시작하며
안녕하세요. 저는 카카오페이증권의 인프라플랫폼팀에서 DBA 업무를 담당하고 있는 데런입니다. 저희 팀은 카카오페이증권의 안정적인 서비스에 기반이 되는 네트워크, 시스템, 데이터베이스와 같은 인프라를 Cloud, On-premise 환경에서 구성하고 제공하는 업무를 수행하고 있고 인프라를 보다 신뢰성 있고 자동화된 플랫폼으로 만들고자 힘쓰고 있습니다.
카카오페이증권은 전통적인 금융시스템, 그중에 증권이라는 도메인에서 다양한 도전들을 하고 있는데요. 지난 한 해에 카카오페이증권 기술조직의 주요 미션은 단연 MSA1였습니다.
증권사에서 MSA를 어디까지 확장할 수 있을까?
카카오페이증권에서는 이미 의심의 단계를 넘어 확신의 단계에 이르렀습니다. MSA를 확장함에 따라 여러 데이터베이스에 분산 저장된 데이터의 활용을 위해 CDC2의 중요성도 함께 부각되고 있는데요. 카카오페이증권은 이미 GoldenGate(Oracle), jdbcAdapter(Altibase) 등의 CDC 도구들을 활용 중에 있고 향후에는 오픈소스 기술 내재화라는 카카오페이증권의 기술 방향성에 따라 Kafka를 주축으로 한 CDC Pipeline을 구성하는 것을 목표로 하고 있습니다. Kafka로 CDC Pipeline을 구축함에 따라 CDC의 안정성과 확장성이 확보되고 복잡한 CDC 솔루션들을 하나로 정리할 수 있는 이점을 가져갈 수 있습니다.
이번 포스트의 주제는 Oracle에서 MongoDB로의 CDC Pipeline을 구축했던 저희의 경험에 관한 건데요. 이 생소한 조합의 CDC를 구축한 목적은 사용자 데이터의 실시간 분석을 위해 Oracle → MongoDB의 CDC 데이터 파이프라인이 필요했기 때문입니다. RDBMS에서 NoSQL로의 CDC가 흔치 않은 케이스 이기도 하고 MongoDB에 Oracle의 초기데이터를 적재하는 작업도 병행되어야 했기 때문에 생각보다 신경써야 할 부분이 많았습니다.
CDC 파이프라인 아키텍쳐
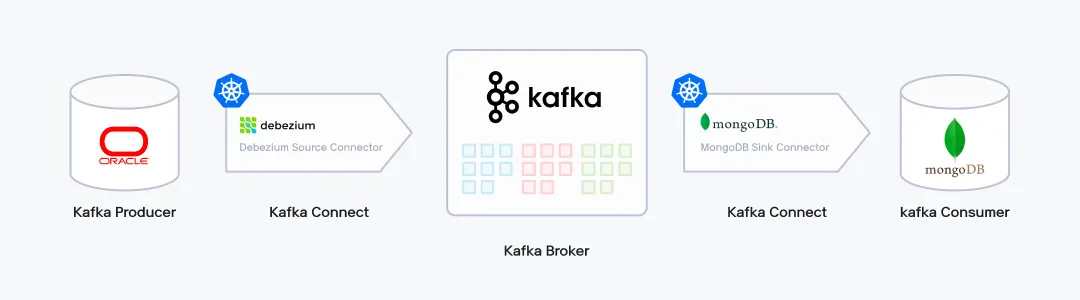
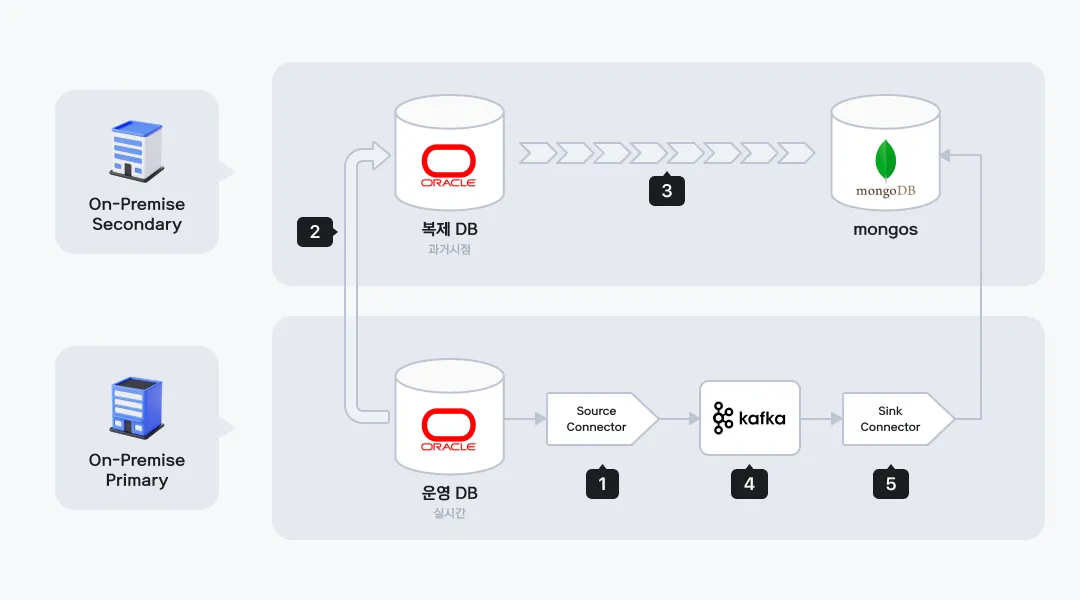
Kafka CDC
저희는 Kafka 기반으로 CDC Pipeline을 구축했습니다. 여기서 Kafka Producer의 데이터 소스인 Oracle과 Kafka Broker인 Kafka Cluster는 IDC 물리서버에 이미 구축되어 있었고 Kafka Consumer의 Target DB인 MongoDB는 이번 CDC 구축을 위해 추가로 물리서버에 구축했습니다.
반면 Kafka Connect는 나머지 구성 요소들과는 다르게 Kubernetes에 구성했는데요. 컴퓨팅 자원의 활용효율 증가, 배포 단순화 등의 Kubernetes가 갖는 여러 장점이 있겠지만 저희가 Kafka Connect를 Kubernetes에 구성한 핵심적인 이유는 확장성 때문입니다. 증권사 도메인 특성상 예상치 못한 이벤트들이 종종 발생하는데요. Kubernetes에 구성함으로써 갑작스러운 부하 급증에도 유연하게 상황에 대처할 수 있습니다.
복잡한 Kubernetes Manifest File 들을 손쉽게 관리할 수 있게끔 Helm 패키지 매니저를 사용하여 환경을 셋팅하였고, 배포는 자동화된 Wallga플랫폼3으로 진행하였습니다. Wallga CI/CD 파이프라인은 Github - Jenkins - ArgoCD로 연결되어 있는데요. 카카오페이증권의 Devops팀이 구축한 Wallga플랫폼에 대해 궁금하시다면 "카카오페이증권의 DevOps 문화와 플랫폼 엔지니어링"을 참고해주시기 바랍니다!!
