![[if kakao 2022] ML 모델 학습 파이프라인 설계 (feat. MLOps 플랫폼)](/_astro/thumb.Dc_4_pap_ACvPj.webp)
시작하며
🔗 if(kakao) 발표 영상 보러 가기: 카카오페이 MLOps 적용기 (feat. AWS)
안녕하세요, 카카오페이 MLOps TF에서 MLOps 플랫폼 개발업무를 맡고 있는 레이첼입니다. 올해 if(kakao)에서 카카오페이 MLOps 적용기 (feat. AWS) 발표를 진행했는데요. 발표에서 다룬 내용을 기술 블로그를 통해서도 공유하고자 인사드립니다.
카카오페이에는 이상 거래 탐지 시스템(FDS: Fraud Detection System), 개인신용평가(CSS: Credit Scoring System), 유저프로파일링(페이프로파일) 등에 사용하는 다양한 AI/ML 모델이 있습니다. 다양한 모델을 프로덕션으로 서빙하기 위한 여러가지 번거로움이 있었는데요. 모델 개발 후 모델별로 서빙 서버와 피처 테이블을 각각 만들고, 다른 프로젝트의 새로운 모델이 추가되면 또 다시 서빙 서버와 피처 테이블을 별도로 구축하여 서빙했습니다. 새로운 모델을 추가하거나 모델 업데이트가 필요한 경우 피처 테이블과 모델 서빙 서버를 다시 중복 개발하는 일이 많고 표준화하여 구축하지 않았기 때문에 피처 데이터 관리와 모델 서빙 서버 운영이 복잡해지게 되었습니다.
또한 서버 개발자는 ML 모델 서빙 방법과 피처부터 모델의 라이프사이클, 모델 인퍼런스, 모델 모니터링까지 이해하고 개발을 진행해야 했고, 모델을 개발하는 데이터 사이언티스트 입장에서는 서버 개발에 모델을 어떻게 적용해야 하는지 관련 배경 지식들을 습득하고 진행해야 했습니다. 새로운 ML 모델이 만들어질 때마다, 재학습한 모델을 반영해야할 때마다 ML 모델을 서빙하는 개발 부채감은 커졌고, 개발자와 데이터 사이언티스트의 많은 리소스가 필요했습니다. 이러한 배경으로 모델 학습부터 관리, 서빙까지 모든 ML 모델이 공통으로 사용할 수 있는 MLOps 플랫폼을 정의하여 구축하게 되었습니다.
MLOps 플랫폼 구축에 앞서, MLOps의 컴포넌트를 피처 스토어, 모델 학습 파이프라인, 모델 서빙 3가지로 나누고 정의했습니다.
- 피처 스토어: 피처를 재사용할 수 있도록 생산/운영을 통합 관리하며, 모델 서빙에 필요한 피처를 빠르게 서빙할 수 있도록 피처 서빙까지 담당
- 모델 학습 파이프라인: 모델의 학습과 재학습, 모델 산출물 관리를 담당
- 모델 서빙: 학습이 완료된 모델을 서비스로 서빙하기 위한 서빙 서버를 담당
이 중 모델 학습 파이프라인을 어떻게 구축했는지 공유하고자 합니다.
모델 학습 파이프라인이란?
데이터가 시간이 지남에 따라 변경되면서 모델의 예측 성능 또한 떨어지기 때문에(Data Drift, Concept Drift의 영향) 지속적으로 모델을 재학습하여 모델 업데이트가 필요합니다. 모델을 자동으로 학습하고 학습한 결과와 산출물을 저장하는 전체적인 파이프라인을 모델 학습 파이프라인이라고 합니다.
카카오페이 MLOps에서는 모델 학습 파이프라인을 모델 학습 Workflow와 모델 레지스트리로 나누어 구성했습니다. 모델 학습 Workflow는 데이터 전처리 -> 모델 학습(train) -> 모델 평가(evaluation) -> 모델 저장의 Workflow를 구성하고 이 과정 중 모델 저장과정에서 학습된 모델을 모델 레지스트리에 등록하면 모델 산출물이 저장되고 모델 버전이 관리됩니다.
Workflow 플랫폼 선정 과정
모델 학습 Workflow를 운영하기 위한 Workflow 플랫폼 선정을 위해 Airflow, AWS SageMaker Pipelines, AWS Step Functions 을 비교 분석 해보았습니다.
