프레임워크 성능의 차이를 야기했습니다.
물론 Tensorflow Serving에서도 Base64 인코딩을 수행하여 이미지를 전송(코드)할 수 있지만, 이를 위해서는 모델 자체의 Input Signature가 변경되어야 하며, 이는 곧 모델의 변경이 필요함을 의미합니다. 하지만 Triton에서는 모델 변경 없이 위와 같은 방식이 가능하죠. 저희는 Triton에서 서빙 성능 최적화를 위해 이러한 기능을 제공하고 있음에 주목했습니다. 마찬가지로 FastAPI의 경우에도 모델 변경 없이 수행했기 때문에 이미지 Tensor를 JSON 형태 그대로 요청을 받았지만 모델 서빙 프레임워크만큼 최적화된 코드 구현이 이뤄지지 않았기 때문에 속도가 제일 느릴 수밖에 없었습니다.
그렇다면 gRPC 프로토콜에서는 결과가 어떨까요?
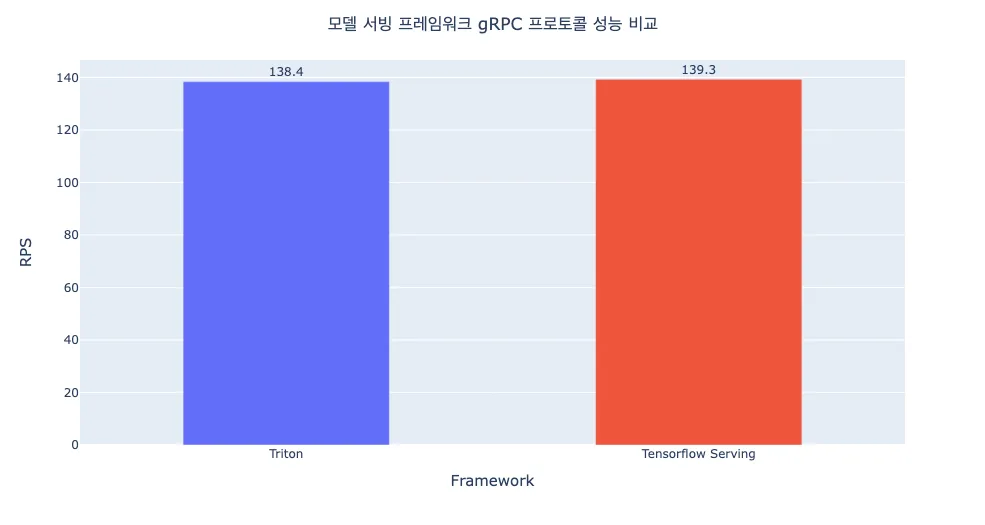
FastAPI는 추가적인 개발 및 구현이 필요했기에 테스트를 하지 않았고, Tensorflow Serving과 Triton의 결과는 거의 비슷한 것을 알 수 있습니다. 이는 바로 위에서 설명드렸던 요청을 보내는 방식이 동일해졌기 때문이죠. gRPC를 이용하기 위해 두 프레임워크 모두 데이터를 protobuf 형태로 변환하여 전송하고, 이는 이미지를 그대로 보내는 것보다 훨씬 빠르게 요청을 보낼 수 있습니다.
정리하면 프로토콜에 따라 결과가 다르지만, Triton >= Tensorflow Serving > FastAPI 순으로 성능이 좋음을 알 수 있습니다.
프레임워크 안정성 비교
프레임워크의 안정성 비교를 위해 스트레스 테스트(Stress test)를 수행했습니다.
스트레스 테스트는 각 프레임워크가 처리할 수 있는 최대 RPS의 2배 수준으로 일정 시간 서버에 부하를 줬을 때 서버가 장애 없이 안정적으로 운영이 되는지 테스트했습니다. 세 프레임워크 모두 안정적으로 최대 RPS와 그때의 Latency를 유지하며 서빙되고 있음을 확인했습니다.