Source Connector는 요즘 CDC 솔루션으로 각광받고 있는 Debezium을 사용했습니다. Debezium은 여러 Database를 지원하고 있어서 활용성면에서 뛰어나고 신규버전이 지속적으로 Release 되고 있어서 제품에 신뢰가 갔습니다. 그리고 Document도 상세하게 잘 되어 있어서 테스트하기에도 수월했습니다. Sink Connector는 고민할 것 없이 MongoDB 벤더에서 자체 제공하는 Connector를 사용했습니다. 아래 그림은 Kafka CDC 파이프라인의 아키텍쳐입니다.
Sink Connector에서 Debezium이 생성한 이벤트 메시지를 처리하기 위해서는 CDC Handler라는 게 필요한데요. 만약 이 CDC Handler가 없다면 Sink Connector는 Debezium이 생성한 메시지를 그대로 Consume 하기만 할 뿐 CDC에 대한 처리를 전혀 할 수 없습니다. 현재 MongoDB Sink Connector는 MongoDB Source Connector, Debezium, Qlik Replicate에 대한 CDC Handler를 지원하고 있다고 합니다.

그리고 이 Debezium CDC Handler를 위한 Source DB로는 MongoDB, Postgres, MySQL을 지원한다고 되어 있습니다. 엇? 그럼 Oracle은요?? 아쉽게도 Debezium CDC Handler가 아직 Oracle은 지원하고 있지 않는 것 같습니다.

여길 보면 Debezium CDC Handler는 커스터마이징이 가능하다 하는데요. 그럼 Oracle에 대한 부분을 직접 만들어야 하는 걸까요?
안내되어 있는 대로 Debezium CDC Handler의 Source Code를 한 번 살펴보겠습니다. Path를 보면 sink > debezium > rdbms 로 되어 있고 이 부분에 rdbms에 대한 처리를 어떻게 할 것인지 정의되어 있습니다.
# Debezium CDC Handler
...
├── cdc
│ ├── CdcHandler.java
│ ├── CdcOperation.java
│ ├── debezium
│ │ ├── DebeziumCdcHandler.java
│ │ ├── OperationType.java
│ │ ├── mongodb
│ │ │ ├── ChangeStreamHandler.java
│ │ │ ├── MongoDbDelete.java
│ │ │ ├── MongoDbHandler.java
│ │ │ ├── MongoDbInsert.java
│ │ │ └── MongoDbUpdate.java
│ │ └── rdbms
│ │ ├── RdbmsDelete.java
│ │ ├── RdbmsHandler.java
│ │ ├── RdbmsInsert.java
│ │ ├── RdbmsUpdate.java
│ │ ├── mysql
│ │ │ └── MysqlHandler.java
│ │ └── postgres
│ │ └── PostgresHandler.java
...그리고 하위 디렉토리를 보면 mysql과 postgres가 있는데요. 각 디렉토리에서 MysqlHandler.java와 PostgresHandler.java 소스를 한 번 보겠습니다.
// src/main/java/com/mongodb/kafka/connect/sink/cdc/debezium/rdbms/mysql/MysqlHandler.java
package com.mongodb.kafka.connect.sink.cdc.debezium.rdbms.mysql;
import java.util.Map;
import com.mongodb.kafka.connect.sink.MongoSinkTopicConfig;
import com.mongodb.kafka.connect.sink.cdc.CdcOperation;
import com.mongodb.kafka.connect.sink.cdc.debezium.OperationType;
import com.mongodb.kafka.connect.sink.cdc.debezium.rdbms.RdbmsHandler;
public class MysqlHandler extends RdbmsHandler {
// NOTE: this class is prepared in case there are
// mysql specific differences to be considered
// and the CDC handling deviates from the standard
// behaviour as implemented in RdbmsHandler.class
public MysqlHandler(final MongoSinkTopicConfig config) {
super(config);
}
public MysqlHandler(
final MongoSinkTopicConfig config, final Map<OperationType, CdcOperation> operations) {
super(config, operations);
}
}// src/main/java/com/mongodb/kafka/connect/sink/cdc/debezium/rdbms/postgres/PostgresHandler.java
package com.mongodb.kafka.connect.sink.cdc.debezium.rdbms.postgres;
import java.util.Map;
import com.mongodb.kafka.connect.sink.MongoSinkTopicConfig;
import com.mongodb.kafka.connect.sink.cdc.CdcOperation;
import com.mongodb.kafka.connect.sink.cdc.debezium.OperationType;
import com.mongodb.kafka.connect.sink.cdc.debezium.rdbms.RdbmsHandler;
public class PostgresHandler extends RdbmsHandler {
// NOTE: this class is prepared in case there are
// postgres specific differences to be considered
// and the CDC handling deviates from the standard
// behaviour as implemented in RdbmsHandler.class
public PostgresHandler(final MongoSinkTopicConfig config) {
super(config);
}
public PostgresHandler(
final MongoSinkTopicConfig config, final Map<OperationType, CdcOperation> operations) {
super(config, operations);
}
}완전히 동일하네요!! 껍데기만 정의되어 있습니다. 추가적으로 사용자가 정의하고자 하는 부분들에 대해 구현이 가능하도록 껍데기만 만들어뒀나 봅니다. 그렇기 때문에 MysqlHandler, PostgresHandler 둘 중 아무거나 가져다 써도 관계없겠습니다.
Json Converter VS Avro Converter
Kafka Connect 구성요소로 Converter라는 게 있는데, 이 Converter는 Kafka Connector와 Kafka Broker 사이에서 데이터를 Serialization/Deserialization 하는 역할을 합니다. 간단히 말해 Converter는 Kafka Connector와 Kafka Broker 사이에 데이터를 어떻게 주고받을 것인지를 정의하는 역할을 한다고 이해하시면 되겠습니다. Kafka Connector를 위한 Converter로는 일반적으로 JsonConverter와 Avro Converter가 가장 많이 사용되고 있습니다.
