![[if kakao 2022] Batch Performance를 고려한 최선의 Aggregation](/_astro/thumb.MGIp4JrG_2cerCK.webp)
시작하며
🔗 if(kakao) 발표 영상 보러 가기: Batch Performance 극한으로 끌어올리기
지난 게시글에서는 배치(batch processing, 일괄 처리)로 대량의 데이터를 읽을 때 어떻게 개발해야 할지 알아보았습니다. 이번 게시글에서는 대량 데이터를 Aggregation 하는 방법에 대해 알아보고자 합니다. 개발자들은 Aggregation 즉, 집계를 해야 하는 상황에 배치로 개발을 많이 합니다. 그리고 이런 Aggregation 배치를 만들 때 대부분 GroupBy, Sum, Count 구문을 사용한 쿼리를 만들어 집계 연산을 DB에 위임하여 처리합니다. 이런 방식이 가지고 있는 문제를 살펴보고 어떻게 문제를 극복했는지 공유하고자 합니다.
배치로 개발하려는 상황 중 하나, 통계 생성
개발자들은 데이터를 집계할 때 주로 배치로 개발합니다. 집계란 N개의 데이터를 1개의 데이터로 요약하는 것이며 보통은 통계 형식의 데이터를 만들 때 사용합니다. 숫자를 누적하고 세는 게 주요 목적입니다.
통계 데이터는 보통 실시간(Real-Time)으로 생성하기에는 부적합한 것으로 인지되고 있습니다. 실시간으로 통계 데이터를 생성한다면 여러 문제가 발생합니다.
- 건 데이터 저장과 통계 데이터 수정을 동시에 처리하도록 구현하면 성능상 병목이 발생함 (통계 데이터의 동시성 처리)
- 건 데이터를 수정하거나 삭제하였을 때 통계 데이터를 수정하기 까다로움
일단위 통계라면 하루치 데이터가 확정된 이후인 다음 날 생성하는 것이 쉽고 일반적입니다. 예를 들자면, 일간 사용자의 연령별 구매 횟수와 금액을 구한다고 하면 매일 1회 배치를 통해 데이터를 누적하는 것이 쉬운 개발 방식입니다.
서버 개발자들은 어떻게 통계 배치를 개발할까?
서버 개발자들이 일반적으로 배치를 개발하는 방법을 먼저 소개하려 합니다. 사용자 나이별 주문 내역 통계 데이터를 생성하는 예시를 통해 일반적인 개발 방식을 살펴보겠습니다.
요구사항
마케팅 목적으로 사용자 나이별 주문 내역 통계 데이터 저장하기
- 사용자별, 상품별 금액을 SUM하여 마케팅 지표로 사용하기 위해 저장함
- 사용자별, 상품별 제품 구입 현황 조사
- 세부 요구사항
- 기준 데이터: 사용자 & 상품 ID
- 추출 데이터: 상품 금액 합산, 주문 횟수
관련 데이터
- Order: 주문 정보
- Price: 금액 정보
- User: 사용자 정보
일반적인 구현 방식
보통 이런 통계 데이터를 생성하는 배치에서는 어쩔 수 없이 GroupBy를 사용한 SUM 쿼리를 사용합니다. 애플리케이션과 MySQL 두 개만 사용하는 경우에는 다른 방법은 없다고 봐도 무방합니다.
ItemReader
- SUM 기준: 제품ID, 사용자 연령을 기준으로 GroupBy
- 조회 대상: 주문가격 SUM, 주문 횟수 SUM, 제품가격, 제품ID, 사용자 연령
- 읽는 순서: 제품등록일시, 사용자 연령 오름차순
- Page Size: 1000개
이때 일반적으로 아래와 같은 쿼리를 작성하여 데이터를 Read합니다.
select
sum(o.amount),
count(1),
p.price,
p.product_id,
u.age
from order o
inner join price p
on o.price_id = p.id
inner join user u
on o.user_id = u.id
where o.order_date = '2021-01-01'
and u.is_active = true
group by p.product_id, u.age
order by p.registered_at asc, u.age asc
limit 1000, 0ItemWriter
ItemReader에서 읽어온 데이터를 저장합니다. (물론 ItemProcessor를 통해 Read한 데이터를 가공할 수도 있지만 이 부분은 개발자의 성향과 개발 상황에 따라 매우 다르므로 제외하겠습니다.)