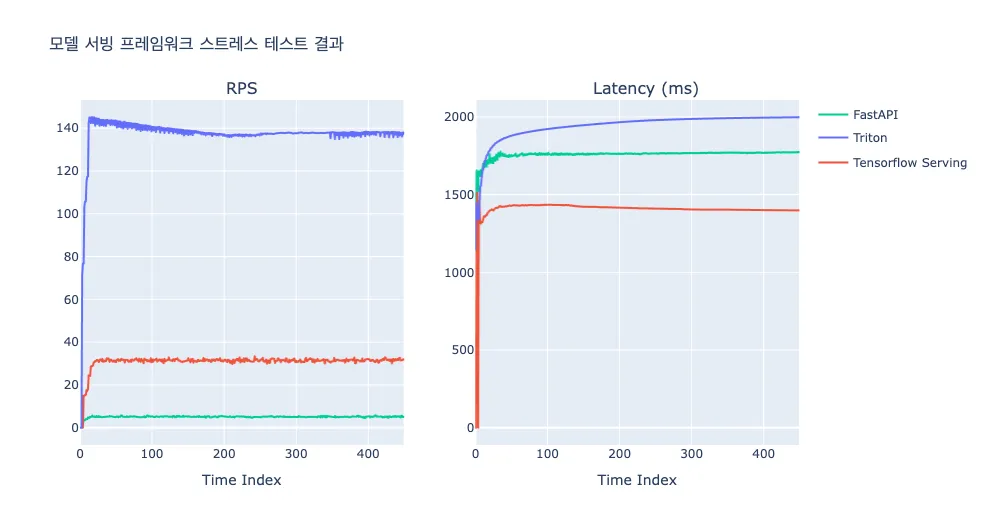
프레임워크 선정
모델 서빙 프레임워크에서 제공하는 기능과 성능, 안정성 결과를 종합해 보았을 때, Triton이 가장 적합하다고 판단을 내렸습니다. 성능과 안정성도 우수하지만 다양한 모델의 포맷을 지원한다는 점이 큰 장점이라 판단했습니다.
Triton 모델 서빙 성능 극대화하기
앞서 실험을 통해 Triton을 활용하는 것이 직접 서빙 서버를 구축하는 것보다 여러 측면에서 장점이 많다는 것을 확인했습니다. 하지만, 현재까지 확보한 모델 서빙 성능이 서비스 요구사항을 충족하지 못할 수도 있습니다. Triton에서는 모델 서빙 성능을 개선하기 위해서 다양한 기능을 제공하며, 대표적으로 Dynamic Batch, Concurrent Model Execution이 있습니다. 공식 문서에는 모델 서빙 성능 최적화를 위한 가이드를 제공하고 있으며, 해당 가이드를 따라 주요 기능들을 테스트해보고 어느 정도의 성능 개선을 이뤄낼 수 있는지 확인해보려 합니다.
실험 구성
본 포스팅에서는 Triton 서버를 실행하고 테스트하는 구체적인 코드와 과정은 설명하지 않습니다. 다만, 특정 기능들을 테스트하기 위해서는 config.pbtxt라는 Configuration을 명시해야 합니다. 테스트하고자 하는 기능들이 포함된 샘플 config.pbtxt와 테스트에 사용될 클라이언트만 간단히 언급하도록 하겠습니다.
Configuration
아래는 모델의 기본 config.pbtxt의 구성입니다. 향후 실험에서는 아래 구성을 기준으로 특정 기능에 해당하는 옵션 값을 변경하여 테스트를 진행합니다.
name: "model_onnx"
platform: "onnxruntime_onnx"
max_batch_size : 1
dynamic_batching {
max_queue_delay_microseconds: 100000
}
input [
{
name: "input_1"
data_type: TYPE_FP32
format: FORMAT_NHWC
dims: [ 224,224,3 ]
}
]
output [
{
name: "output_1"
data_type: TYPE_FP32
dims: [ 2 ]
}
]
version_policy: { latest: { num_versions: 1}}
instance_group [
{
count: 1
kind: KIND_GPU
}
]platform: 서빙하는 모델의 포맷을 명시합니다.tensorflow_savedmodel(TF),tensorrt_plan(TensorRT),onnxruntime_onnx(onnx)등으로 명시합니다.max_batch_size: Dynamic Batch를 실행하는 옵션으로, 1보다 큰 값을 가질 때 Dynamic Batch가 수행됩니다. 이는dynamic batching의 옵션들과 함께 작동합니다.max_queue_delay_microseconds는 들어온 요청이 배치를 구성하기 위해 서버 내 큐에서 기다리는 최대 시간입니다. 최대 시간이 지날 경우,max_batch_size에 해당하는 배치 크기가 되지 않더라도 배치 인퍼런스가 수행됩니다.input,output: 모델의 입/출력 이름과 데이터 타입, 차원을 명시합니다.version_policy: 사용하는 모델의 버전을 명시합니다.instance_group: Concurrent Model Execution을 실행하는 옵션으로,count가 1보다 클 경우 여러 개의 모델 인스턴스를 실행시켜 병렬적으로 요청을 처리합니다.