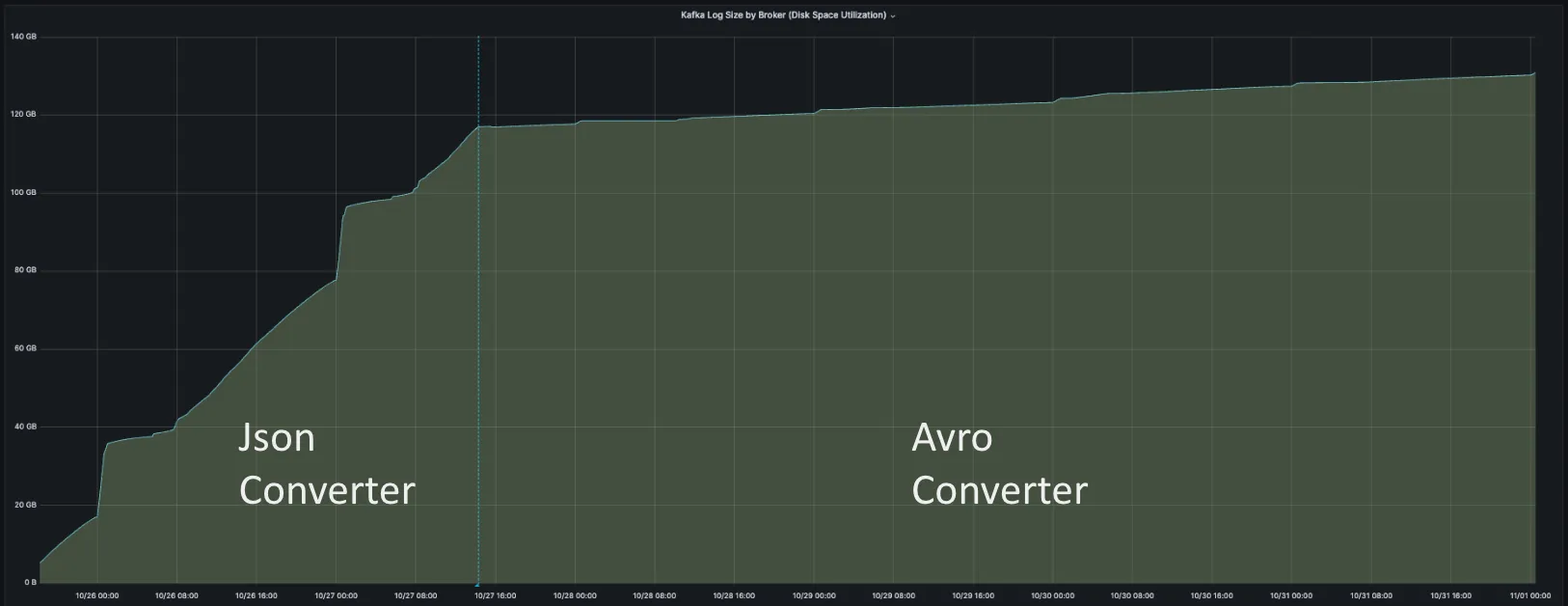
아래 차트는 Json Converter와 Avro Converter를 썼을 때 Kafka Log Size의 증가 폭을 보여주고 있습니다. 한눈에 보기에도 Json Converter의 로그 증가 폭이 Avro Converter 보다 확연히 더 커 보입니다. 그 이유는 Json Converter는 메시지에 스키마를 포함하고 있기 때문인데요. RDBMS 특성상 스키마 변경은 빈번히 발생하지 않고 초당 처리되는 쿼리 건수는 많기 때문에, 매번 메시지에 스키마를 포함하는 Json Converter의 방식은 적어도 RDBMS CDC에 한해서는 굉장히 비효율적이라 할 수 있겠습니다.
반면에 Avro Converter는 Schema Registry라는 별도의 스키마 저장 공간에 스키마를 저장하여 저장 효율이 좋습니다. 그리고 주고받는 데이터의 양이 적다 보니 Json Converter 보다 OS 자원 사용에도 유리하고 성능도 좋습니다.
그래서 저희는 Avro Converter를 쓰기로 결정했습니다.
Json Converter에서도 아래의 kafka connect property 설정을 통해 스키마를 생략할 수 있지만, 그렇게 되면 브로커에 데이터만 적재될 뿐 스키마 정보가 없기 때문에 Sink Connector는 CDC에 있어 제 역할을 하지 못하게 됩니다.
- key.converter.schemas.enable
- value.converter.schemas.enable
CDC 구축 전략
이렇게 초기적재와 실시간 변경분을 분리해서 MongoDB에 데이터가 적재되도록 했습니다.
- 초기 데이터는 복제 DB를 통해 적재
- 새로 들어오는 Change Event는 CDC 데이터 Pipeline을 통해 적재
그리고 작업은 다음의 단계로 진행되었습니다.
- Source Connector 생성
- Oracle 복제 DB 생성
- MongoDB에 초기 데이터를 적재
- Consumer Group을 생성 및 Offset을 설정
- Sink Connector 생성
작업 절차
1. Source Connector 생성
Helm 차트의 Kafka Connector 설정에 해당하는 부분에 CDC 대상 테이블을 추가하여 Debezium Source Connector를 배포해 주었습니다. 배포 완료 후 Kafka Connect가 정상적으로 올라오면 Topic은 Table과 1:1의 관계로 생성이 됩니다. 그리고 각 Topic 별로 retention(메시지 보관일자)를 설정해 줄 수 있는데, 전체적인 작업기간이 예상보다 길어질 수 있으므로 넉넉하게 30일로 변경해 주었습니다.
/kafka/bin/kafka-configs.sh --bootstrap-server host_url:port_num --alter --entity-type topics --entity-name topic_name --add-config retention.ms=2592000000⚠ snapshot.mode
Debezium Source Connector의 snapshot.mode는 반드시 schema_only로 설정해 줍니다. schema_only로 설정하면 Debezium은 새로 들어온 Change Event부터 메시지를 생성하게 됩니다. 만약 snapshot.mode를 initial로 설정할 경우 Oracle DB에 저장된 모든 데이터를 읽어오려고 시도하기 때문에 운영 중인 Oracle DB에 부담을 줄 수 있고, Kafka Connect도 OOM 발생으로 비정상 종료될 수 있습니다.
2. Oracle 복제 DB 생성
운영 DB 및 서비스에 부담을 주지 않기 위해 Primary 가 아닌 Secondary 환경에 복제 DB를 생성해 주었습니다.
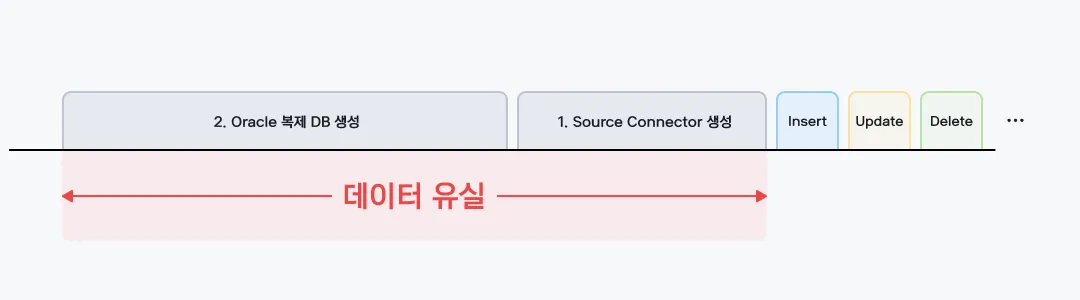
작업 순서도 중요한데요!! 만약에 1번(Source Connector 생성) 작업을 2번(Oracle 복제 DB 생성) 작업 이후에 하게 되면 1번 작업 이후로 Change Event들이 Kafka Broker에 적재되므로 1, 2번 작업 간의 데이터가 유실되기 때문에 작업 순서에 유의해야 했습니다.
