요약: 카카오페이 DevOps팀은 서버 리소스 사용 효율성 향상을 목표로 ‘환경미화 프로젝트’를 진행했습니다. 이 프로젝트는 Kubernetes 상에서 운영되는 서비스의 리소스 할당을 최적화하여 서버 비용을 절감하는 것을 목표로 합니다. 기존에 할당된 CPU와 메모리 리소스를 실제 사용량에 맞게 조정하기 위해 자체 개발한 리소스 추천 서비스로 CPU와 메모리 사용 추천값을 제공하였습니다. 또한, 이를 개발팀에 알리며 자원을 효율적으로 사용하도록 했습니다. 이 과정에서 Google의 Autopilot 논문을 참조하고, VPA와 HPA의 한계를 극복하기 위한 독자적인 접근 방식을 채택했습니다. 결과적으로, 테스트 환경에서 서버 자원 사용량을 현저히 줄이며 비용 절감 효과를 확인했습니다.
시작하며
안녕하세요, 카카오페이 Devops팀 murf입니다. 카카오페이는 kubernetes에 무수히 많은 서비스가 운영되고 있습니다. 원활한 서비스 운영을 위해 수천 대의 서버가 가동 중이며, 이에 투입되는 예산은 우리의 생각 이상으로 많습니다. 그래서 생각해 보았습니다.
“어떻게 하면 서버를 더 효율적으로 사용할 수 있을까?”
당시의 상황 또한 서비스 중단 예정인 레거시 클러스터에서 새로운 클러스터로 많은 서비스를 옮겨야 했습니다. 이관으로 인해 신규 클러스터에 너무 많은 서비스를 옮기다 보니 클러스터에 리소스가 부족해지는 문제가 계속해서 나타났고, 어느 순간에는 노드로 투입 가능한 서버 재고가 없어서 서비스 이관을 못하는 상황까지 생겼습니다.
이러한 상황을 해결하기 위해 문제를 분석하다 보니 카카오페이의 kubernetes 배포 환경이 가진 리소스 문제를 발견했습니다. 그것은 바로 pod이 실제로 사용하는 사용량에 비해 많은 CPU/Memory 리소스가 할당되어 운영되고 있다는 것이었습니다. 카카오페이에서는 하나의 pod에 CPU 2 core, Memory 4 Gi의 리소스를 할당해 줍니다. 내부적으로 통계를 내보니 운영되는 pod 중에 0.5 core 미만으로 사용하는 pod은 80%였고, Memory를 1 Gi 미만으로 사용하는 pod은 20%에 달했습니다. 결국 이러한 문제를 해결하기 위해 서비스의 Request값을 줄여서 서버 비용을 줄여보자는 아이디어를 얻어 PoC를 진행하게 되었습니다.
PoC 진행을 위해 여러 오픈소스를 고민해 보았지만 카카오페이 시스템에 도입하기엔 맞지 않는 부분이 있었습니다. 부연설명하자면 대부분의 오픈소스들은 VPA (Vertical Pod Autoscaler)를 기반으로 request 추천값 기능을 제공했습니다. 하지만 카카오페이에서 운영 중인 kubernetes에서는 이미 HPA (Horizontal Pod Autoscaler) 기능을 이용하고 있었습니다. VPA를 도입하자니, VPA Readme에서 VPA는 HPA와 혼용하여 사용할 수 없다고 명시되어 있었습니다.

VPA를 사용하기 어려운 상황이었습니다. VPA를 대체할 수 있는 독자적인 서비스를 개발하고자 했고, 그 결과로 효율적인 리소스 사용을 통해 서버 구매 비용을 절감하는 ‘환경미화 프로젝트’를 진행하게 되었습니다. 환경미화 프로젝트에서 개선한 내용을 본격적으로 설명하기에 앞서 아키텍처를 우선 설명하겠습니다.
환경미화 아키텍쳐
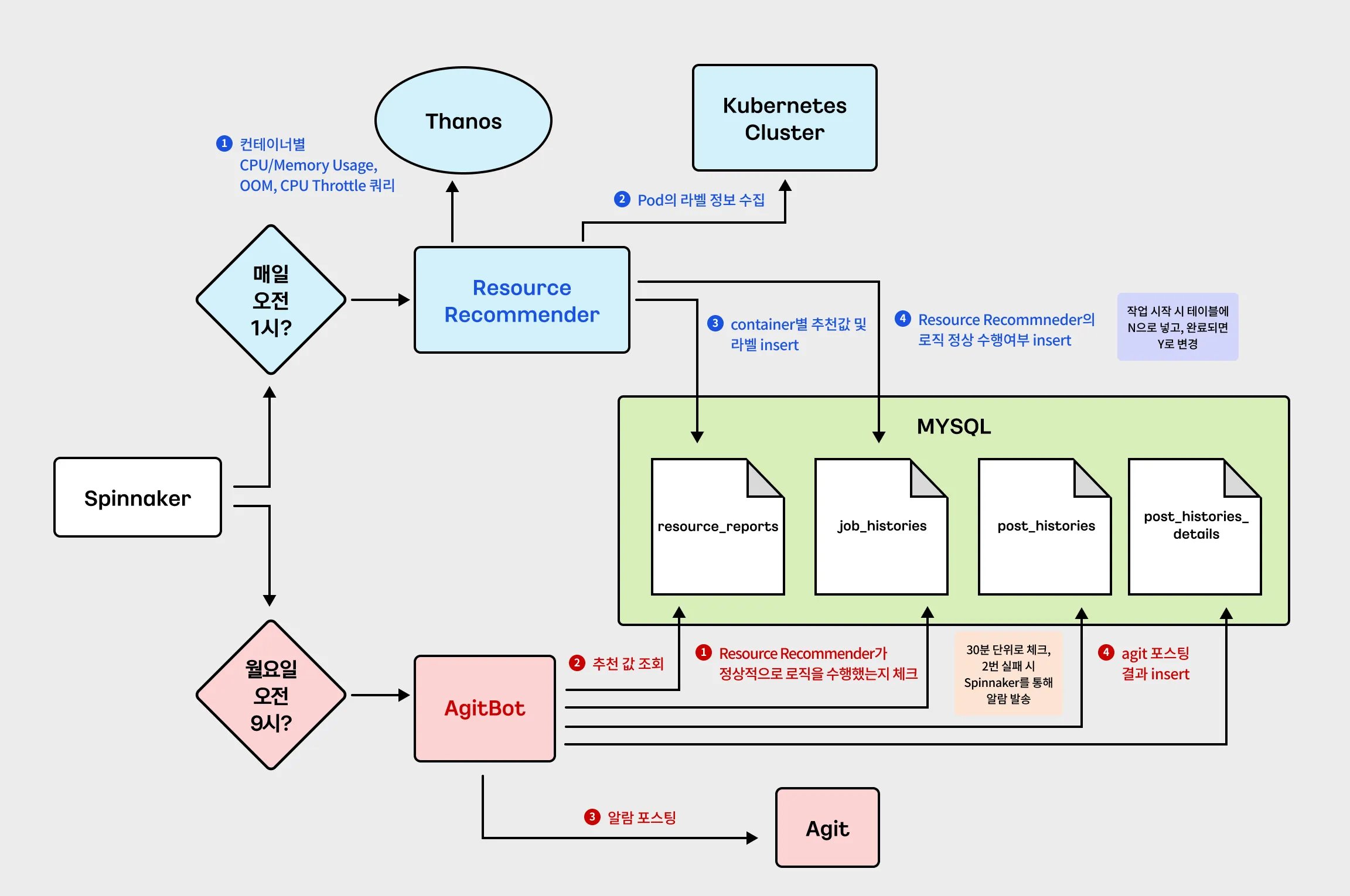