Airflow
Airflow는 데이터 파이프라인을 위한 오픈소스 Workflow 관리 플랫폼으로 파이썬으로 개발되었으며, Workflow는 파이썬 스크립트로 만들 수 있습니다.
Airflow는 Workflow를 생성/운영할 수 있다는 점에서 모델 학습파이프라인으로 많이 사용됩니다. 하지만 Airflow는 데이터 Workflow 용도의 플랫폼으로 ML Workflow 용도로 최적화되어있지 않고, 플랫폼 운영 리소스도 필요하기 때문에 채택하지 않았습니다.
AWS SageMaker Pipelines
AWS SageMaker Pipelines는 end to end ML Workflow를 대규모로 생성, 자동화 및 관리할 수 있는 ML 모델을 위한 AWS의 CI/CD 서비스입니다.
ML 통합 플랫폼 서비스인 AWS SageMaker에서 제공하는 서비스로 모델 학습부터 서빙과 endpoint 생성/배포까지 할 수 있습니다. AWS SageMaker Pipelines는 이미 템플릿이 정해져 있고, 모델 코드에 맞게 파이프라인을 구성하므로 모델을 개발한 데이터 사이언티스트에게는 익숙합니다. 하지만 MLOps 운영자가 생성하고 관리하기에는 모델 코드에 대한 이해가 필요했습니다. 모델 학습 파이프라인 운영을 데이터 사이언티스트가 한다면 AWS SageMaker Pipelines를 채택했겠지만, MLOps 운영자가 운영하기에는 다소 불편함이 있을 것으로 예상해 채택하지 않았습니다.
AWS Step Functions
AWS Step Functions는 개발자가 AWS 서비스를 사용하여 분산 애플리케이션을 구축하고, 프로세스를 자동화하며, 마이크로서비스를 오케스트레이션하고, 데이터 및 ML 파이프라인을 생성할 수 있도록 지원하는 AWS의 시각적 Workflow로 서비스입니다.
Airflow와 AWS SageMaker Pipelines, AWS Step Functions 중 AWS Step Functions는 데이터 Workflow뿐만 아니라 서비스 Workflow 등 다양한 Workflow를 생성/관리할 수 있다는 점에서 조금 더 포괄적인 Workflow 플랫폼으로 볼 수 있었습니다. ML 관련하여 SageMaker와 연동할 수 있는 Python SDK를 제공하여 ML Workflow를 쉽게 구축할 수 있는 장점이 있고, 템플릿화하기에도 쉽기 때문에 모델 학습 Workflow 플랫폼으로 선택했습니다.
모델 레지스트리 선정
모델 산출물을 저장하고 모델 버전을 관리할 수 있는 모델 레지스트리를 선정하기 위해 요구 사항을 먼저 비교한 후 선정하였습니다.
모델 레지스트리의 요구 사항
카카오페이 MLOps에서 필요로 하는 모델 레지스트리의 요구 사항은 아래와 같습니다.
- 모델 학습(실험)후 결과(accuracy, f1-score, recall 등 Metric) 저장
- 모델 버전 관리
- 모델 아티팩트 저장/관리
- 모델 실험간 성능 비교 표/그래프 제공
MLFlow와 AWS SageMaker Model Registry 비교
모델 레지스트리로 사용할 수 있는 플랫폼으로 모델 라이프사이클 관리 플랫폼인 MLFlow와 모델 레지스트리 서비스인 AWS SageMaker Model Registry를 후보로 하여 비교하였습니다.
| MLFlow | AWS SageMaker Model Registry | |
|---|---|---|
| API 제공 여부 | O | O |
| 모델 버전 관리 | O | O |
| 모델 승인/기록관리 | O | O |
| 플랫폼 운영 난이도 | 중 | 하 |
MLFlow는 오픈소스라서 모델 레지스트리 기능으로 사용할 경우 운영리소스가 많이 필요할 것으로 예상되어, 모델 레지스트리 기능을 서비스로 제공하는 AWS SageMaker Model Registry를 모델 레지스트리로 선택했습니다.
AWS Step Functions과 AWS SageMaker Model Registry로 모델 학습 파이프라인 구축
AWS Step Functions와 AWS SageMaker Model Registry로 모델 학습 파이프라인을 구축하는 과정에 대해 설명드리겠습니다.