3. MongoDB에 초기데이터 적재
MongoDB에 초기데이터를 적재해 줍니다. 이 부분은 내용이 조금 길기 때문에 아래 부분에 별도로 작성하도록 하겠습니다.
4. Consumer Group 생성 및 Offset 설정
Kafka Consumer는 Consumer Group 별로 메시지를 Consume 합니다. 그렇기 때문에 Sink Connector가 특정 시점(복제 DB 생성 시점)부터 메시지를 Consume 하도록 하기 위해서는 Consumer Group이 미리 생성되어 있어야 합니다. 그리고 그 Consumer Group의 Offset이 설정되어 있어야 합니다.
아래는 Consumer Group 생성과 Offset 설정의 예시입니다.
# retention 변경 예시
/kafka/bin/kafka-configs.sh --bootstrap-server host_url:port_num --alter --entity-type topics --entity-name topic_name --add-config retention.ms=2592000000
# Consumer Group Offset 수정 예시
/kafka/bin/kafka-consumer-groups.sh --bootstrap-server host_url:port_num --group group_name --reset-offsets --to-datetime '2023-10-27T15:30:00.000' --all-topics --execute
# Consumer Group Offset 조회 예시
/kafka/bin/kafka-consumer-groups.sh --bootstrap-server host_url:port_num --list5. Sink Connector 생성
앞선 단계에서 설정해 놓은 Consumer Group과 동일한 Group ID로 Sink Connector를 생성해 줍니다. Sink Connector가 생성되면 미리 설정해 놓은 Offset부터 메시지를 Consume 하게 됩니다.
⚠ auto.offset.reset
만약에 Consumer Group의 Offset이 설정되어 있지 않다면 auto.offset.reset 설정값에 따라 메시지를 어디서부터 Consume 할지 결정하게 됩니다. CDC는 메시지 기반, PK 기반으로 동작하기 때문에 중복 메시지 처리에 대한 connector 설정이 되어 있다면 메시지를 중복 수신해도 무방하긴 하지만 굳이 명백한 Offset을 두고 메시지를 중복 수신할 필요는 없겠죠?
- earliest: Kafka 브로커에 있는 대상 Topic들의 가장 이른 시점 부터 Event Message를 Consume
- latest: 새로 들어온 Event Message부터 Consume
Sink Connector 생성 후에 미리 구성해 놓았던 모니터링 도구 Grafana와 akHQ, Kafka UI를 활용해서 모니터링했습니다.
Oracle to MongoDB 데이터 초기 적재
이번 프로젝트에서 작업한 초기 적재 대상 데이터는 다음과 같은 특징이 있었습니다.
- 6TB
- 130억 건
- 12개 테이블, 그중 3개가 90% 이상 차지
Relational Migrator
처음에 MongoDB 벤더에서 제공하는 RDBMS to MongoDB Migration Tool인 Relational Migrator를 생각했습니다. Relational Migrator는 익숙한 웹브라우저 환경에 직관적인 UI로 구성되어 있어 쉽고 편리하게 사용 가능합니다. 설치와 실행도 간단합니다. 그리고 Data Migration 뿐만 아니라 Schema Recommendation, Code Generation 등의 유용한 기능도 제공하고 있습니다. 하지만 테스트해본 결과 이번 프로젝트에서 Relational Migrator를 활용하기에는 다음의 이유로 어려움이 있겠다 판단했습니다.
- 느린 성능
- 병렬 실행 어려움
- 초대형 테이블에 적합성 의문
그리고 Relational Migrator Installation 문서를 보면 Migration의 대상이 되는 데이터의 규모에 따라 세 가지 Deployment Model이 소개되어 있는데 그중 큰 사이즈의 Job에 적합한 것으로 보이는 Kafka Model은 아직 “not generally available” 하다라고 기재되어 있습니다. 그래서 추후에 제품이 제대로 준비가 되었을 때 다시 사용해 보기로 하고, 다른 방법을 찾아보기로 했습니다.
Talend Open Studio + mongoimport
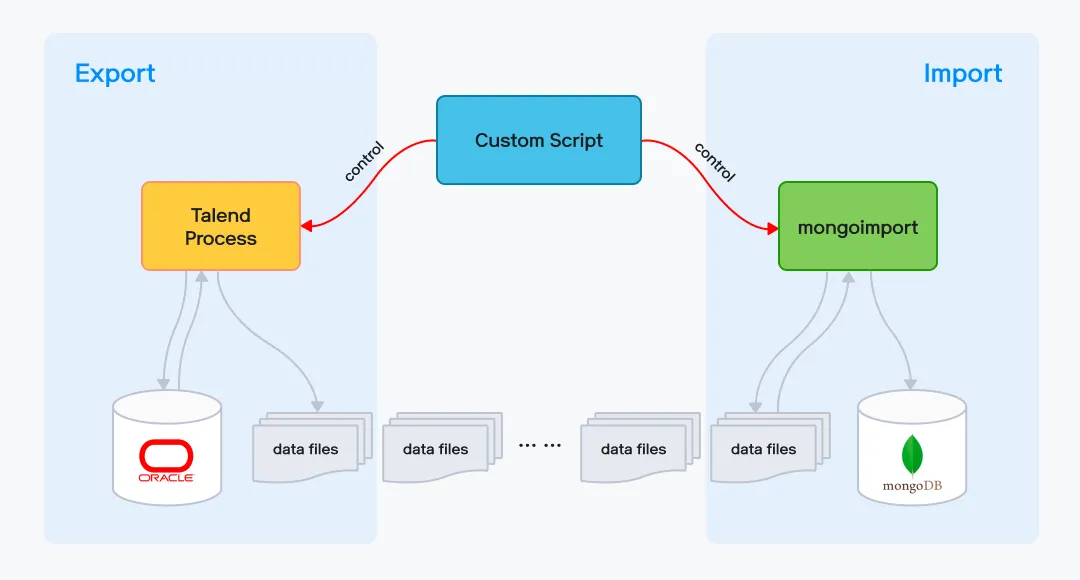
다른 방법으로 Oracle의 대용량 데이터를 MongoDB로 안정적으로 이관하기 위해 ETL 툴을 생각했습니다. 결론부터 말씀드리자면 Talend Open Studio라는 툴을 사용했는데, 그 이유는 이미 몇 차례 사용 경험으로 제품 자체가 익숙했고 이번 프로젝트에서 필요로 하는 기능들을 모두 갖추고 있다고 판단했기 때문입니다. OpenSource이고 러닝커브가 높지 않기 때문에 무료 ETL 툴을 고민하고 계신다면 Talend Open Studio를 추천드립니다. Talend에서 MongoDB도 지원하기 때문에 Talend 하나만 가지고 모든 걸 처리할 수도 있었지만 Export Tool, Import Tool을 분리해서 사용하기로 했습니다. Export에는 앞선 설명처럼 Talend Open Studio를, Import에는 MongoDB 벤더에서 제공하는 CLI Tool인 mongoimport를 사용했습니다. 이렇게 Tool을 분리한 이유는 Export의 처리 성능이 Import 보다 상대적으로 느렸기 때문입니다. Export와 Import 프로세스를 분리함으로써 한정된 자원에서 Talend Process의 비중을 높여 더 빠르게 전체적인 이관을 마무리할 수 있었습니다.