Performance Analyzer
각 기능 테스트 결과의 일관성을 위해, Triton에서 제공하는 Performance Analyzer라는 성능 측정 클라이언트를 활용하여 테스트를 수행했습니다. Performance Analyzer는 각 모델에 맞는 인퍼런스 요청을 생성하고, 해당 요청의 Throughput(RPS)과 Latency를 측정하여 리포트하도록 구성되어 있습니다. 또한, Concurrency 옵션이 존재하여 동시 요청을 통해 부하에 따른 성능 측정도 가능합니다.
아래의 테스트 결과는 테스트 항목에 맞게 config.pbtxt를 변경하고, 동일한 Performance Analyzer 옵션으로 측정된 성능 지표들을 정리한 결과입니다. Locust와 마찬가지로 EC2(M5.2xlarge)에 구축하였으며, Triton 서버는 기존과 동일하게 AWS Elastic Container Service(ECS)에 GPU 타입인 G4dn instance에 배포하여 테스트하였습니다.
모델 포맷별 성능 비교
Triton을 모델 서빙 프레임워크로 선정한 이유 중 하나가 다양한 모델 포맷의 지원이었습니다. 실제로, Tensorflow로 학습된 산출물인 Tensorflow Savedmodel 이외의 모델 포맷이 Tensorflow Savedmodel보다 성능적으로 우수한지 확인해봐야겠죠. 동일한 하나의 모델을 서로 다른 세 가지 모델 포맷(tensorflow_savedmodel(TF), tensorrt_plan(TensorRT), onnxruntime_onnx(onnx))으로 준비해보았습니다.
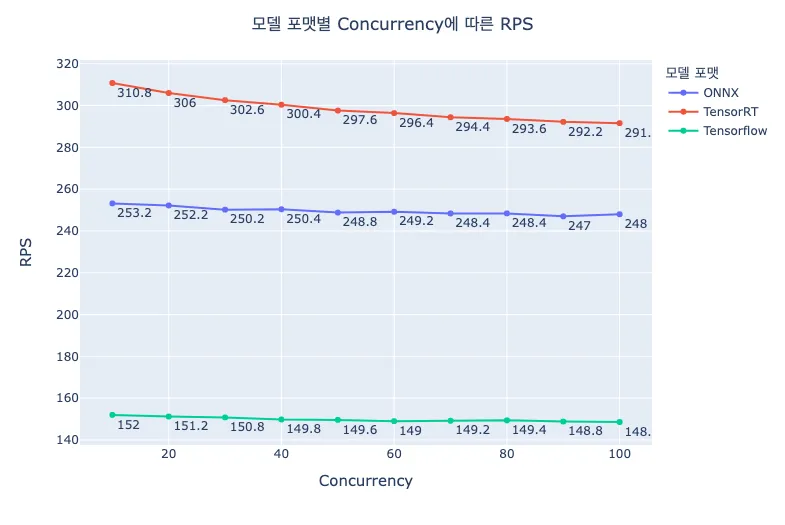
위 결과에서 알 수 있듯이 동일한 모델이라 하더라도 어떤 포맷으로 인퍼런스 최적화가 되었냐에 따라 성능에 큰 차이가 있음을 알 수 있습니다. Tensorflow 모델의 처리량이 약 150RPS 수준임에 반해, ONNX는 약 250RPS, TensorRT는 약 290RPS 입니다. 물론 이 수치는 모델의 구조에 따라 달라질 수 있지만, 모델 포맷별로 이 정도 수준의 유의미한 성능 차이가 난다는 것은 중요한 고려사항입니다. 해당 테스트 결과는 모델 서빙 프레임워크를 Tensorflow Serving이 아닌 Triton으로 선정한 것에 대한 핵심적인 백데이터입니다.
