시작하며
안녕하세요, 카카오페이증권의 DevOps 팀에서 FinOps 업무를 담당하는 션이에요.
이번 블로그는 최근 AWS 2023 re:Invent에서 카카오페이증권 CTO 블리츠가 발표한 일상과 투자를 연결하는 카카오페이증권의 클라우드 활용사례 ESG, 효율성 그리고 비용에 대한 도전 중에서 비용 가시화에 대한 내용을 깊게 알아보려고 해요. 조직의 규모가 커질수록 CostExplorer와 MSP에서 제공하는 비용관리와 가시화에 한계를 느끼는 경우가 많아요. 이런 한계를 카카오페이증권은 어떻게 기술적으로 풀어냈는지 한번 살펴봐요.
우리는 어떤 한계를 만났을까?
AWS에서 제공하는 CostExplorer는 전반적인 비용을 아주 잘 보여주는 서비스에요. 그러나 RI/SP 약정을 사용하고, EKS를 사용하다 보면 문제가 발생하는데요.
- RI/SP 약정의 한계 : RI를 사용하는 경우 결제 방식에 따라 비용이 다르게 표현되고, 개발팀에서 필요로 하는 사용량 증감을 CostExplorer에서 확인하기란 쉽지 않았어요.
- EKS의 한계 : 카카오페이증권은 EKS를 표준으로 사용하고 있어요. 여기서 우리는 EKS에서 운영하는 서비스별 비용을 보고 싶었지만, CostExplorer에서 확인할 수 없었어요.
카카오페이증권에서는 우리가 보고 싶은 데이터를 볼 수 있는 가시화가 필요했어요. 간략하게 살펴보면!
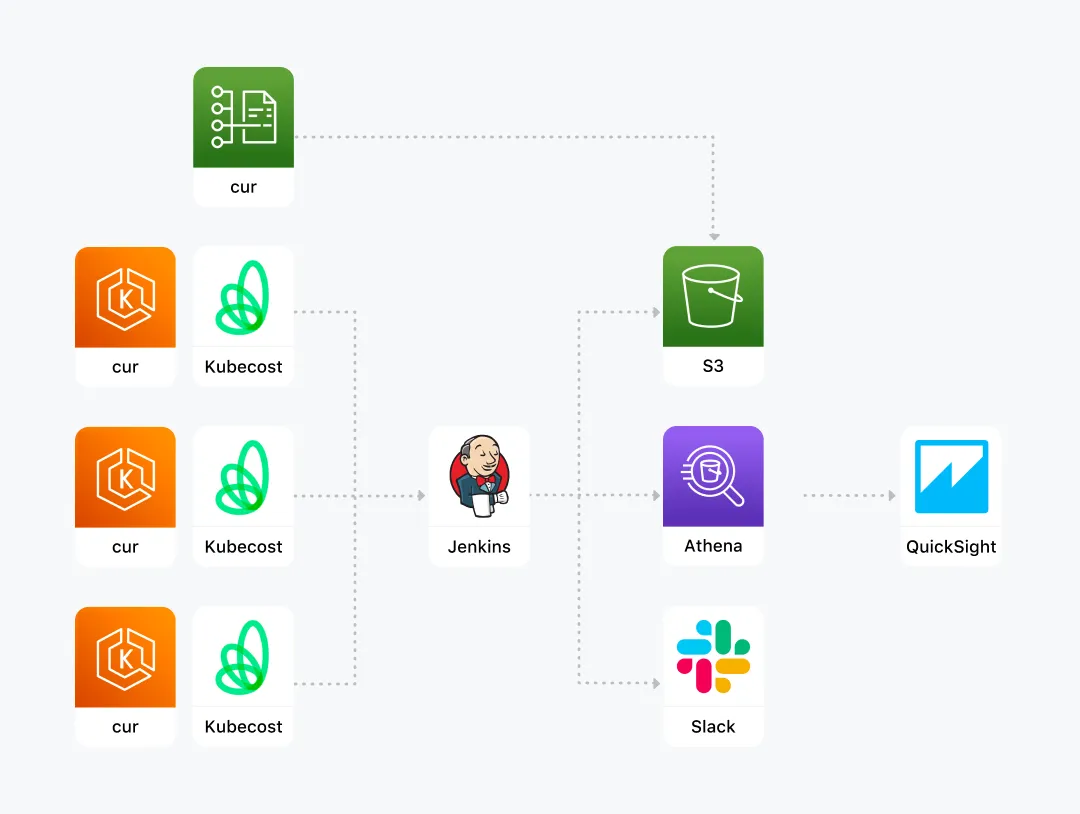
- AWS Cost & Usage Report(CUR) 데이터 구성
- EKS에 KubeCost 구성
- Amazon Athena 테이블 구성
- Amazon Athena view 테이블을 기반으로 Amazon QuickSight에서 가시화
- Billing data operation 자동화
우리는 이 순서로 가시화를 진행했어요. 이제부터 하나씩 알아볼게요!