동작 과정은 그림과 같이 Export, Import가 별개로 동작합니다. Talend Process는 Oracle로부터 데이터를 읽어와서 file로 떨어뜨리고, mongoimport는 이 file을 읽어서 MongoDB에 적재합니다. 그리고 이 두 가지 동작을 제어하기 위해 중간에 bash와 python으로 작성한 Custom Program을 두었습니다.
대용량 데이터 Import/Export
테이블 한 개에 TB 단위에 달하는 데이터를 어떻게 에러나 지연 발생 없이 안정적으로 추출할 수 있었을까요? 대용량 테이블은 일반적으로 날짜 컬럼 기준으로 Range 파티셔닝을 합니다. 여기서 파티션 키인 날짜 컬럼을 포함해서 인덱스를 생성해 주면, 파티션 pruning이 되어 불필요한 파티션 스캔을 하지 않기 때문에 빠르게 데이터를 조회할 수 있습니다. 그렇기 때문에 아무리 용량이 큰 테이블일지라도 파티션과 인덱스 구성이 잘 되어 있다면 조회에 큰 무리가 없습니다. 다행히 이번 대상 테이블들도 날짜 컬럼 기준으로 Range 파티셔닝 되어 있었고 인덱스도 잘 생성되어 있었습니다.
추출한 데이터를 MongoDB에 집어넣을 때는 어떤 포맷으로 넣어야 할까요? 혹시 앞서 설명드린 Debezium CDC Handler 기억하시나요? Debezium CDC Handler는 MongoDB에 데이터를 다음의 포맷으로 적재합니다. Oracle에서의 PK가 MongoDB에서는 _id라는 unique field에 embedded 되어 들어갑니다. 마찬가지로 초기 적재된 데이터도 Debezium CDC Handler가 핸들링할 수 있도록 하기 위해서는 이와 동일한 포맷으로 적재해 주어야 합니다.
{
"_id": {
"c1": 1
},
"c2": "hello",
"c3": "world",
"c4": "test",
"c5": null,
"c6": "1111",
"report_dt": "20231010"
}CSV 파일에서 PK에 “_id.”이라는 prefix를 넣어주면 위와 같은 포맷으로 적재할 수 있는데요. 그런데 막상 테스트를 해보니 포맷은 CDC Handler가 생성하는 것과 동일하게 적재는 되지만 문제가 좀 있습니다. 첫 번째로 기존 데이터 타입이 보장되지 않습니다. Oracle에서 VARCHAR2 타입인 데이터가 MongoDB에 String 타입이 아닌 Int64로 저장되었습니다. 두 번째로 Null값 처리에 문제가 있습니다. Oracle에서 Null 값인 데이터가 MongoDB에서는 공백문자 ""로 저장되었습니다.
| _id.c1 | c2 | c3 | c4 | c5 | c6 | report_dt |
|---|---|---|---|---|---|---|
| 1 | hello | world | test | 1111 | 20231010 | |
| 2 | hello | world | test | N | 2222 | 20231011 |
| 3 | hello | world | test | Y | 3333 | 20231012 |
CSV로는 달리 방법이 없어 동일한 데이터를 가지고 JSON으로 만들어 테스트해 보았는데, 테스트 결과 JSON에서는 동일한 문제가 발생하지 않았습니다. 그래서 다른 방도가 없어 CSV 대신 JSON으로 데이터를 Import 해야만 했습니다. JSON으로 데이터를 Import 하기 위해서는 Oracle에서 데이터를 내려받을 때 JSON Parsing이 되어야 합니다. 그런데 아마 JSON Parsing에 경험이 있다면 공감하실 겁니다. JSON Parsing은 많은 양의 메모리를 필요로 하고, 빠른 성능을 기대하기 어렵습니다. 그래서 Export에 병목이 생기게 되었고, 이것이 Import/Export 프로세스를 분리한 결정적 이유가 된 겁니다. 느린 건 여러 개의 프로세스를 띄워서 병렬처리하면 해결할 수 있는데, 메모리가 문젭니다. 테이블 용량이 너무 크다 보니 하루치 데이터 건수만 뽑아봐도 5백만 건이 넘었고 export 프로그램을 실행시키면 잠시 돌다가 금세 OOM으로 죽었습니다.
그래서 저희는 이 5백만의 데이터를 또 잘게 쪼개줬습니다. 웹화면 조회에 흔히 사용되는 페이징 처리 기법을 적용했는데요. 아래 예시와 같이 페이징 처리 했습니다. 날짜 컬럼 REPORT_DT 컬럼은 파티션 키이고, [REPORT_DT, C1] 컬럼은 Unique Index입니다.
데이터를 모두 읽을 때까지 다음의 작업을 반복합니다.
- 가장 안쪽 인라인뷰 A에서 하루치의 ROWID와 ROWNUM을 추출합니다. WHERE 조건절과 ORDER BY의 REPORT_DT, C1 컬럼에 대한 정보가 모두 Index에 존재하기 때문에 Table에 Access 할 필요가 없고, Index는 이미 정렬되어 있는 형태로 존재하기 때문에 조회에 오래 걸리지 않습니다.
- 인라인뷰 A의 result set에서 처음 20,000 건만 뽑아 ROWID 추출하여 인라인뷰 B를 만들어 줍니다. 그리고 다음번 실행에는 그다음 20,000 건을 뽑아냅니다. 예컨대 (1부터 20,000건), (20,001부터 20,000 건), (40,001부터 20,000건)과 같이 데이터를 뽑아내는 겁니다.
- 인라인뷰 B의 ROWID와 테이블 T의 ROWID와 조인해 줍니다. 그냥 ROWNUM만 가지고 추출할 수 있는데 이렇게 복잡하게 ROWID를 이용하는 이유는, ROWNUM으로만 했을 때는 뒤로 갈수록 쿼리가 느려지기 때문입니다. 물리 주소인 ROWID를 이용하면 Table에 빠르게 Access 할 수 있습니다.
SELECT *
FROM TB_TEST1 T,
(
SELECT A.RID
FROM
(
SELECT AA.RID, ROWNUM SEQ
FROM
(
SELECT ROWID RID
FROM TB_TEST1 T1
WHERE REPORT_DT >= ? AND REPORT_DT < ?
ORDER BY REPORT_DT, C1
) AA
) A
WHERE 1=1
AND A.SEQ >= 20000 * ?
AND ROWNUM <= 20000
) B
WHERE T.ROWID = B.RID;그리고 페이징 처리를 위해 반복문을 돌면서 실행되는 유사 쿼리에 대해 Hard Prepare가 발생되는 부분을 개선하기 위해, 한 세션에서 유사 쿼리에 대해 실행계획을 공유할 수 있는 Oracle의 파라미터를 사용했습니다. 사실 이 부분은 Talend에서 Bind 변수 처리를 할 수 있다면 필요 없는 부분인데 어떻게 하는지 방법을 찾지 못해서 이렇게 차선책을 적용한 겁니다. 그런데 다행히 기대한 대로 잘 동작해 줬습니다.