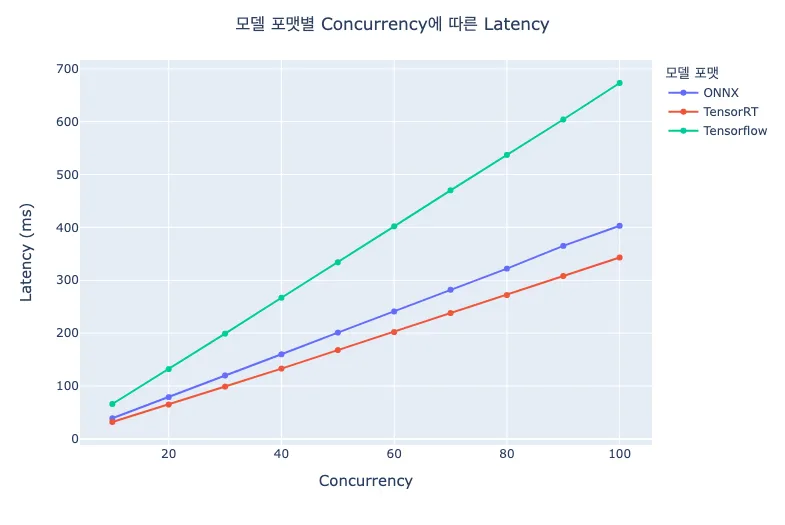
위 결과는 Latency 관점에서의 차트입니다. 동시 요청의 수가 높아지면서 부하가 높아질수록 Latency는 모델 포맷에 상관없이 선형적으로 증가한다는 것을 보여줍니다. 모델 포맷별 RPS 차트에서 보이는 성능상의 우선순위는 위 차트의 Latency 기울기 차이로 표현됨을 알 수 있습니다.
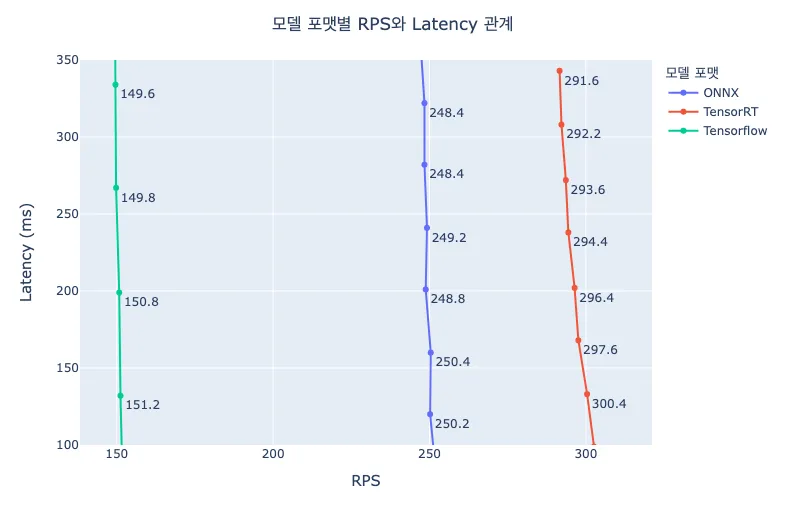
RPS와 Latency의 결과를 조합하면 위와 같은 차트로 표현할 수 있습니다. RPS와 Latency 관계를 나타내는 차트가 직관적인 인사이트를 포함하고 있으므로, 밑에서는 이 차트의 결과를 살펴보겠습니다.
Dynamic Batch 성능 비교
Triton에서 제공하는 여러 기능 중 성능에 가장 큰 영향을 미치는 기능이 Dynamic Batch입니다. Dynamic Batch란 클라이언트에서 고정된 크기의 배치로 요청을 보내는 것이 아닌 서버에서 자동으로 배치를 만들어 인퍼런스를 수행하는 기능을 의미합니다. Dynamic이 붙은 이유는 max_queue_delay_microseconds 옵션 값에 따라 동적인 배치 크기를 생성하기 때문입니다. 서버는 들어온 요청을 큐에 쌓아두고 max_batch_size만큼 배치가 구성될 때까지 max_queue_delay_microseconds 시간만큼 기다립니다. max_queue_delay_microseconds 시간이 지나면, 해당 시점까지 구성된 배치만큼 배치 인퍼런스를 수행합니다.
이번 실험에서는 max_queue_delay_microseconds는 100ms로 고정하고, max_batch_size를 변경하며 테스트한 결과를 정리했습니다.