Step 1. AWS Cost & Usage Report(CUR) 데이터 구성
AWS CUR 데이터는 시간 단위로 AWS에서 사용하는 모든 resource에 대한 비용 및 사용량 데이터에요. 매월 조직 규모에 따라 수백만에서 수십억 개의 데이터로 표현돼요. AWS CUR 생성할 때는 아래 옵션들을 통해 특정 S3에 데이터를 내보냈어요. 이 글에서는 직접 설정한 옵션을 한번 살펴볼게요.
상세한 생성 가이드는 AWS Document - Creating Cost and Usage Reports에서 확인할 수 있어요.
CUR 데이터 옵션
- Include resource IDs : True
- resource 단위로 세분화된 비용을 확인하는 옵션이에요.
- Report data time granularity : Hourly
- 시간당 데이터를 확인하는 옵션이에요.
- Compression type : Parquet
- Parquet는 csv, gzip보다 더 작고, Amazon Athena를 통해서 데이터를 확인할 수 있는 압축 방식이에요.
이렇게 설정을 해주면 AWS CUR 데이터가 S3에 쌓이게 돼요!
Step 2. EKS에 KubeCost 구성
KubeCost는 cpu, memory 등의 컴퓨팅 자원 사용량을 기반으로 실제 Pod가 사용한 비용을 알 수 있도록 하는 오픈소스에요.
설치는 helm chart를 이용해 운영하는 모든 클러스터에 적용했어요. KubeCost의 데이터를 AWS CUR 데이터와 통합하기 위해 지속적으로 KubeCost api를 이용해 pod 별 사용량을 수집하고, S3로 보내고 있어요.
[KubeCost url]/model/allocation?window=[start date],[end date]&aggregate=pod&accumulate=true
ex) https://localhost/model/allocation?window=2023-11-21T00:00:00Z,2023-11-21T01:00:00Z&aggregate=pod&accumulate=true
조회 조건
- window : 시작 시간, 종료 시간
- aggregate : 집계 단위
- accumulate : 출력된 데이터를 aggregate 단위로 합산
예시처럼 api를 호출하면 pod 단위의 사용량 정보를 아래와 같이 받을 수 있어요. 더 많은 데이터가 있지만 우리가 필요한 데이터만 정리했어요.
{
"code":200,"data":[
{
"[pod name]":{
"name":"[pod name]",
"properties":{
"cluster":"cluster-1",
"namespace":"service-group-a",
...
},
"start":"2023-11-21T00:00:00Z",
"end":"2023-11-22T00:00:00Z",
"totalCost":0.264564
...
}
},{
"[pod name]":{
"name":"[pod name]",
"properties":{
"cluster":"cluster-1",
"namespace":"service-group-b",
...
},
"start":"2023-11-21T00:00:00Z",
"end":"2023-11-22T00:00:00Z",
"totalCost":0.264564
...