환경미화 아키텍처는 위와 같습니다. Spinnaker를 통해 두 개의 job을 배포하는데, 하나는 Request 추천값을 계산해 주는 Resource Recommender라는 job을 매일 배포하고, 다른 하나는 추천받은 값을 개발자들에게 공지하는 AgitBot을 매주 월요일 오전 9시에 배포합니다.
Resource Recommender는 thanos (시계열 데이터 저장소인 Prometheus의 HA(고가용성) 구성을 도와주는 오픈소스)로부터 추천값 계산에 필요한 CPU/Memory 메트릭을 가져와서 추천값을 만들고, 각 클러스터로부터 라벨 정보를 수집하여 MySQL의 각 테이블에 데이터를 입력합니다.
AgitBot은 추천값을 조회하여 카카오 사내 게시판인 Agit에 추천값을 게시하고, 게시된 결과를 DB에 입력하는 구조로 되어있습니다.
Autopilot
위의 아키텍처에서 Resource Recommender 모듈부터 살펴보겠습니다. 그리고 Resource Recommender 핵심인 container Request 추천값을 어떻게 계산하는지 들여다보도록 하겠습니다. 환경미화에서는 Request 추천값을 만들기 위해 Google사의 논문(Autopilot: workload autoscaling at Google)을 참고하였습니다. Autopilot은 개발자가 서버 관리를 신경 쓰지 않고 애플리케이션을 실행할 수 있도록 컨테이너 기반의 워크로드를 실행하고, 자동으로 리소스를 조정하여 요구 사항에 맞게 확장하거나 축소하는 방법을 제시합니다.
Autopilot 논문에서 제시하는 공식을 이해하기 위해서는 다음 개념들을 알고 있어야 합니다. 일정 기간 동안의 CPU/Memory의 사용량을 histogram으로 나타냈을 때, 아래와 같은 개념이 필요합니다.
-
Lower bound: histogram에서 50번째 값에 위치하는 값(상위 50% 값)
-
Target bound: histogram에서 90번째 값에 위치하는 값(상위 90% 값)
-
Upper bound: histogram에서 95번째 값에 위치하는 값(상위 95% 값)
-
margin-fraction: 안전마진 값으로, default 15%의 값을 갖습니다. 말 그대로 안전마진이라 별도 기준은 없으며, 판단에 따라 변경 가능합니다.
-
confidence_multiplier: 기간이 짧으면 추천값에 대한 신뢰도가 낮으므로, 이 confidence_multiplier 값을 곱하여 교정합니다. 이 값은 메트릭 수집기간이 길면 길수록 1에 가까워지며, Lower bound/Target bound/Upper bound 별로 아래와 같은 공식을 사용하여 값을 구하게 됩니다. (history-length-in-days는 계산에 사용할 메트릭 수집기간을 나타냅니다.)
-
Lower bound
- 기간이 짧으면 신뢰도가 낮으므로, Lower bound에서 제시된 값보다 더 작은 값을 추천하기 위해 다음과 같은 공식을 사용합니다.
- confidence_multiplier = (1 + 0.001/history-length-in-days) ^ - 2
- 시간에 따라 다음과 같은 값을 얻게 됩니다.
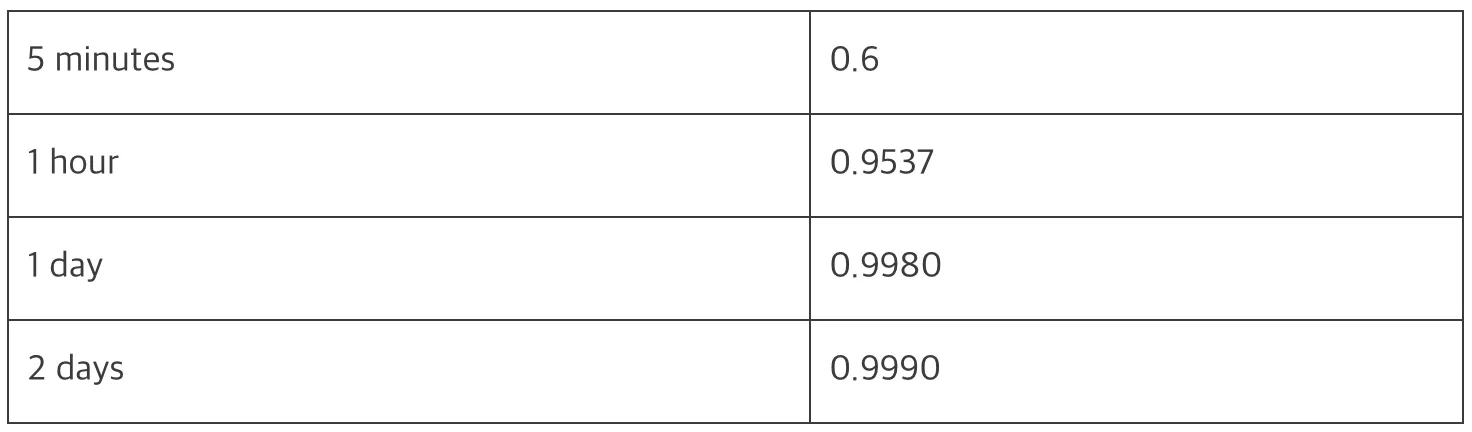
lowerBound
-
Target bound
- target bound는 적절한 값을 찾았다는 의미를 갖는 값으로 아래와 같은 값을 갖습니다.