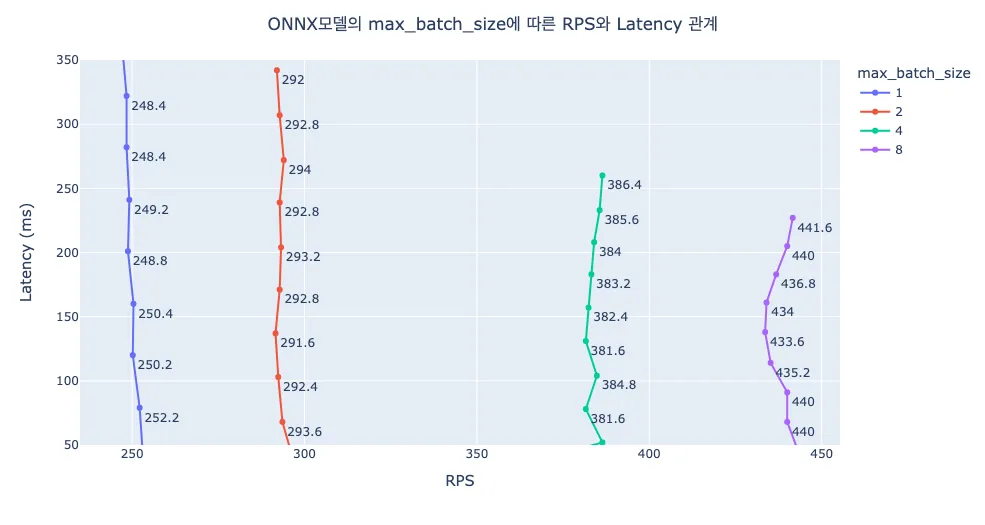
동일한 Latency에 대해 max_batch_size가 커짐에 따라 RPS가 높아짐을 알 수 있습니다. max_batch_size가 8일 때는 약 430RPS 수준으로 max_batch_size가 1일 때 대비 성능이 약 170% 개선됨을 확인할 수 있습니다. 실험 결과는 ONNX 모델에 대해서만 제시되어 있지만, Tensorflow와 TensorRT 모두 max_batch_size가 증가함에 따라 RPS가 상승하는 동일한 경향성을 보였습니다.
본 실험 결과에서는 max_batch_size에 따라 RPS가 점점 개선되는것으로 확인되지만, 실제 운영 환경에서는 서버에 들어오는 요청의 분포에 따라 max_batch_size와 max_queue_delay_microseconds 옵션의 튜닝이 필요합니다.
Concurrent Model Execution 성능 비교
Concurrent Model Execution이란 여러 개의 모델을 같이 인퍼런스 하거나, 하나의 모델을 여러 인스턴스로 실행시켜 병렬적으로 인퍼런스 하는 것을 의미합니다. 