ALTER SESSION SET CURSOR_SHARING=FORCE;Talend Job Design
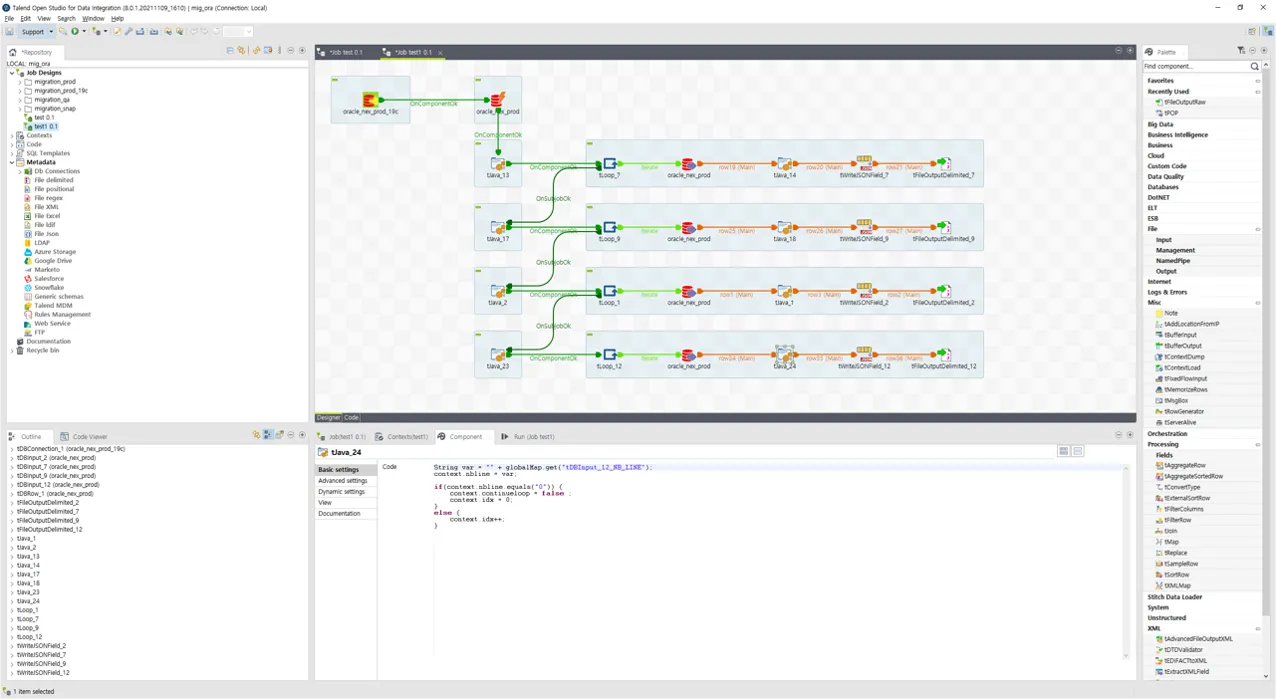
앞서 설명드린 내용 중 Export에 해당하는 부분을 Talend Open Studio로 구현했는데요. 전체적인 구성은 이렇습니다. 이건 한 개 테이블에 대한 예시인데요. 이런 식으로 테이블 개수만큼 구성해 주면 됩니다.
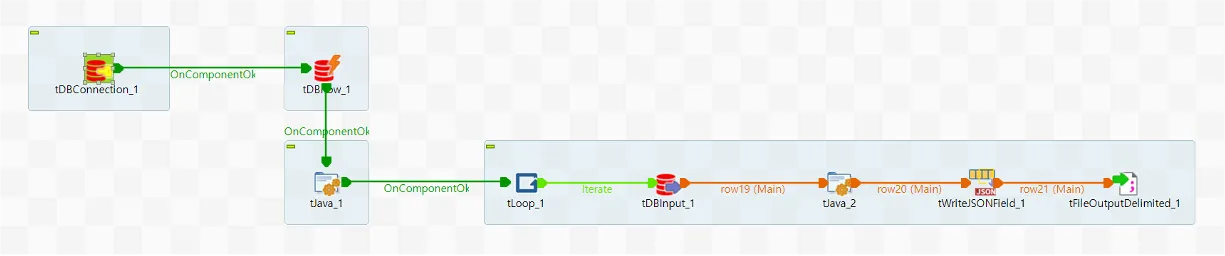
◼️ tDBConnection_1
DB의 Connection을 정의합니다. 이 Component 없이도 tDBInput 등의 컴포넌트에서 개별 정의하여 사용할 수도 있지만, 그렇게 되면 기존 Connection을 이용하지 못하고 매번 Connection을 새로 생성하기 때문에 낭비가 있습니다.
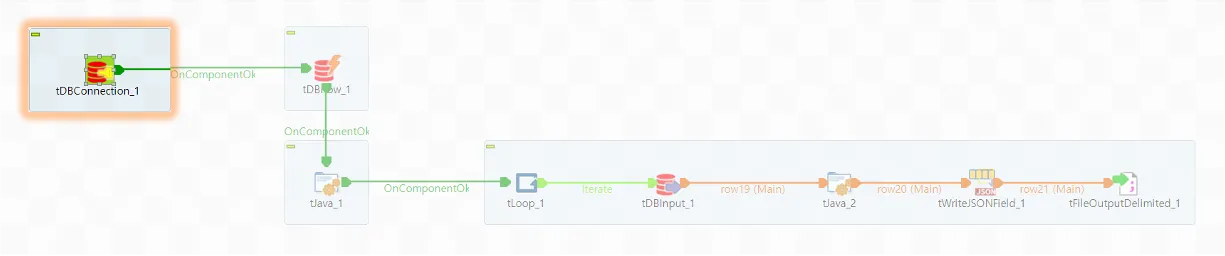
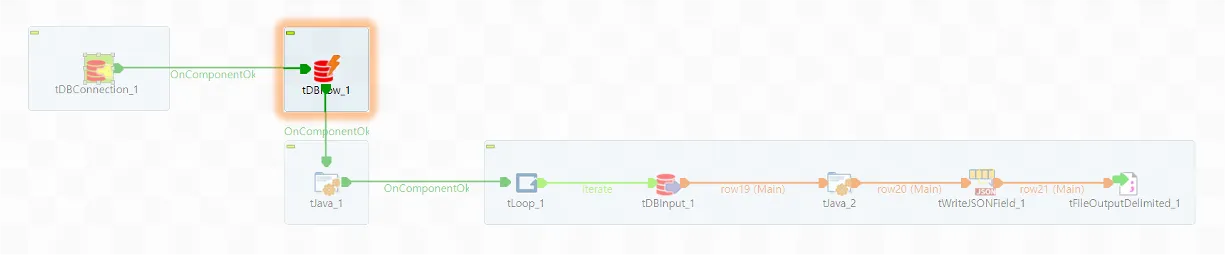
◼️ tDBRow_1
DB에 접속할 Session의 Session 옵션을 설정합니다. 여기서는 CURSOR_SHARING만 설정해 주었습니다.