- confidence_multiplier = 1
-
Upper bound
- 기간이 짧으면 신뢰도가 낮으므로, Upper bound에서 제시된 값보다 더 큰 값을 추천하기 위해 다음과 같은 공식을 사용합니다.
- confidence_multiplier = (1 + 1/history-length-in-days)
- 시간에 따라 다음과 같은 값을 얻게 됩니다.
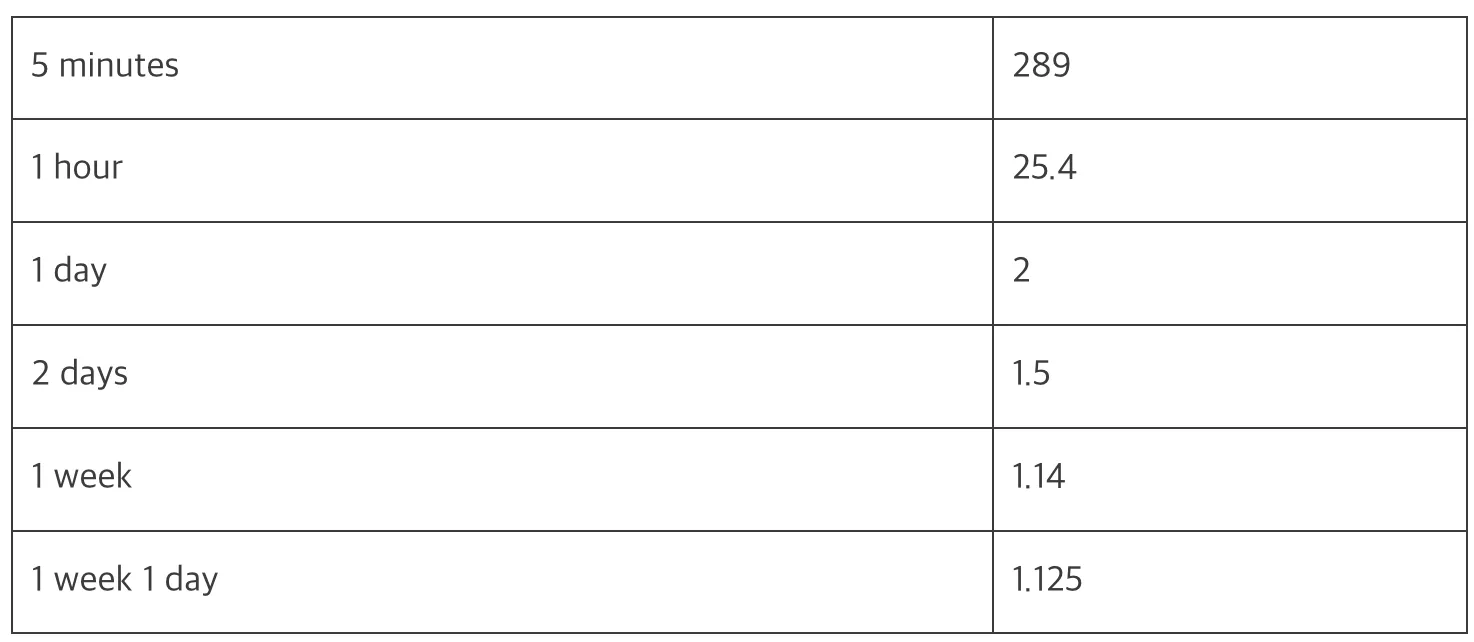
upperBound
-
위의 개념들을 활용하여 각각의 bound를 공식으로 나타내면 다음과 같습니다.
lower_bound_estimation = bound * margin_fraction * confidence_multiplier
= bound * 1.15 * (1 + 0.001 / history_length_in_days) ^ - 2
target_bound_estimation = bound * 1.15
upper_bound_estimation = bound 값 * margin_fraction * confidence_mutiplier
= bound 값 * 1.15 * (1 + 1 / history_length_in_days)위에서 말하고자 하는 것은 아래와 같습니다.
- 특정 기간 동안의 데이터를 추출하여 히스토그램으로 나타내고,
- 특정 n분위 값을 추출합니다.(Lower bound: 50th, Target bound: 90th, Upper bound: 95th)
- 값에 버퍼를 주기 위해 추출된 n분위 값에 margin_fraction이라는 마진값을 곱해주고,
- 기간이 짧으면 짧을수록 값이 부정확하니, 그것을 교정하기 위해 confidence_multiplier를 곱해서 결과를 냅니다.
좀 더 확실하게 하기 위해서 예시를 들어보겠습니다.
다음과 같은 값을 갖는 2일 치 CPU 그래프가 있다고 가정해 봅시다.