즉 요청에 대한 병렬 처리를 가능케 하는 기능이며, 이를 통해 성능 개선을 이뤄낼 수 있습니다. Concurrent Model Execution은 instance_group 내 count 옵션으로 몇 개의 인스턴스를 병렬적으로 실행할지 설정할 수 있습니다. 이는 CPU 뿐만 아니라 GPU에서도 동일하게 적용됩니다.
아래는 서로 다른 count를 적용했을 때의 성능 결과입니다. max_batch_size는 1로 설정했습니다.
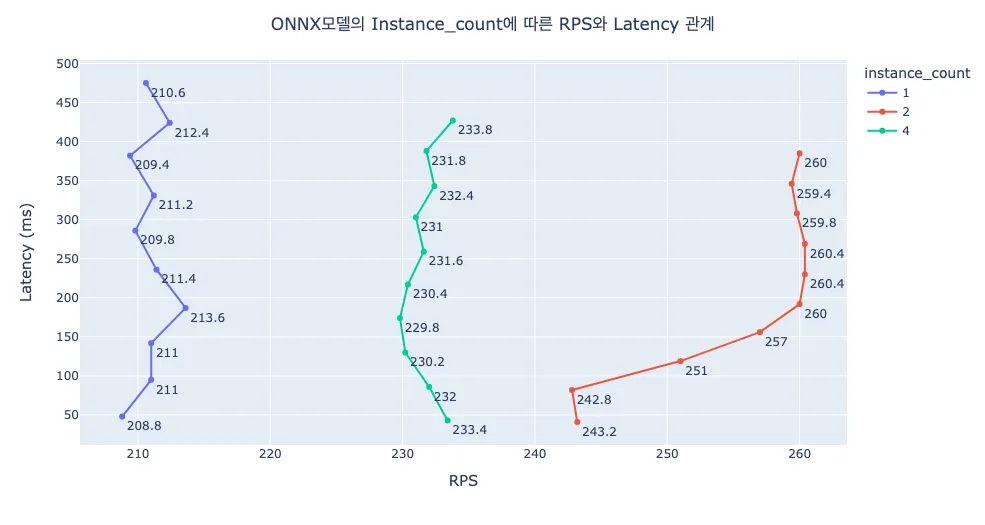
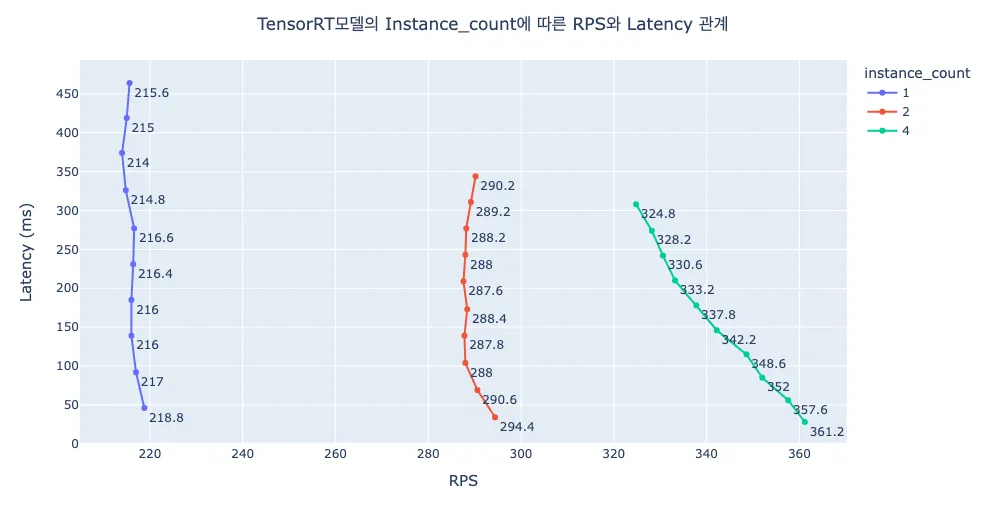
모델 포맷에 따라 우선순위는 다르지만, count를 1보다 크게 하여 병렬 처리하는 것이 RPS 개선에 도움이 되는 것을 확인할 수 있습니다.
Model Analyzer
모델 서빙 프레임워크로 Triton을 이용할 때 성능 개선에 도움이 되는 여러 기능을 테스트해봤습니다. 이러한 기능들을 조합해서 최적의 옵션 조합을 찾으려면 어떻게 해야 할까요?
Triton에서는 위와 같은 니즈를 만족시켜주기 위해 여러 조합의 실험을 한꺼번에 수행할 수 있도록 도와주는 유틸리티 툴이 있습니다. 바로 Model Analyzer입니다. 여러 기능들의 옵션 값을 명시하여 YAML파일로 구성하면, 반복적인 성능 측정을 통해 성능 결과를 정리하여 리포트를 생성하는 기능까지 제공합니다. 목적함수가 있다면 최적의 Configuration 조합도 알려줍니다.