- 데이터를 데이터베이스에 저장함
- 보통은 JpaItemWriter 또는 Custom ItemWriter에 JPA Repository를 사용해서 Write
orderStatisticsRepository.saveAll(items)일반적인 통계 배치 개발의 문제점
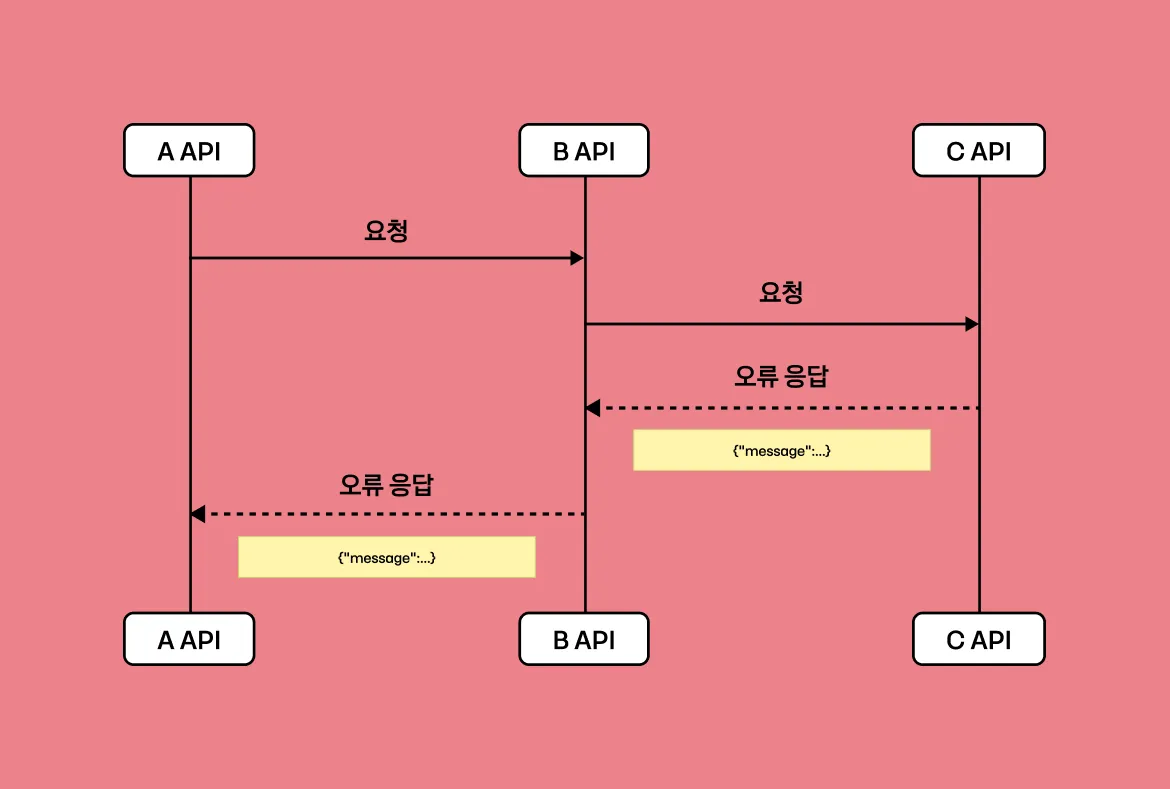
위의 예시를 보면 배치의 ItemReader에서 sum, join, groupby, orderby와 같은 구문들을 사용하고 있습니다. 대다수 서버 개발자들은 데이터를 합산할 때 이런 방식으로 개발하기 때문에 매우 합리적인 개발 방식임에 틀림없습니다. 그러나, 데이터 개수가 수 천만 개 이상으로 매우 많은 상황에서도 문제가 없을까요? 위의 배치는 합산, Count 연산 자체를 쿼리로 구하는 매우 쿼리에 의존적인 모습을 보여주고 있습니다.