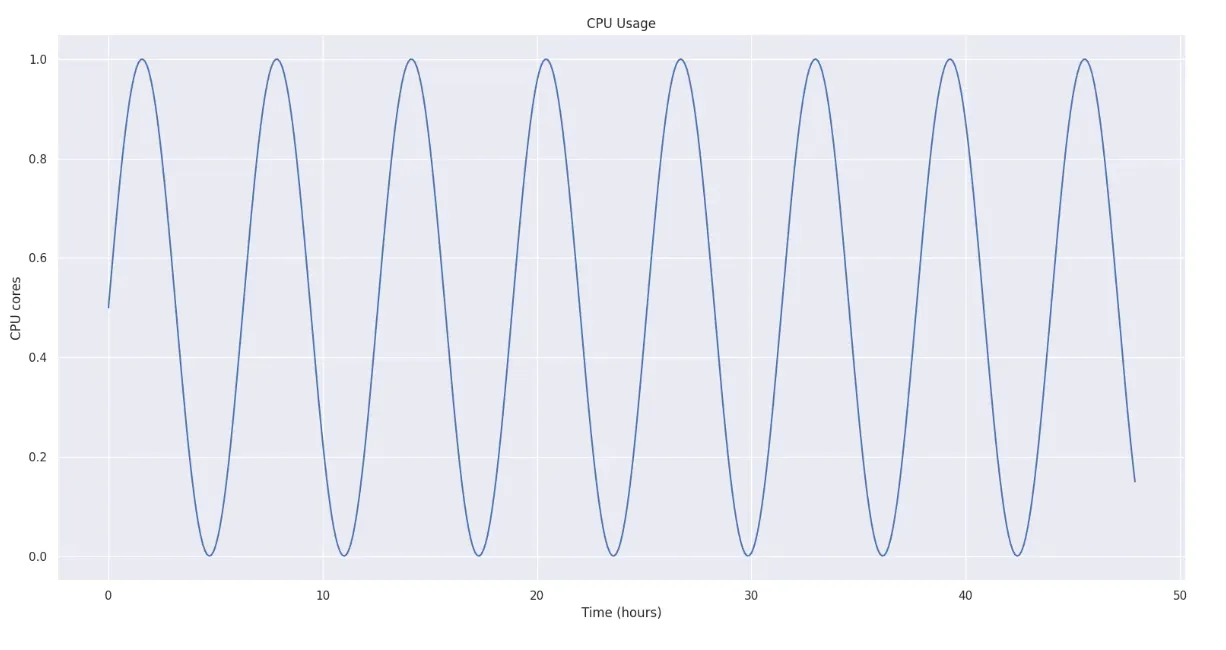
이것을 히스토그램으로 나타내어 각각의 bound를 구해보면 표에 제시된 값을 가지게 됩니다.

여기서 각각의 Lower/Target/Upper bound를 공식을 통해 값을 구해보면 아래 표와 같고,
lower_bound_estimation = bound * 1.15 * (1 + 0.001 / history_length_in_days) ^ - 2
= 0.5467 * 1.15 * (1 + 0.001 / 2) ^ - 2
= 0.628
target_bound_estimation = bound * 1.15
= 1.0163 * 1.15
= 1.168
upper_bound_estimation = bound 값 * margin_fraction * confidence_mutiplier
= bound 값 * 1.15 * (1 + 1 / history_length_in_days)
= 1.0163 * 1.15 * (1 + 1/2)
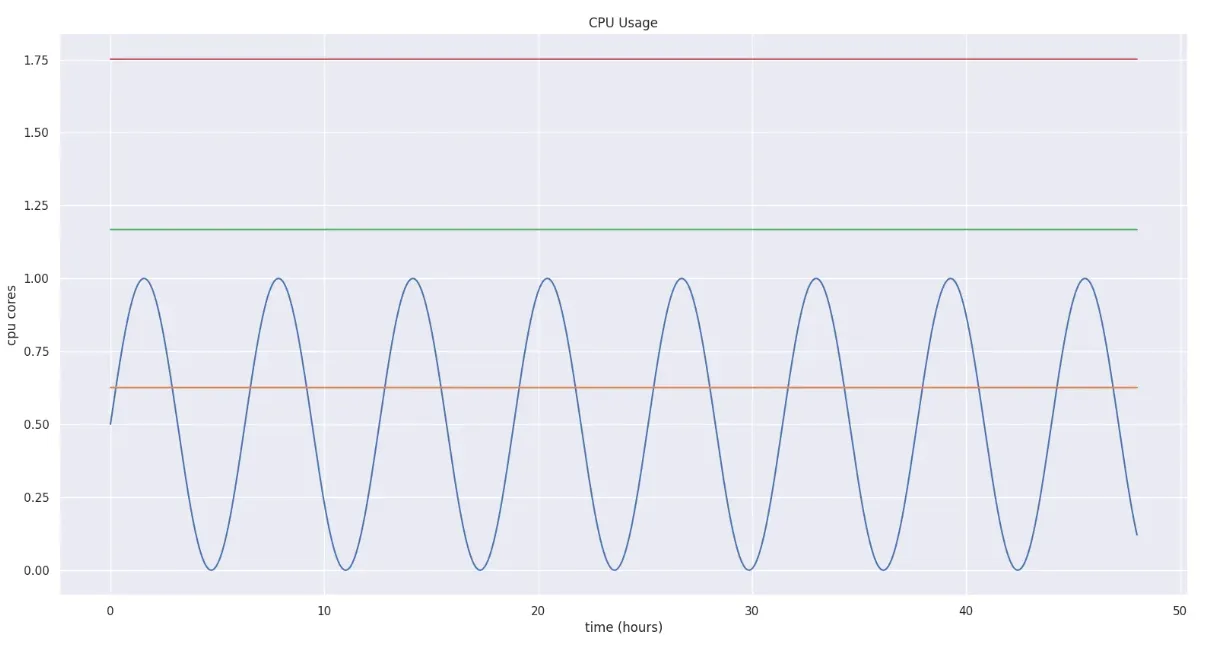
= 1.753이것을 그래프로 나타내면 다음과 같습니다.
(빨간색 실선: Upper bound, 초록색 실선: Target bound, 주황색 실선: Lower bound)
환경미화에서의 Autopilot 활용
환경미화 프로젝트에서도 Autopilot에서 제시한 대로 resource-recommender라는 모듈을 개발하기로 했습니다. 카카오페이 서비스 리소스 부족으로 인한 장애를 최소화하려면 환경미화에서 추천한 값을 어떻게 적용할지 고민해 봤습니다. 우선 upper_bound를 활용하여 CPU/Memory 추천값을 적용하기로 했으며, margin_fraction은 기본값 그대로 15%를 가져가고, 2주 치 데이터를 기준으로 하여 추천값을 적용하기로 했습니다. 이를 구현하기 위해 prometheus에서 제공하는 메트릭들을 활용하였고, 활용된 프로메테우스 함수 및 메트릭은 다음과 같습니다.