아래 차트는 Model Analyzer에서 제공하는 최적의 Configuration에서의 결과입니다. 최적 Configuration을 정리하면 모델 포맷은 TensorRT이며, max_batch_size는 16, instance_group내 count는 2일 때 최대 성능을 보였습니다.
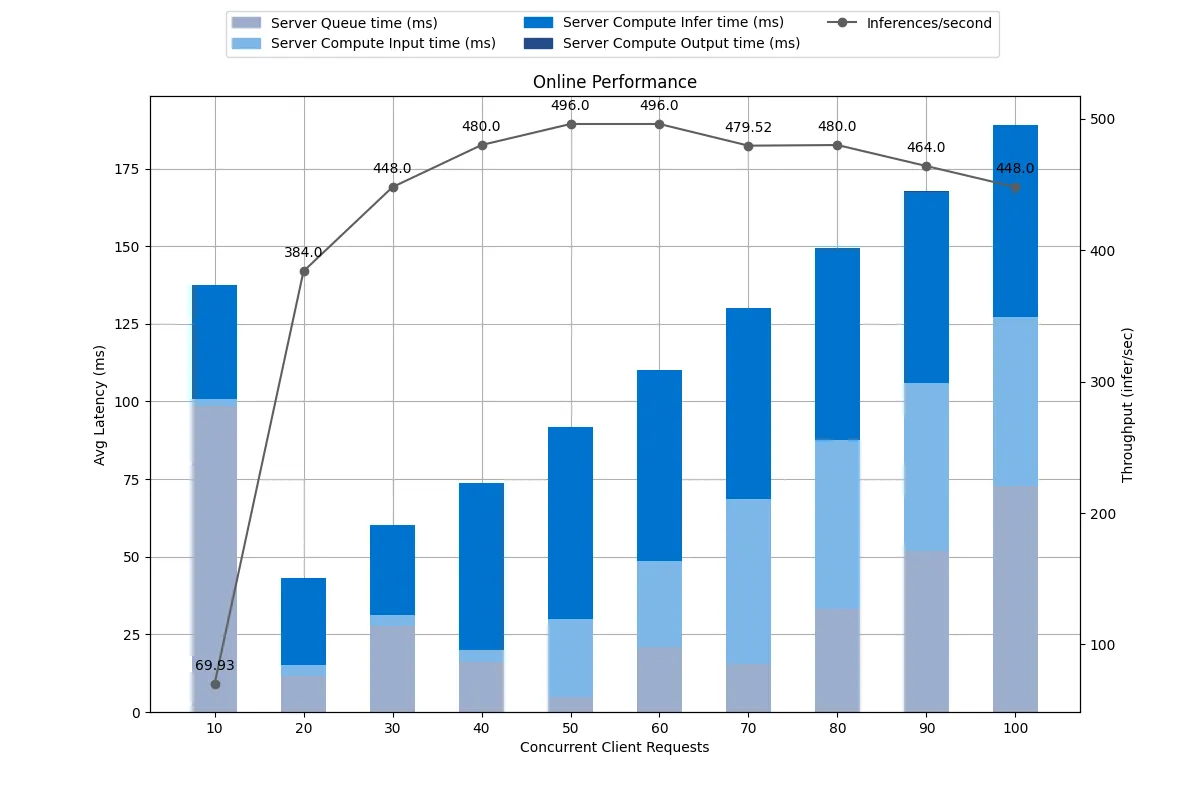
Latency는 각 항목별로 구분하여 막대 차트로 표현되어있고, Throughput(RPS)는 선 차트로 표현되어 있습니다. 최대 RPS는 약 500에 가까운 수준으로, 제일 처음 수행된 Triton 실험 결과인 150RPS 보다 330% 이상의 성능 개선이 이뤄진 결과를 확인할 수 있습니다.
Model Analyzer에서 또 하나 눈여겨봐야 할 결과는 아래와 같이 CPU, GPU 리소스 사용량을 테이블로 제공해준다는 점입니다.
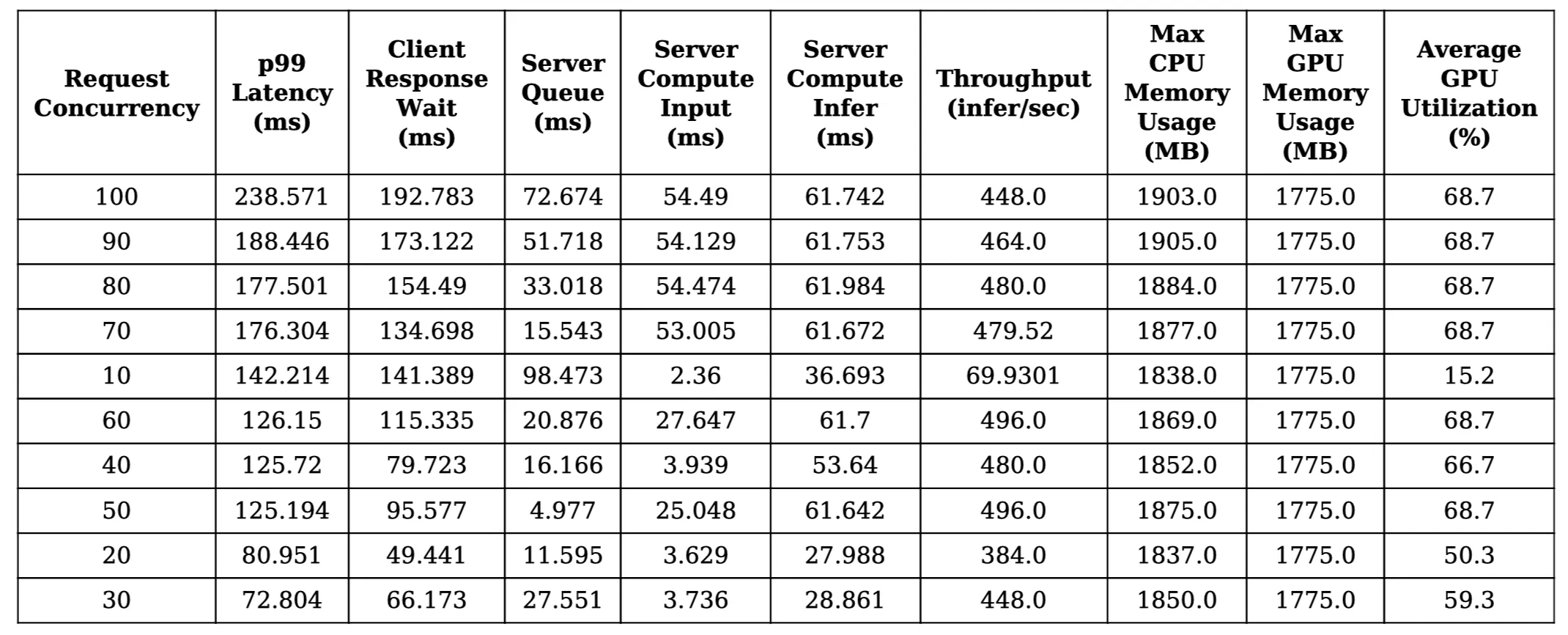
각 부하 상황에서 해당 모델의 CPU, GPU 메모리 사용량과 Utilization까지 확인할 수 있습니다. 이 데이터는 실제 서비스에서 모델을 운영할 때 리소스 최적화를 하기 위한 중요한 근거 자료로 활용될 수 있습니다.