통계를 위한 쿼리를 만들다 보면 where, groupby, orderby 구문에서 join한 각기 다른 테이블의 컬럼을 사용하는 경우가 있습니다. 이런 경우에는 실행계획을 예측하기 어렵습니다. 인덱스를 건다고 해도 실행 계획을 보면 대부분 Temporary Table을 생성하거나 Filesort를 사용하게 됩니다. 이는 극심한 조회 성능 저하로 이어집니다.
복잡한 쿼리의 실행계획
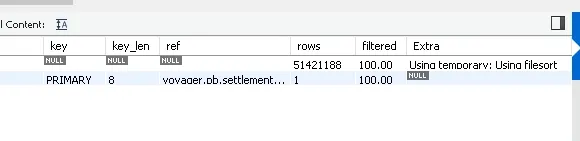
GroupBy+SUM에 의존적인 배치의 문제점
Join GroupBy Sum 쿼리를 사용하면 아래와 같은 문제들이 발생합니다.
- 연산 과정 자체가 쿼리에 의존적이라 결론적으로 데이터베이스 부하를 증가시킵니다.
- 쿼리 튜닝을 하려고 해도 그 난이도가 높아집니다. 데이터가 계속 쌓이다 보면 카디널리티가 바뀌고 복잡한 쿼리의 경우에는 실행계획이 바뀔 수 있습니다.
- 쿼리 튜닝을 위해서 인덱스를 추가하면 Insert, Update 성능이 크게 저하되고 저장용량도 많이 차지하게 됩니다. 서비스를 운영하다 보면 데이터 용량보다 인덱스 용량이 더 큰 경우도 자주 볼 수 있는 현상입니다.
이렇게 난해한 GroupBy+SUM 쿼리를 사용하는 ItemReader는 (감히 예측건대) 전체 배치 성능의 90% 이상을 좌우합니다. 이런 방식에서 오는 문제는 앞서 개선한 ItemReader인 ZeroOffsetItemReader, CursorItemReader를 사용한다고 해도 조회 쿼리 자체 성능에 문제가 있는 것이기 때문에 근본적인 해결책이 아닙니다. 이런 문제들을 해결하기 위해서는 새로운 아키텍처의 SUM 방식이 필요합니다.
새로운 방식의 통계 배치
위에서 언급한 대로 GroupBy+SUM과 같은 복잡한 쿼리를 사용하지 않는 것이 가장 이상적입니다. 새로운 방식의 통계 배치를 만들기 위해서 아예 새로운 아키텍처를 고안해야 했습니다.
복잡한 쿼리에서 단순한 쿼리로
복잡한 쿼리가 문제이니 쿼리를 단순하게 만드는 것이 필요합니다. 즉, 아래 예시처럼 복잡한 쿼리를 단순한 쿼리로 바꾸고자 합니다.
-- 변경 전
select
sum(o.amount),
count(1),
p.price,
p.product_id,
u.age
from order o
inner join price p
on o.price_id = p.id
inner join user u
on o.user_id = u.id
where o.order_date = '2021-01-01'
and u.is_active = true
group by p.product_id, u.age
order by p.registered_at asc, u.age asc
limit 1000, 0-- 변경 후
select
-- sum(o.amount),
-- count(1),
p.price,
p.product_id,
u.age
from order o
inner join price p
on o.price_id = p.id
inner join user u
on o.user_id = u.id
where o.order_date = '2021-01-01'
and u.is_active = true
-- group by p.product_id, u.age
-- order by p.registered_at asc, u.age asc
-- limit 1000, 0위와 같이 쿼리를 단순하게 바꾸어 보았습니다. 그러나 실제 배치에서 사용하기에는 어려운 점이 있습니다.
GroupBy+SUM를 쓴 건 다 그만한 이유가 있었다
생각해 보면 애초에 우리가 GroupBy+SUM 쿼리로 배치를 구현했던 것은 다 그만한 이유가 있었기 때문입니다. 그 이유는 아래와 같습니다.
- 개별 데이터는 필요 없고 Aggregation한 결과를 얻어야 한다.
- 데이터를 가져올 때부터 Aggregation되어 있어야 처리와 저장이 쉽다.
- 개별 데이터를 가져와서 합산하려고 해도 합산을 위한 충분한 공간과 성능이 확보되어야 한다.
- 개별 데이터를 가져왔다고 하더라도 합산을 하기 위해서는 합산 결과를 중간 저장하기 위한 공간이 확보되어야 한다.