- quantile_over_time: 프로메테우스에서 제공하는 함수. 주어진 기간 동안의 n분위 값 (0 ≤ φ ≤ 1)을 구합니다.
- container_cpu_usage_seconds_total: container CPU 사용량.
- container_memory_working_set_bytes: container Memory 사용량.
- kube_pod_labels: pod에 있는 라벨 정보를 가지고 있는 메트릭.
- kube_pod_owner: pod의 상위 workload (deployment, daemonset 등)을 가진 메트릭.
Resource Recommender 구현시의 문제점
개발 초기에 위에 제시한 함수 및 메트릭을 활용했을 때, 크게 두 가지 문제점이 있었습니다.
- 구현한 쿼리에 join문이 많아서 프로메테우스 실행시간이 느림과 동시에 벡터값이 많아서 쿼리 결과를 정상적으로 받지 못하는 케이스가 많았다는 것입니다.
- kubernetes 상에 하나의 Deployment에는 여러 개의 pod이 배포될 수 있기 때문에, 그중에 하나의 pod 또는 container를 선별해서 값을 추려야 한다는 것이었습니다.
초기에는 다음과 같은 쿼리를 사용했습니다.

위의 쿼리를 보면 on이라고 하는 join 쿼리가 많습니다. 그리고 or 절을 통해 두 쿼리를 이어주고 있고, 심지어 2주 치의 데이터를 조회하여 데이터를 처리하기 때문에 속도가 굉장히 느리다는 문제가 있었습니다. 쿼리가 이렇게 길어진 이유는 간단합니다.
수집된 데이터를 관리하기 위해서 pod의 라벨 정보가 필요했고, 그를 위해 kube_pod_labels 메트릭을 사용했습니다.
배포된 pod들 중에서 상위 95% 값을 추출하기 위해서는 pod들을 하나로 묶어줄 수 있어야 했습니다. 그리고 이를 위해서는 pod의 상위 workload (deployment, daemonset 등)를 알 수 있는 owner 라벨이 필요했는데, owner 라벨은 kube_pod_owner 메트릭에 있었습니다.
카카오페이 내에는 1.16 버전 이상과 미만, 두 가지 kubernetes 버전을 운영하고 있습니다. 버전 별로 다른 라벨을 부여하기 때문에 or절로 이루어진 쿼리가 실행됩니다.
- 1.16 버전 이상: pod이라는 라벨로 붙음
- 1.16 버전 미만: 제공하는 container의 pod 라벨이 pod_label로 붙음
하지만, 이렇게 해서는 쿼리의 결과를 응답받는 데에 너무 많은 시간이 소요됩니다. 쿼리를 처리하는 프로메테우스에도 큰 부하를 발생시켜 프로메테우스에 장애를 일으킬 수 있었습니다. 결국 저희는 위의 쿼리 문제를 해결하기 위해 아래와 같은 방법을 사용하기로 합니다.
- kube_label과 kube_pod_owner 라벨을 조인하지 말고, kubernetes의 MutatingwebhookConfiguration 기능을 활용하여 새로 생성되는 pod에 owner 라벨을 추가하여 관리하자.
- fade out 될 예정인 낮은 버전의 클러스터 하나는 수집 대상에서 제외하자.
- 라벨 정보는 kubernetes를 호출하여 pod 별로 라벨을 가져오자.
- 쿼리를 실시간으로 실행시키지 말고, recording rule을 활용하여 쿼리 결과를 미리 실행시켜 두자.
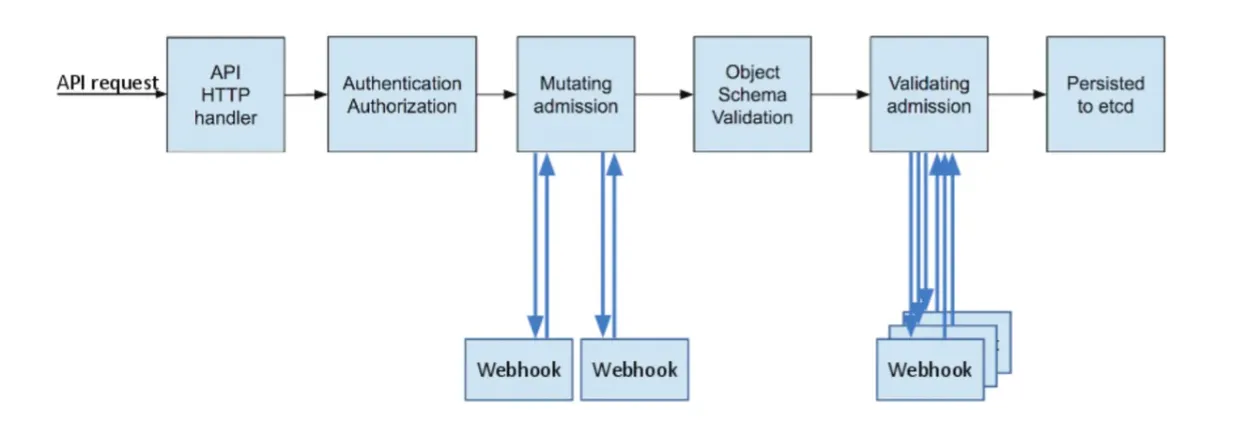
먼저, kubernetes에서 지원하는 MutatingWebhookConfiguration은 kubernetes api-server의 오브젝트(pod 등) 생성 요청을 가로채어 제어를 할 수 있는 확장 기능으로 플러그인 형태로 사용자가 추가할 수 있습니다. MutatingWebhookConfiguration의 콘셉트는 다음과 같습니다.
- 인증과 인가를 거친 요청에 대해 더 고도화된 판단을 통해 최종적으로 접근여부를 결정하기 위해 사용하는 단계.