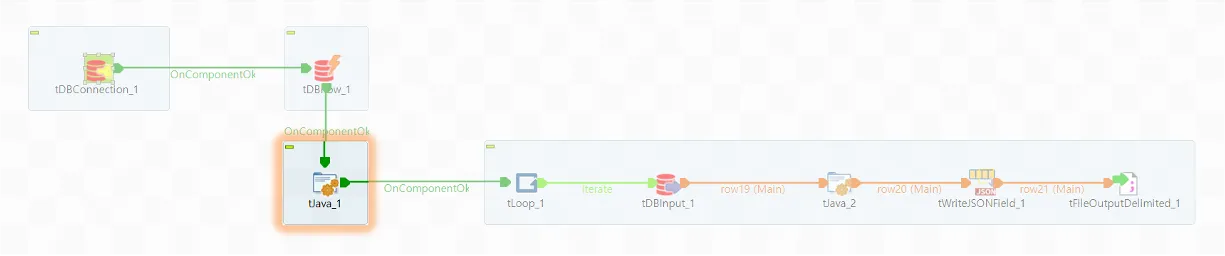
◼️ tJava_1
Loop 문에서 활용할 변수를 정의해 줍니다.
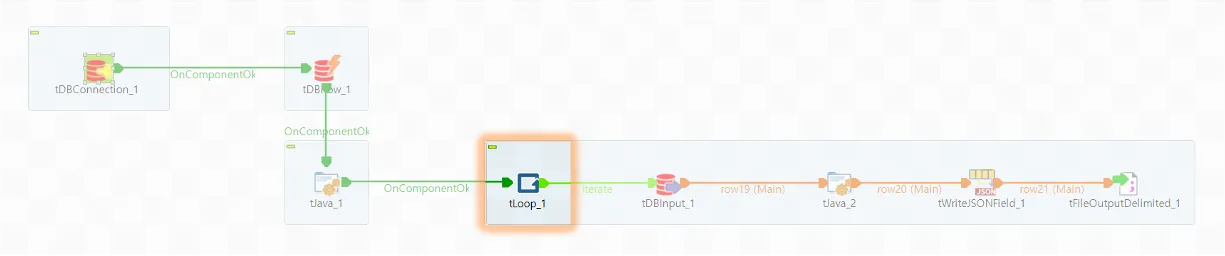
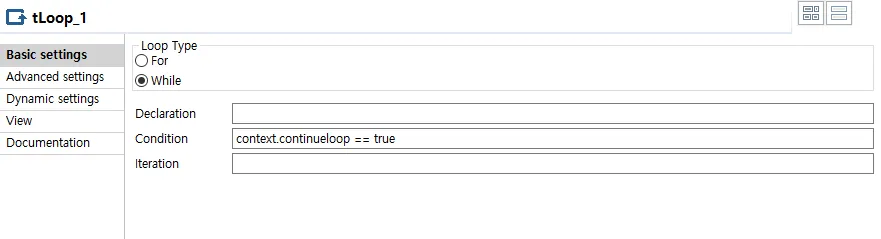
context.continueloop = true;◼️ tLoop_1
앞서 정의한 변수를 사용하여 Loop문을 정의해 줍니다.
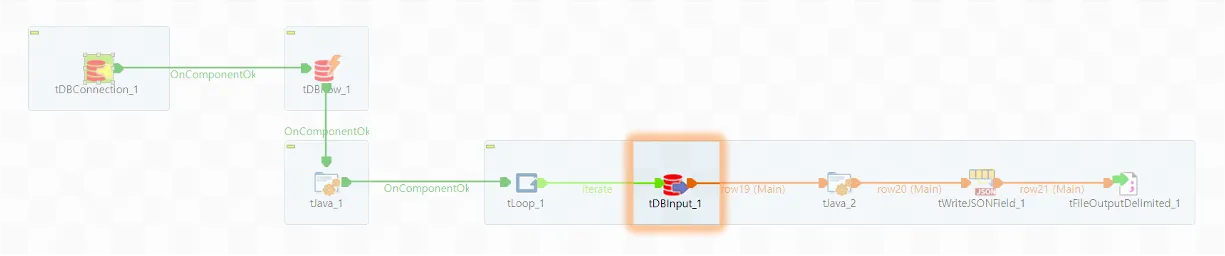
◼️ tDBInput_1
Oracle에서 데이터를 추출하는 부분입니다. 앞서 설명드린 Paging 기법에 따라 한 번에 모든 데이터를 읽어오지 않고 일부의 데이터만 읽어옵니다.
"SELECT *
FROM TB_TEST1 T
, (
SELECT A.RID
FROM
(
SELECT AA.RID, ROWNUM SEQ
FROM
(
SELECT ROWID RID
FROM TB_TEST1 T1
WHERE REPORT_DT >= '"+ context.v_from + "' AND REPORT_DT < '" + context.v_to + "'
ORDER BY REPORT_DT, C1
) AA
) A
WHERE 1=1
AND A.SEQ >= " + context.blocksize + " * " + context.idx +
" AND ROWNUM <= " + context.blocksize +
" ) B
WHERE 1=1
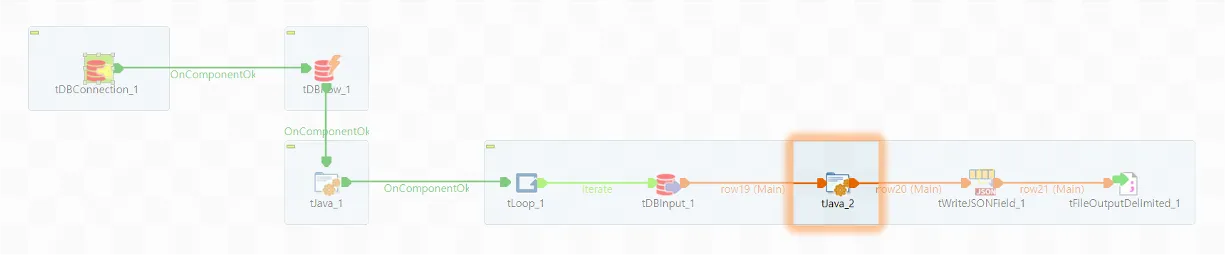
AND T.ROWID = B.RID"◼️ tJava_2
while condition을 체크합니다. Oracle에서 더 이상 읽어올 데이터가 없는 경우 Loop문을 빠져나갑니다.