모델 서빙 성능 극대화 요약
모델 포맷 변경과 Triton의 Dynamic Batch 기능을 활용함으로써 모델 서빙 성능을 큰 폭으로 개선할 수 있다는 것을 실험적으로 확인했습니다. 또한, Model Analyzer를 이용하여 모델의 리소스 사용량 데이터를 확인했고, 이를 통해 실제 서비스 배포 시 리소스 운용을 어떻게 해야 할지 가늠해 볼 수 있었습니다.
본 포스팅에서는 따로 언급하지 않았지만, 성능 극대화뿐만 아니라 안정성과 서비스 운영 시 도움 될 기능에 대한 테스트들도 수행했으며 결과는 아래와 같습니다.
- 모델의 Warm-Up 기능: 서비스 배포 후 모델의 첫 인퍼런스 시, Latency 개선에 도움 주는 것을 확인. 단, Tensorflow일 경우에 영향력이 크나, ONNX, TensorRT는 별 차이가 없음.
- 모델 관리 기능: Local 뿐만 아니라 AWS S3 저장소를 모델 저장소로 활용할 수 있으며, 모델 업데이트 시 방식에 대한 테스트 수행 (폴링 방식과 명시적 방식)
- 요청에 대한 ID 제공 및 각종 로그, 에러 제공 여부: ID 제공 및 로그는 잘 나오고 있으나, 에러 발생 시 ID와 매핑되지 않는 이슈가 존재했고, 이는 현재 Triton 프로젝트에서 개선 진행 중 (PR)
- 서로 다른 모델 포맷을 동시에 인퍼런스 할 때의 안정성: Concurrent Model Execution에서 서로 다른 모델을 같이 활용할 때의 안정성을 확인하고자 했으며, 안정적으로 수행됨을 확인
- Triton 내구성 테스트 (Endurance test): 모델 인퍼런스를 장시간 수행했을 때, 메모리 누수 등의 이슈 없이 안정적으로 수행됨을 확인
마치며
지금까지 카카오페이 상황에 맞는 모델 서빙 프레임워크 선정과정과 선정된 프레임워크인 Triton의 서빙 성능 개선을 위해 수행한 여러 테스트 결과를 공유해 드렸습니다. 이번 테스트를 통해 실제로 서빙에 활용될 모델이 기존 대비 얼마만큼의 성능 개선을 이뤄낼 수 있는지, 어떤 기능이 성능에 큰 영향을 미치는지 등의 수치적 데이터와 인사이트를 얻을 수 있었습니다.
본 포스팅을 시작하며 언급한 것처럼, 저희가 공유해드린 테스트 결과가 모델 서빙 프레임워크를 도입하고자 하는 분들과 서빙 성능 극대화를 위해 첫 단추로 무엇을 해야 할지 고민하는 분들에게 도움이 되었기를 바랍니다.
카카오페이에서는 서비스에 도움이 되는 모델 개발뿐만 아니라 이를 효율적으로 사용자에게 서빙하기 위한 방법을 고민하고 있습니다. 현재도 테스트 결과를 바탕으로 Triton을 실제 서비스에 적용하기 위해 준비 중에 있습니다. 저희와 이런 고민을 같이 하고 싶으신 분들이 계시다면 언제든 채용 공고를 참고해 주세요. 😀
Footnotes
-
모델 서빙이란 사용자에게 모델의 예측 결과를 전달하는 것을 의미합니다. ↩
-
출처: NVIDIA Triton Inference Server 공식 사이트 (https://developer.nvidia.com/nvidia-triton-inference-server) ↩