- 요청을 받으면 인증과 인가과정을 거친 후, 조정(Mutating Admission), 객체의 정합성 체크, 유효성 체크(Validating Admission)의 단계를 거쳐 etcd에 기록하는데
- MutatingWebhookConfiguration을 통해 Mutating Admission 단계에서 kubernetes 객체에 annotation이나 label, sidecar 등을 추가할 수 있다.
저희는 라벨을 추가하는 golang 코드를 구현하여 MutatingwebhookConfiguration 실행 시 해당 코드 동작이 실행될 수 있도록 서비스를 구현하였습니다. 참조 코드는 아래와 같습니다.
func (whsvr *WebhookServer) getOwner(ctx context.Context, obj *ownerRef, namespace string) (*ownerRef, error) {
owner := ownerRef{}
var err error
owner.namespace = namespace
switch obj.ownerRef[0].Kind {
case "DaemonSet":
var ds *v1.DaemonSet
ds, err = whsvr.K8sClient.AppsV1().DaemonSets(namespace).Get(ctx, obj.ownerRef[0].Name, metav1.GetOptions{})
owner.name = ds.Name
owner.kind = "DaemonSet"
owner.ownerRef = ds.OwnerReferences
case "Deployment":
var deployment *v1.Deployment
deployment, err = whsvr.K8sClient.AppsV1().Deployments(namespace).Get(ctx, obj.ownerRef[0].Name, metav1.GetOptions{})
owner.name = deployment.Name
owner.kind = "Deployment"
owner.ownerRef = deployment.OwnerReferences
...
}
...
return &owner, err
}func (whsvr *WebhookServer) mutate(ar *v1beta1.AdmissionReview) *v1beta1.AdmissionResponse {
req := ar.Request
var pod corev1.Pod
...
topObject, err := whsvr.getTopLevelObject(context.Background(), &pod, req.Namespace)
labels := map[string]string{}
if !checkLabel("pay.owner.kind", &pod.ObjectMeta) {
labels["pay.owner.kind"] = topObject.kind
}
if !checkLabel("pay.owner.name", &pod.ObjectMeta) {
labels["pay.owner.name"] = topObject.name
}
patchBytes, err := createPatch(&pod, labels)
if err != nil {
return &v1beta1.AdmissionResponse{
Result: &metav1.Status{
Message: err.Error(),
},
}
}
log.Infof("AdmissionResponse: patch=%v\\n", string(patchBytes))
return &v1beta1.AdmissionResponse{
Allowed: true,
Patch: patchBytes,
PatchType: func() *v1beta1.PatchType {
pt := v1beta1.PatchTypeJSONPatch
return &pt
}(),
}
}MutatingAdmissionWebhook을 통해 추가된 라벨들을 kubernetes를 통해 수집하도록 resource-recommender 코드를 수정하였습니다.
이렇게 라벨이 분리되어 정리된 프로메테우스 CPU 추천값 쿼리는 아래와 같습니다.

이것을 아래와 같이 프로메테우스의 config에 recording rule로 등록해 줍니다.
recording_rules.yml: |
groups:
- interval: 1m
name: container_cpu_usage_seconds_total
rules:
- expr: |
rate(container_cpu_usage_seconds_total{container!~'hc|POD|', image!=''}[1m]) * on (cluster, namespace, pod) group_left(label_pay_owner_name, label_pay_owner_kind) kube_pod_labels
record: record:container_cpu_usage_seconds_total:rate_1m
- expr: |
max by (cluster, namespace, container, label_pay_owner_name, label_pay_owner_kind) (
record:container_cpu_usage_seconds_total:rate_1m
)
record: record:container_cpu_usage_seconds_total:max_rate_1m
- expr: |
quantile_over_time(0.95, record:container_cpu_usage_seconds_total:max_rate_1m[2w:1m])
record: record:container_cpu_usage_seconds_total:q95_2w_max_rate_1m위의 recording rule을 통해 우리는 아래와 같은 쿼리로 빠르게 쿼리 결과를 수집할 수 있었습니다.
record:container_cpu_usage_seconds_total:q95_2w_max_rate_1m{cluster="${cluster}",namespace="${namespace}"}이제 resource-recommender에 대한 구현은 완료가 되었으니, resource-recommender에서 추천한 CPU/Memory 값을 서비스들에 적용해야 하는데, 페이에서 운영 중인 서비스들에 자동으로 추천값을 적용할 것인지 고민이 생겼습니다. 카카오페이는 금융회사로서 장애가 최소로 발생해야 하기 때문에, 혹시 모를 리소스 이슈를 방지하기 위해 각 개발팀에 알림을 주기로 했습니다. 그렇게 ecoami-agitbot이라는 봇을 개발하게 되었습니다.
Eco-ami Agitbot
ecoami-agitbot의 역할은 간단합니다.
1. 추천값을 업무용 커뮤니티 서비스인 아지트에 양식을 올려 각 개발팀에 알람 발송
2. 개발팀에서 알람이 필요하지 않다면, 특정 namespace에 대한 알람을 제외개발하면서 세 가지 고민이 있었습니다.
- 알람을 어떤 기준으로 발송할 것인가?
- 각 기준에 맞게 개발팀은 어떻게 찾아서 지정할 것인가?
- 알람 제한은 어떠한 기준으로 줄 것인가?
처음에는 서비스 단위로 알람을 발송할까 고민했습니다. 그렇게 하면 개발팀별로 담당하는 서비스가 여러 개라서 최악의 경우 개발자마다 수십 개의 추천값 알림을 발송받을 수도 있습니다. 개발팀은 알람을 노이즈로 느낄 것이 분명했기에 서비스 단위로는 추천값을 제안할 수는 없었습니다.
그래서 저희는 서비스의 상위 객체인 namespace를 기준으로 사용하기로 했습니다. 그 이유는 크게 두 가지로 볼 수 있습니다. 우선 namespace 별로 관리를 하면 서비스 기준으로 알람을 보내는 것보다 상대적으로 적은 알람을 보낼 수 있습니다. 또한, 카카오페이는 namespace 기반의 권한 관리체계를 가지고 있기 때문에, namespace를 관리하는 개발팀을 쉽게 알 수 있습니다. namespace를 기준으로 하면 알람 제한과 namespace 별 개발팀 파악이라는 두 가지 고민을 해결할 수 있습니다.