String var = "" + globalMap.get("tDBInput_1_NB_LINE");
context.nbline = var;
if(context.nbline.equals("0")) {
context.continueloop = false ;
context.idx = 0;
}
else {
context.idx++;
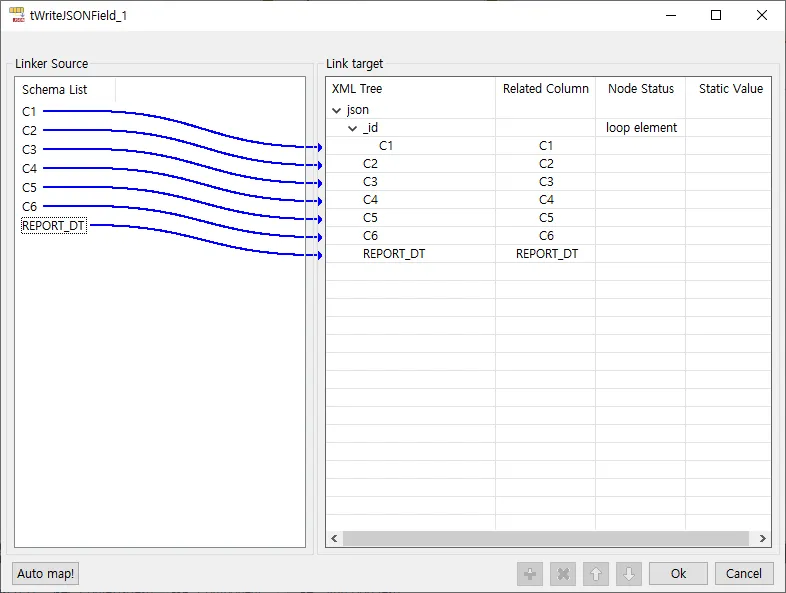
}◼️ tWriteJSONField_1
Oracle에서 추출한 데이터를 가지고 JSON Parsing을 합니다. PK는 _id 컬럼에 embedded 되게 넣어 줍니다.
◼️ tFileOutputDelimited_1
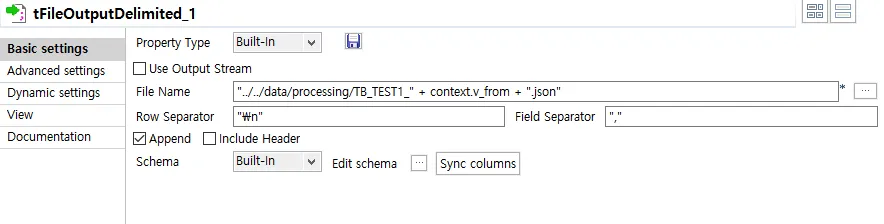
Parsing 된 JSON을 파일에 씁니다.
마치며
MongoDB의 WiredTiger 스토리지 엔진의 데이터 압축률이 좋다 보니 Oracle 대비 저장 공간이 절반 이하로 줄었습니다.
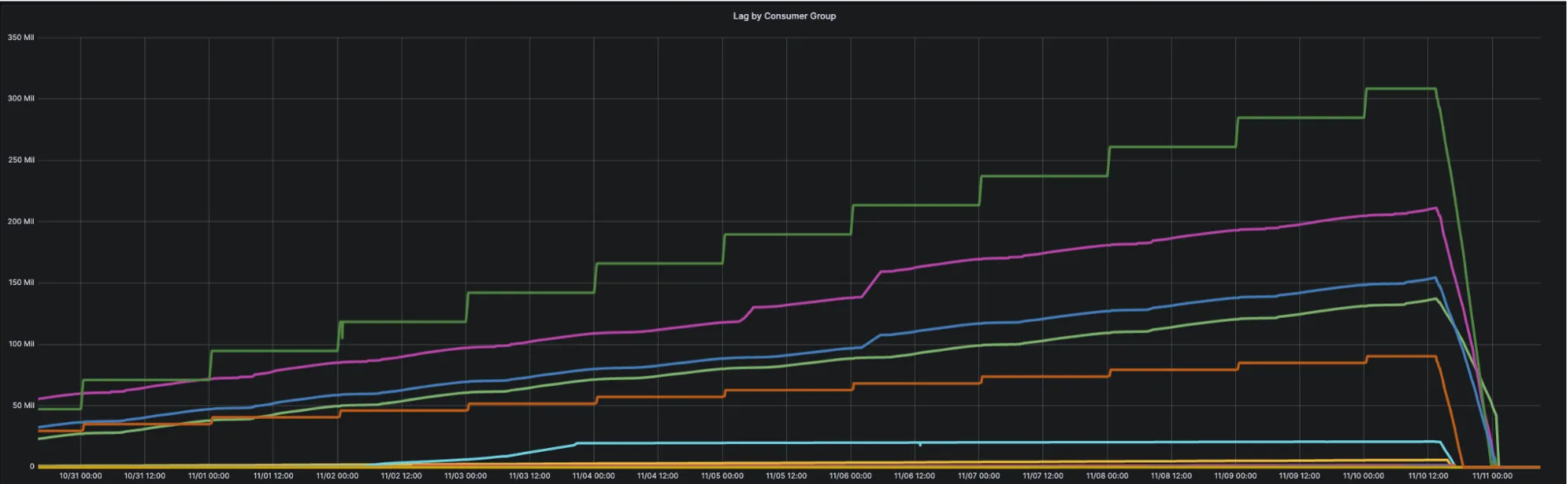
작업 기간은 오라클 기준 6TB의 초기 데이터를 적재하는데 9일, 그리고 이 9일간의 change event에 대한 lag을 해소하는데 12시간이 걸렸습니다. 전체 작업 시간이 길다 보니 중간에 예상치 못한 문제가 발생하지는 않을지, 혹은 서비스에 영향을 미치지 않을지에 대한 우려가 있었지만 다행히 큰 이슈 없이 무사히 잘 마무리되었습니다. 그리고 지난 10월 말 프로젝트 종료 후 현재까지 정상적으로 잘 운영되고 있습니다. 현재 저희는 어떻게 lag을 더 줄일 수 있을까, 어떻게 향후에 더 편하게 Topic을 추가할 수 있을까, 어떻게 Oracle과 MongoDB의 데이터 일치 여부를 체크할 수 있을까 등의 고민을 하고 있습니다.
카카오페이증권에서는 Oracle 뿐만 아니라 저희 MSA의 Main DB인 MySQL에서도 동일한 구조의 CDC Pipeline을 구축하여 데이터를 활용하고 있는데요. 이 부분에서 드릴만한 팁들이 또 조금 있을 것 같습니다. 이 내용은 추후에 새로운 포스트를 통해서 찾아뵙도록 하겠습니다.
긴 글 끝까지 읽어 주셔서 감사합니다.
참고 자료
- https://www.mongodb.com/docs/kafka-connector/current/sink-connector/fundamentals/change-data-capture
- https://github.com/mongodb/mongo-kafka
- https://debezium.io/documentation/reference/stable/connectors/oracle.html
- https://www.mongodb.com/docs/relational-migrator
- https://help.talend.com/r/en-US/8.0/open-studio-user-guide
Footnotes





![[if(kakaoAI)2024] 카카오페이증권의 Kubernetes 지능형 리소스 최적화 (feat. Dr.Pym Project 공유)](/_astro/thumb.CGBHxK2H_ZWFBjN.webp)