}
}
]
}
이렇게 KubeCost에서 데이터를 받아왔다면, 1차 가공을 해서 S3에 적재를 할텐테 여기서 최대한 AWS CUR 데이터와 통합하기 쉬운 형태로 데이터를 구성했어요.
start cluster namespace podgroup pod cost
2023-11-01 00:00:00 test-cluster management jenkins jenkins-1 0.00398800
- start : 비용 발생 시간 (CUR의 시간 값)
- cluster : clsuter 구분자
- namespace : AWS의 serviceGroup Tag로 집계하기 위한 필드
- podgroup : AWS의 service Tag로 집계하기 위한 필드로 deployment, statefulset 등의 명을 넣었어요
- pod : AWS의 resource Level
- cost : 비용
이런 형태로 데이터를 가공해 S3에 k8s/year=[연]/month=[월]/ path 구조로 적재해서 데이터를 Amazon Athena에서 Query 할 때 파티션 구성까지 고려 했어요.
Step 3. Amazon Athena 테이블을 구성하자.
우리는 위 두 작업을 통해서 가시화에 필요한 모든 데이터 구성을 완료했어요. 그러면 이 데이터들을 가지고 Amazon Athena에서 테이블을 만들어 Amazon QuickSight를 통해 가시화를 해볼게요.
S3에 있는 두 가지 데이터가 있어요.
- CUR : aws 비용 데이터
- KubeCost : k8s 비용 데이터
우선 CUR 데이터 구성을 위해 초기 테이블을 만들어요. 전체 필드 중에서 우리가 실제로 사용하는 필드 위주로 한번 살펴볼게요.
전체 테이블을 구성하는 링크는 AWS Document - Amazon Athena Cost and Usage reports Billing data 확인할 수 있어요.
CREATE EXTERNAL TABLE finops.table_cur_main(
bill_billing_entity string, -- 비용이 AWS 마켓 플레이스 비용인지 AWS 비용인지 구분하는 필드
product_category string, -- product category
product_servicecode string, -- product servicecode
pricing_public_on_demand_cost double string, -- SP/RI가 적용된 경우 실제 청구 비용이 아니라 온디맨드 비용 필드
line_item_usage_start_date timestamp, -- 비용 발생 시간
line_item_product_code string, -- Amazon EC2 등 AWS product code
line_item_usage_type string, -- 사용량 세부정보
line_item_usage_account_id string, -- AWS 계정 id
line_item_resource_id string, -- resource id
line_item_unblended_cost double, -- 실제 청구 비용
line_item_line_item_type string, -- 요금 유형. Credit, Fee 등등
savings_plan_offering_type string, -- sp 유형 정보
resource_tags_user_name string, -- tag 정보
resource_tags_user_phase string,
resource_tags_user_service string,
resource_tags_user_service_group string,
resource_tags_user_eks_cluster_name string,
resource_tags_user_eks_nodegroup_name string,
...
)
PARTITIONED BY ( -- s3 path 기준으로 partution을 나누는 옵션
`year` string,
`month` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION 's3://[버킷 명]/aws/kakaopaysec-cur/kakaopaysec-cur/'
-- CUR이 저장된 s3 path
TBLPROPERTIES (
"parquet.compression"="SNAPPY", -- 데이터 압축 방식 및 암호화 처리
'has_encrypted_data'='false')table_cur_main 테이블을 생성한 다음 아래 명령어로 파티션을 추가해 줘야 해요. 파티션 추가 작업은 매월 jenkins job을 이용해 스케줄링을 자동화했어요.
MSCK REPAIR TABLE finops.table_cur_mainRI/SP가 적용된 비용 때문에 정확한 사용량을 할 수 없는 한계가 있었어요. 이를 해결하기 위해서, 원본 데이터에서 RI/SP가 적용된 resource에 대해서 on-demand 비용으로 바꿔서 집계할 수 있도록 view 테이블을 만들었어요. 테이블 생성을 간략하게 살펴볼게요.