이 해결방법을 사용하여 아래와 같이 각 개발팀에게 자원을 추천하는 알람을 보내게 되었습니다.
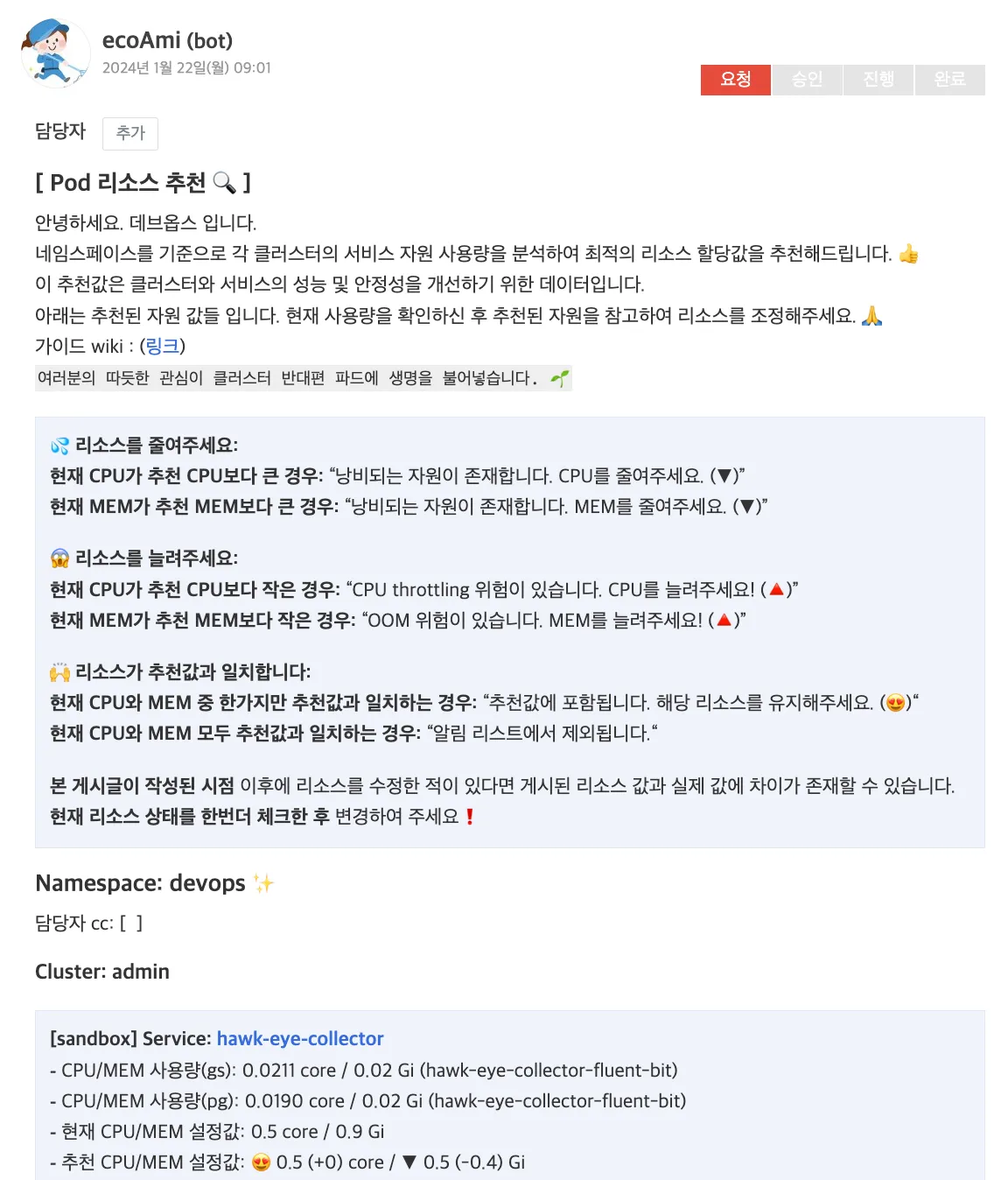
알람 제한에 대한 문제는 ecoami-agitbot에 아래와 같은 설정값을 적용하여 해결하였습니다.
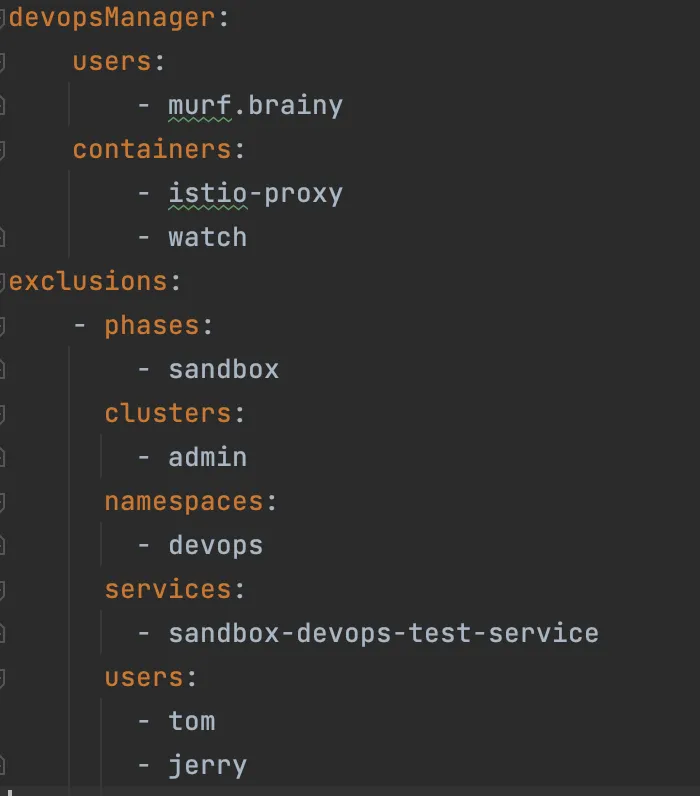
알람 예외처리 config에는 크게 devopsManager와 exclusions가 있는데, devopsManager는 devops 팀에서 관리하는 namespace에 대해 특정 컨테이너를 기준으로 예외처리를 할 수 있게끔 했습니다.
exclusions는 배열로 입력되며, phase, cluster, namespace를 필수값으로, 특정 namespace에 있는 전체 서비스에 대해 예외처리를 할 수 있습니다.