AWS Step Functions 관련 용어
AWS Step Functions Workflow는 다양한 방법으로 생성이 가능합니다.
- State Machine: Step Functions 내 Workflow
- Definition: State Machine (Workflow)가 동작하는 프로세스를 JSON 형태로 작성해 놓은 것으로 Amazon States Language라고 부르며 Workflow의 각 단계에서 어떤 프로스세스(시작, 종료, wait)를 수행할지, 어떤 리소스를 사용할지 작성하여 Workflow 생성 가능
AWS Step Functions Workflow 생성 방법
- Console에서 AWS 아이콘을 drag and drop하는 형태의 GUI form으로 생성 가능
- 직접 definition을 작성하여 생성 가능: AWS Step Functions 생성 방법
- AWS Step Functions Data Science SDK로 생성 가능
AWS Step Functions Workflow 템플릿
AWS Step Functions를 UI로 생성하면 사용자 에러가 발생할 수 있고 데이터 사이언티스트들마다 모델 학습 Workflow를 일일이 구성하기 번거로운 점을 고려하여, Python SDK를 사용하여 Step Functions Workflow를 구성하여 템플릿화했습니다. 이렇게 템플릿을 구성함으로서 데이터 사이언티스트는 모델 코드(preprocessing.py, train.py, evaluation.py)만 전달하고 모델 학습을 위한 설정 파라미터 값만 넣으면 자동으로 모델 학습 Workflow가 구축됩니다.
AWS Step Functions Workflow는 아래와 같이 Step으로 구성했습니다.
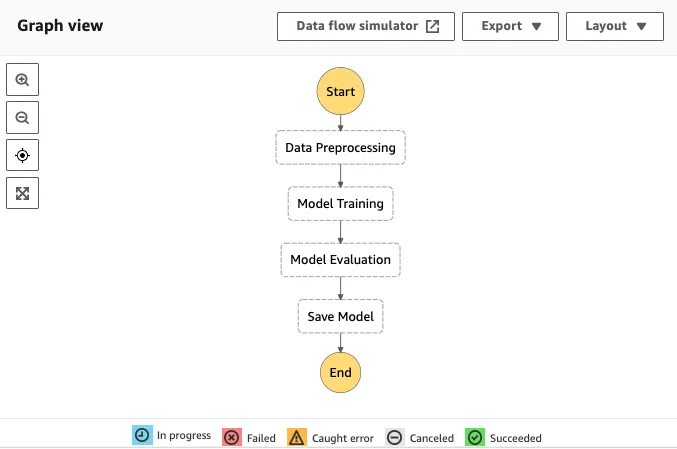
각 Step은 별도 스펙의 instance를 띄우고 해당 인스턴스 내부에서는 processor를 정의하여 컨테이너를 띄우고 Python 파일 등의 소스 코드를 실행하게 됩니다.1
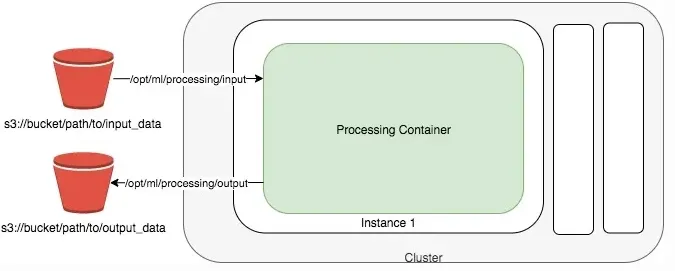
각 Step에서 실행되는 코드의 내용은 아래와 같습니다.
- Data Preprocessing: 피처스토어에서 피처데이터를 가져와서 피처 전처리하는 코드(preprocssing.py)를 실행합니다.
- Model Training: Data Preprocessing Step에서 전처리가 완료된 피처를 input으로 모델 학습 코드(train.py)를 실행합니다.
- Model Evaluation: Model Training Step에서 학습된 모델을 평가하는 코드(evaluation.py)를 실행하여 평가 결과를 S3에 저장합니다.
- Save Model: Model Evaluation Step에서 모델 평가 결과를 받아와 모델 성능이 일정 수준 이상일 경우 해당 모델을 모델 레지스트리에 등록합니다.