CREATE OR REPLACE VIEW "view_cur_day" AS
SELECT
region
, usageaccountid
, "date_trunc"('day', usagestartdate) usagestartdate
, productcode
, usagetype
, resourceid
, sum(public_ondemand_cost) AS public_ondemand_cost
, month
, CASE
WHEN tag_phase IS NULL THEN 'null'
WHEN tag_phase = '' THEN 'null'
ELSE tag_phase END AS tag_phase
, CASE
WHEN tag_service_group IS NULL THEN 'null'
WHEN tag_service_group = '' THEN 'null'
ELSE tag_service_group END AS tag_service_group
, CASE
WHEN tag_service IS NULL THEN 'null'
WHEN tag_service = '' THEN 'null'
ELSE tag_service END AS tag_service
, CASE
WHEN tag_eks_cluster_name IS NULL THEN 'null'
WHEN tag_eks_cluster_name = '' THEN 'null'
ELSE tag_eks_cluster_name END AS tag_eks_cluster_name
FROM
(
SELECT
line_item_usage_start_date AS usagestartdate
, product_region AS region
, line_item_product_code AS productcode
, line_item_usage_type AS usagetype
, line_item_usage_account_id AS usageaccountid
, line_item_resource_id AS resourceid
, CASE -- (1) RI/SP가 적용된 경우 on demand 비용 필드를 보도록 하는 작업.
WHEN line_item_line_item_type = 'DiscountedUsage'
or (
product_category = 'Savings Plan Covered Usage'
AND (
savings_plan_offering_type = 'ComputeSavingsPlans'
or savings_plan_offering_type = 'EC2InstanceSavingsPlans'
)
)
THEN pricing_public_on_demand_cost
ELSE line_item_unblended_cost END AS "public_ondemand_cost"
, resource_tags_user_phase AS tag_phase
, resource_tags_user_service AS tag_service
, resource_tags_user_service_group AS tag_service_group
, resource_tags_user_eks_cluster_name AS tag_eks_cluster_name
,"concat"(year, '-', month) AS month
FROM
"finops"."table_cur_main"
WHERE ("concat"(year, '-', month) >= "date_format"("date_add"('month', -12, current_date), '%Y-%m'))
AND
line_item_line_item_type NOT IN ('SavingsPlanRecurringFee','SavingsPlanNegation','RIFee','Tax','EdpDiscount')
-- resource 사용 비용과 무관한 내용은 제외
AND NOT (
bill_billing_entity = 'Custom' AND line_item_line_item_type = 'Usage'
AND "regexp_like"(line_item_product_code, 'Prepayment')
) -- resource 사용 비용과 무관한 내용은 제외
AND (line_item_product_code NOT IN ('AWSSupportEnterprise','EDP Program', 'OCB AWSSupportEnterprise','OCBPremiumSupport'))
-- resource 사용 비용과 무관한 내용은 제외
)
GROUP BY resourceid, usageaccountid, region, "date_trunc"('day', usagestartdate),
productcode, usagetype, tag_service, tag_service_group,
tag_phase, tag_eks_cluster_name, month이렇게 view를 구성해서, RI/SP로 인해 확인할 수 없었던 실제 사용량을 확인할 수 있었어요. 추가로, 세금이나 할인 등 사용량 파악에 불필요한 요소들은 제거했어요.
불필요한 요소들
- EDP 할인 금액
- Support Enterprise 비용
- Tax
이제 KubeCost 데이터를 표현할 테이블을 구성해 볼게요.
CREATE EXTERNAL TABLE table_kubecost_main (
start timestamp,
cluster varchar(128),
namespace varchar(128),
podgroup varchar(128),
pod varchar(128),
cost decimal(38,16)
)
PARTITIONED BY (
year string,
month string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION 's3://[버킷 명]/k8s/'KubeCost 테이블은 아주 간단해요. 이렇게 구성한 다음 마찬가지로 파티션을 추가해 줘요.
MSCK REPAIR TABLE finops.table_kubecost_main그런 다음 아래와 같이 최대한 CUR과 통합하기 쉬운 형태로 정리를 했어요.
CREATE OR REPLACE VIEW "view_kubecost_main" AS
SELECT
start,
cluster,
namespace,
podgroup,
pod,
cost,
year,
"concat"(year, '-', month) AS month,
"date_trunc"('day', start) AS day
FROM finops.table_kubecost_main이제 CUR 데이터와 KubeCost 두 데이터를 합치는 테이블을 구성하면 Amazon Athena 작업은 끝나요.