여기에 추가로 service를 입력하면 특정 서비스에 대해서 예외처리를 할 수 있고, user를 입력하면 특정 namespace나 서비스들에 대해 예외처리를 할 수 있습니다. 그리고 이렇게 개발된 ecoami-agitbot을 활용하여 카카오페이 테스트 환경인 sandbox 환경부터 개발팀에 적용을 요청하였고, 많은 팀들이 값을 적용해 주었습니다.
실제로 적용해 보니 리소스가 부족했다?
하지만 적용 과정에서 일부 서비스에 문제가 발생했습니다. 평소에 0.01 core/0.01 Gib 정도로 굉장히 적은 리소스를 사용하는 A라는 서비스가 있다고 가정해 봅시다. 그리고 sandbox 환경에서 자원 추천값의 최솟값은 0.5 core/0.5 Gib입니다.
A라는 서비스는 평소에 0.01 core/0.01 Gib 정도의 자원을 사용하기 때문에, 자원 추천값의 최솟값인 0.5 core/0.5 Gib를 추천하여 개발자가 서비스에 추천값을 적용했는데, pod이 Readiness Probe에 실패하여 배포되지 않는 이슈가 있었습니다. ReadinessProbe란 Pod가 요청을 처리할 준비가 되었는지 여부를 확인합니다. Pod가 이 Probe를 실패하면 Kubernetes는 Pod를 서비스에서 제외하고 다른 Pod로 요청을 전달하는데, 이를 통해 요청을 처리할 준비가 되지 않은 Pod에 대한 요청을 방지할 수 있습니다.
하지만 이 과정에서 pod이 배포되지 못했던 이유는 pod 배포 초기에 warm up 단계에서 서비스가 올라가면서 라이브러리를 메모리에 올리고, 서비스를 준비하는 과정에서 예상보다 많은 리소스를 사용하는데, 이 과정에서 추천 최솟값인 0.5 core를 넘거나 0.5 Mib가 넘는 자원을 필요로 하는 경우들이 있었습니다.
이 문제를 해결하기 위해서는 세 가지 방법이 있었습니다.
1. 최솟값을 상향 조정한다.
2. Readiness Probe의 시간을 늘려준다.
3. QoS를 Burstable로 변경한다(limit 값을 늘려준다)-
최솟값을 상향 조정한다는 방법은 자원을 절약하기 위한 프로젝트의 방향과는 맞지 않고, -
Readiness Probe의 시간을 늘려준다는 방법은 Memory가 부족한 경우 OOM이 발생하여 pod이 재시작될 수 있기 때문에 Readiness Probe 시간을 변경하는 건 어려움이 있었습니다. -
QoS를 Burstable로 변경한다 (limit 값을 늘려준다)는 방법은 sandbox라는 테스트 환경이라는 것을 고려했을 때 충분히 변경이 가능했고, limit 값을 적절히 정해주면 warm up 단계에서 서비스 실행이 실패하지 않는다는 장점이 있었습니다. 그리고 운영 환경의 경우 장애를 최소화하기 위해 리소스 추천 최솟값을 CPU 2 core/Memory 2 Gib로 하려고 했기 때문에, warm up 단계에서 이슈가 발생하지 않을 것이라는 것이었습니다.
그래서 환경미화 프로젝트에서는 sandbox 테스트 환경의 경우 최솟값은 그대로 적용하되 limit 값을 2 core/2 Gib로 지정하였고, 이로 인해 문제가 재발하는 것을 방지할 수 있었습니다.
마치며
테스트 환경 적용 그 이후
다행히 해당 이슈를 해결한 뒤에는 개발팀에서 보고된 추가 이슈는 없었습니다. 이후에도 추천값을 계속하여 적용하였고, 현재까지 테스트 환경의 총 1,490개의 서비스 중에서 약 400개 서비스에 적용을 완료헸습니다.
이로써 기존에 총 2,682 core/3,266 Gib를 점유하던 클러스터의 자원사용량은 현재 2,434 core/3,111 Gib로, 238 core/155 Gib를 절약할 수 있었으며, 비율로는 CPU 8.8%, Memory 4.7%가량을 절약할 수 있었습니다. 현재 운영 환경에서도 추천값을 개발팀에 추천하고 있지만, 아직 초기 단계이고 점차 적용하는 과정에 있어서 조금씩 자원을 절약해가고 있습니다.
결론적으로 환경미화 프로젝트는 Autopilot을 활용하여 kubernetes 서비스에서 사용하는 자원을 절감하고, 서버 리소스를 효율적으로 운영할 수 있는 환경을 구축하게 되었습니다. 앞으로도 이러한 경험을 토대로 더 나은 운영 방안을 모색하며, 서비스의 성능과 안정성을 지속적으로 향상할 계획입니다.
이번 프로젝트를 진행하면서 kubernetes 상에서 얼마나 많은 리소스가 낭비되고 있는지를 실감할 수 있었습니다. 특히 AWS의 EKS 환경에는 On-Premise 환경에 비해 적은 수의 서비스가 올라가 있지만, 일부 서비스들에 환경미화 추천값이 적용된 것만으로도 사용되는 EC2 노드가 줄면서 비용 절감을 바로 확인할 수 있었습니다. 비용 절감이 더욱 피부에 와닿았던 것 같습니다. 앞으로도 사내에 적극적으로 환경미화의 추천값 적용을 권장하여 더 사내의 불필요한 비용을 줄이길 바랍니다.




![[if(kakaoAI)2024] 카카오페이증권의 Kubernetes 지능형 리소스 최적화 (feat. Dr.Pym Project 공유)](/_astro/thumb.CGBHxK2H_ZWFBjN.webp)