모델 학습/평가 기록 확인
학습과 평가 결과는 AWS SageMaker에서 확인할 수 있습니다. TrainingStep API로 모델 학습 Step을 생성/실행하면, AWS SageMaker Training jobs에서 모델 학습 로그와 결과를 확인할 수 있습니다. 모델 학습 이외의 데이터 전처리나 모델 평가 Step의 경우 ProcessingStep API로 Step을 생성/실행하면 AWS SageMaker Processing jobs 탭에서 실행로그를 확인할 수 있습니다. 모델 레지스트리에 등록한 모델은 AWS SageMaker Model Registry에서 모델 아티팩트 경로와 모델 성능을 확인할 수 있습니다.
AWS Step Functions 실행 로그
AWS Step Functions Workflow의 로그를 설정하면 다음과 같이 로그를 저장할 수 있습니다.
AWS CloudWatch logs에 저장 가능
각 State Machine의 Logs를 활성화하면, 실행 로그를 포함하여 로그 수집이 가능하며, 수집된 로그를 AWS CloudWatch Logs Insight를 통해서 SQL 기반으로 ad-hoc하게 조회할 수 있습니다. 또한, 여러 개의 Workflow에서 생성된 실행 로그들을 같은 AWS CloudWatch Logs Group으로 저장하면 통합적으로 로그를 관리할 수 있습니다.
AWS S3에 저장 가능
비용 절감 및 추후 세부적인 분석을 위해 AWS CloudWatch Logs를 AWS S3로 저장할 수 있습니다.
모델 학습 파이프라인 배포 프로세스
마지막으로 위에서 구축한 모델 학습 파이프라인을 데이터 사이언티스트들이 어떻게 사용하여 개발한 모델의 학습 Workflow를 생성하고 배포할 수 있는지 순서대로 설명드리겠습니다.
- 데이터 사이언티스트가 모델 개발 후 모델 관련 파일인 **train.py(모델 학습 코드), preprocessing.py(데이터 전처리 코드), evaluation.py(모델 평가 코드)**와 모델 설정 파일(config.yaml)을 git 저장소에 push합니다.
- Jenkins를 통해 git 저장소에 push한 파일을 AWS S3로 배포합니다.
- AWS S3에 새로운 파일이 들어온 것(PUT)을 감지한 AWS Lambda가 트리거되어 모델 설정 파일(config.yaml)에 정의된 값으로 AWS Step Functions Workflow를 생성하고 실행합니다.
- AWS Step Functions Workflow가 실행되어 모델 학습이 진행되고 모델 학습 결과가 AWS SageMaker Model Registry에 저장됩니다.
- AWS SageMaker Model Registry에서 데이터 사이언티스트와 모델 승인 권한자가 모델에 대한 평가 Metric을 확인하고 승인(Approve)을 하게 되면 모델 상태가 “Approved”로 변경되어 배포를 준비합니다.
- 모델 서빙 배포 시, AWS SageMaker Model Registry에서 모델을 다운로드하여 배포를 진행합니다.
마치며
다양한 모델을 서비스에 빠르게 적용할 수 있는 MLOps 플랫폼 구축을 하면서 MLOps 관련 사례가 많지 않아 구성 요소를 정의하고 구축하는데 많은 고민이 있었습니다. 저희와 같이 다양한 프로젝트의 ML 모델을 서빙해야 하는 분들에게 도움이 되었으면 좋겠습니다.
Footnotes
-
출처: Amazon SageMaker 가이드(https://sagemaker.readthedocs.io/en/stable/amazon_sagemaker_processing.html) ↩





![[if(kakaoAI)2024] 카카오페이증권의 Kubernetes 지능형 리소스 최적화 (feat. Dr.Pym Project 공유)](/_astro/thumb.CGBHxK2H_ZWFBjN.webp)




![[if kakao 2022] Batch Performance를 고려한 최선의 Aggregation](/_astro/thumb.MGIp4JrG_2cerCK.webp)
![[if kakao 2022] Batch Performance를 고려한 최선의 Reader](/_astro/thumb.CZPDDx8q_221xKf.webp)
![[if kakao 2022] 사례로 보는 모바일 자동화 테스트를 통한 모니터링](/_astro/thumb.Dvo2o5eU_95dIV.webp)
![[if kakao 2022] 카카오페이 iOS 웹뷰 소개, 그리고 세션에서 못다한 이야기](/_astro/thumb.DTsQI1Wt_Z1kMSMB.webp)