CREATE OR REPLACE VIEW "view_cost_main" AS
SELECT
start as usagestartdate
, 'eks' as usageaccountid
, 'eks' as productcode
, cluster as usagetype
, namespace as tag_service_group
, podgroup as tag_service
, pod as resourceid
, cost as public_ondemand_cost
FROM "finops"."view_kubecost_main"
UNION ALL
SELECT
usagestartdate
, usageaccountid
, productcode
, usagetype
, tag_service_group
, tag_service
, resourceid
, public_ondemand_cost
FROM "finops"."view_cur_day"
WHERE tag_eks_cluster_name = 'null'이 테이블에서 정의한 몇 가지 기준이 있어요.
- tag_service_group : AWS service group tag와 EKS의 namespace와 같은 Level로 구성했어요.
- tag_service : service tag는 podgroup과 동일하게 구성 했고 podgroup은 deployment, statefulset, rollout 이름으로 구성했어요.
- resourceid : AWS resuorce와 EKS Pod와 동일한 Level로 구성했어요.
이렇게 두 데이터를 통합하고, CUR 데이터에서 EKS 비용은 제외하기 위해 tag_eks_cluster_name에서 값이 있는 경우 비용에서 제외했어요. 이렇게 하면 SP/RI가 제외 돼 실제 사용량 기반의 데이터와 거의 유사한 형태를 만들 수 있고, EKS 비용을 가시화할 수 있어요.
여기서 몇 가지 metadata를 만들어 데이터를 더 보기 좋게 구성할 수 있어요. 우리가 구성한 데이터를 살펴보면!
- service group 별 담당 팀, 담당 부서 테이블
- 부서별 비용을 정리하는 용도로 사용하기 위해 넣었어요.
- AWS Tag 보정 데이터
- AWS Tag 작업은 시간이 오래 걸리고 부담되는 작업이다 보니 변경하고 싶은 값을 Tag를 직접 수정하는 것이 아닌 데이터를 보정해 사용해 빠르게 가시화를 할 수 있었어요.
Step 4. Amazon Athena View 테이블을 기반으로 Amazon QuickSight에서 가시화.
마지막으로 Amazon QuickSight를 이용해서 우리가 보기 쉬운 형태로 만들 수 있어요. Amazon QuickSight는 여러 서비스와 통합이 가능해요. CUR 데이터의 refresh 주기가 있었고, KubeCost도 일 1회 update 하고 있어서, Amazon Athena 데이터를 매일 1회 refresh 해 최신화된 데이터를 유지하고 있어요.
실제로 통합하는 내용은 AWS Document - Creating a dataset using Amazon Athena data에 잘 나와 있어요.
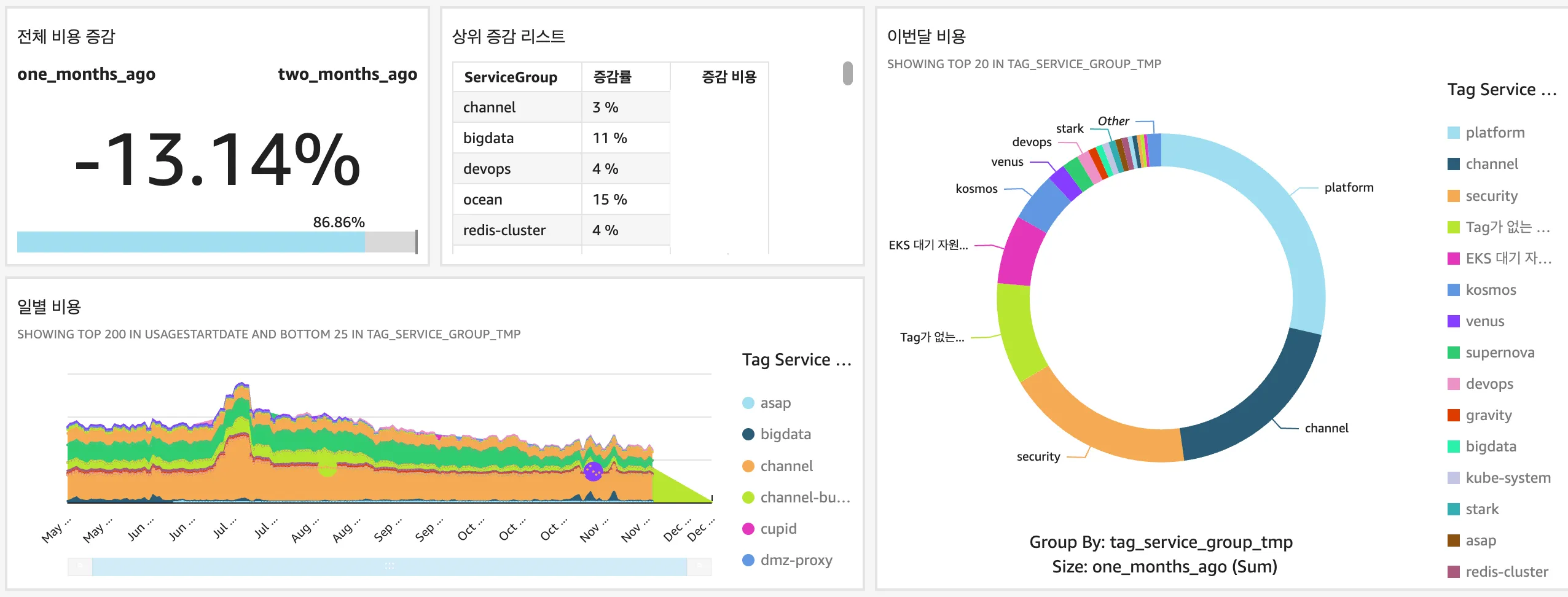
Step 5. 그 외의 작업
여기까지 많은 조직들이 어려워하는 AWS 비용 가시화 작업에 대해서 이야기했어요. 이 데이터 기반으로 카카오페이증권에서는 많은 작업을 통해서 운영 및 모니터링 자동화, 비용 효율화를 가지고 가고 있어요. 자동화하여 관리하는 작업 리스트들을 살펴보면!
- Wallga(카카오페이증권의 CI/CD 플랫폼) 기반으로 EKS Graviton node를 코드 수정 없이 자동 전환
- AWS managed service를 k8s 기반 내재화 (Redis, Kafka, OpenSearch 등)
- Weekly/Monthly billing reporting
- EBS lifecycle 자동화
- SnapShot lifecycle 자동화
- AMI lifecycle 자동화
- Prometheus, CloudWatch 기반 Instance type recommend
- EKS pod QoS recommend
- EKS node right sizing
- Pod time base scheduling(프로모션, 출/퇴근 시, 공휴일 등 Scale in/out)
- RI/SP recommend
이 작업을 통해 클라우드 비용을 최적화 할 수 있었어요.
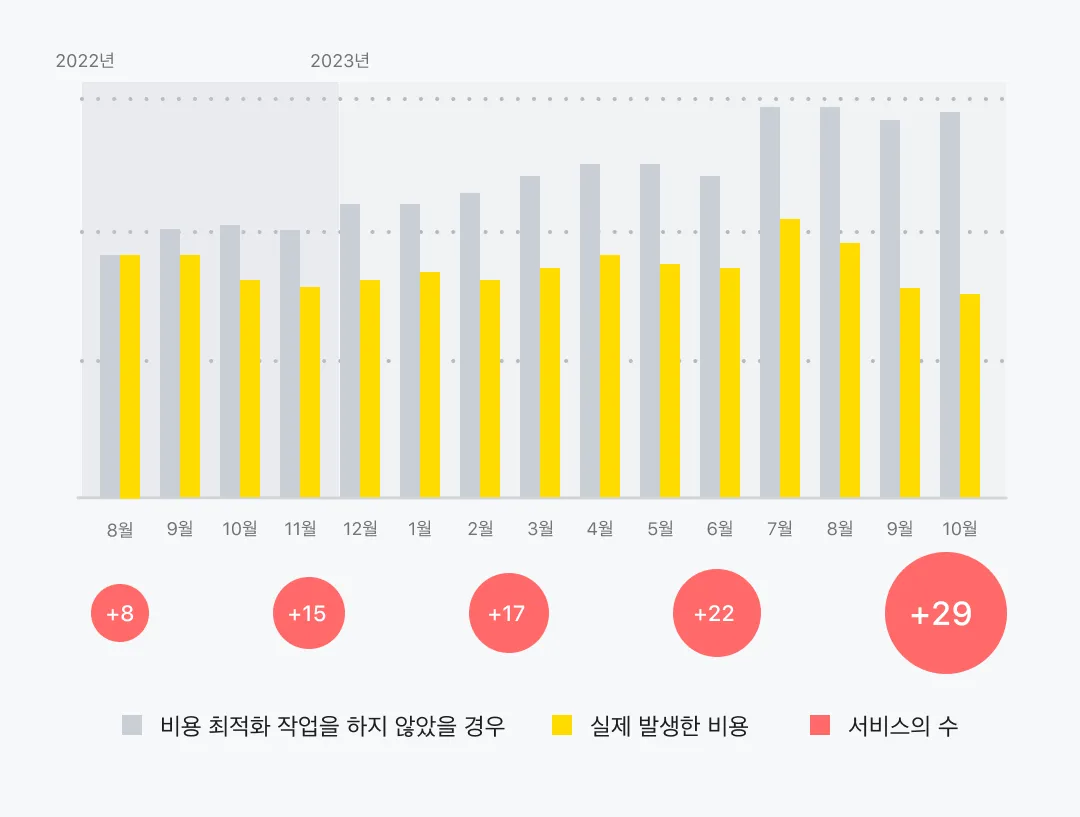
아래 실제 카카오페이증권에서 비용 최적화 작업을 하지 않았을 경우의 예상 비용과 실제 발생한 비용 그래프에요. 2023년 10월 기준으로 약 50%의 비용을 절감 할 수 있었고, 비용 관리 시작하던 시점인 2022년 9월 대비 실제 클라우드에서 운영하는 서비스는 4배 가까이 늘었어요.
마치며
지금까지 카카오페이증권에서 클라우드 비용을 가시화하는 과정에 대해서 살펴봤어요. 간략하게 요약을 해보면!
- AWS CUR, KubeCost의 비용 데이터를 S3로 적재
- S3 데이터를 가공하기 위한 Amazon Athena 테이블 구성
- Amazon QuickSight를 통한 가시화
또한 가시화 작업을 기반으로 구성된 데이터를 실제 업무에서 활용 할 때, 개발자 분들의 업무 영향을 최소화 하기 위해 노력했어요. 하나의 예로 Wallga(카카오페이증권의 CI/CD 플랫폼)에서 Pod의 최근 사용량 기반으로 배포 전 적절한 pod QoS 설정이 자동으로 처리되도록 구현하여 Pod의 최적화가 지속해서 관리되도록 구현하고 있어요.
이런 과정들을 거치면서 처음에는 막연했지만 단계적으로 하나씩 풀어가면서 가시화했어요. 그리고 가시화 이후에는 내부에서 운영하는 플랫폼들을 기반으로 빠르게 아키텍처를 수정해 나가면서 비용을 클라우드답게, 최적화된 비용으로 사용 할 수 있었어요. 같은 고민을 하는 많은 조직에도 도움이 되었으면 좋겠어요!
이후로, 카카오페이증권 DevOps 팀이 Kubernetes 환경에서 운영하는 플랫폼들을 만들어가는 과정과 노하우 등 많은 분이 관심 가질만한 주제로 계속 공유할 예정이에요. 앞으로도 카카오페이증권의 DevOps 팀이 성장하는 모습에 많은 관심 부탁드려요!










![[if(kakaoAI)2024] 카카오페이증권의 Kubernetes 지능형 리소스 최적화 (feat. Dr.Pym Project 공유)](/_astro/thumb.CGBHxK2H_ZWFBjN.webp)