- 중간 결과를 저장할 수 있는 공간을 확보했다고 하더라도 MySQL의 GroupBy+SUM쿼리보다 보다 빠르다고 장담할 수 없다.
아래 그림처럼 1,000만 개를 50만 개로 합치면 최소한 중간 저장을 위한 50만 개의 공간은 확보되어야 합니다.
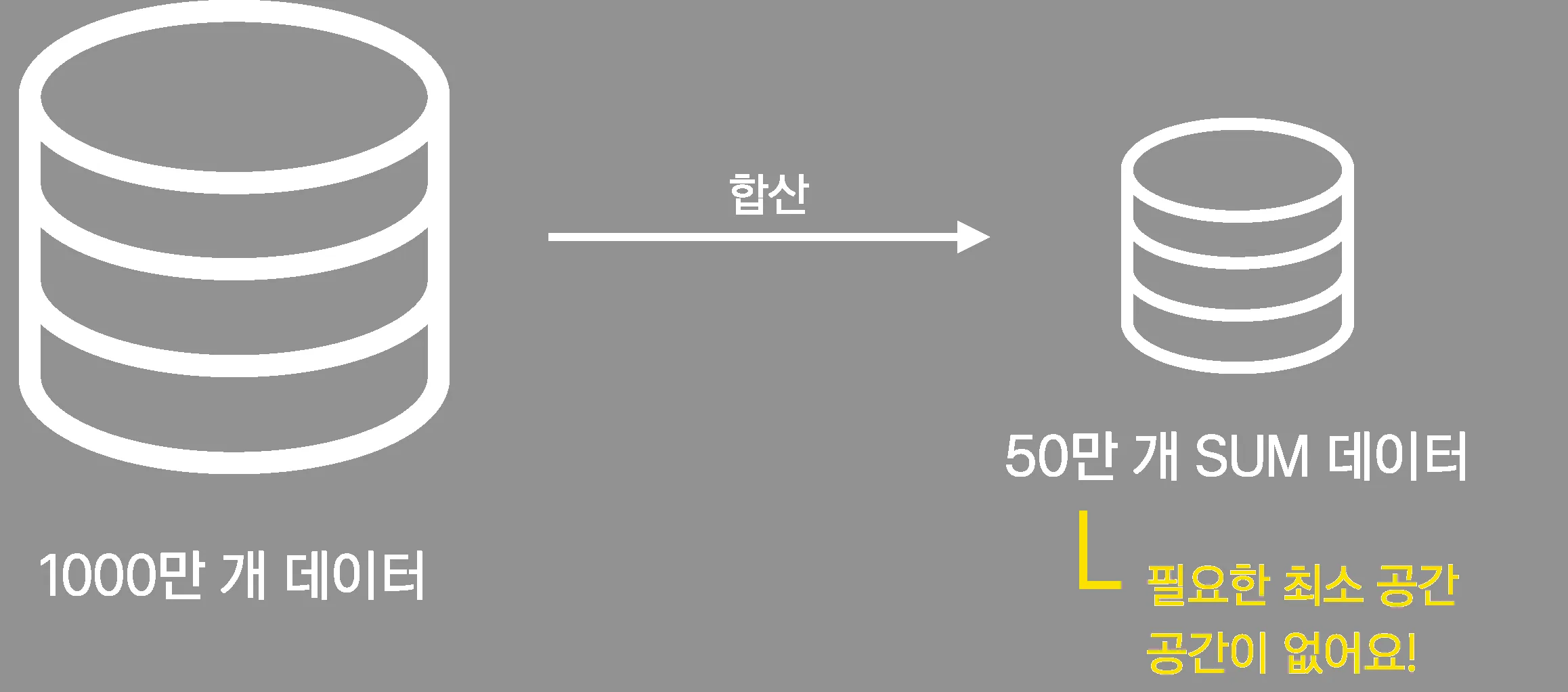
새로운 아키텍처 with Redis
위의 어려움을 해결하기 위해서 직접 Aggregation하기로 하였고 이 과정에서 Redis를 도입하였습니다.
동작 방식
새로운 아키텍처의 원리는 아래 그림으로 정리할 수 있습니다. 요약하자면 Redis를 중간 저장 공간으로 사용합니다.
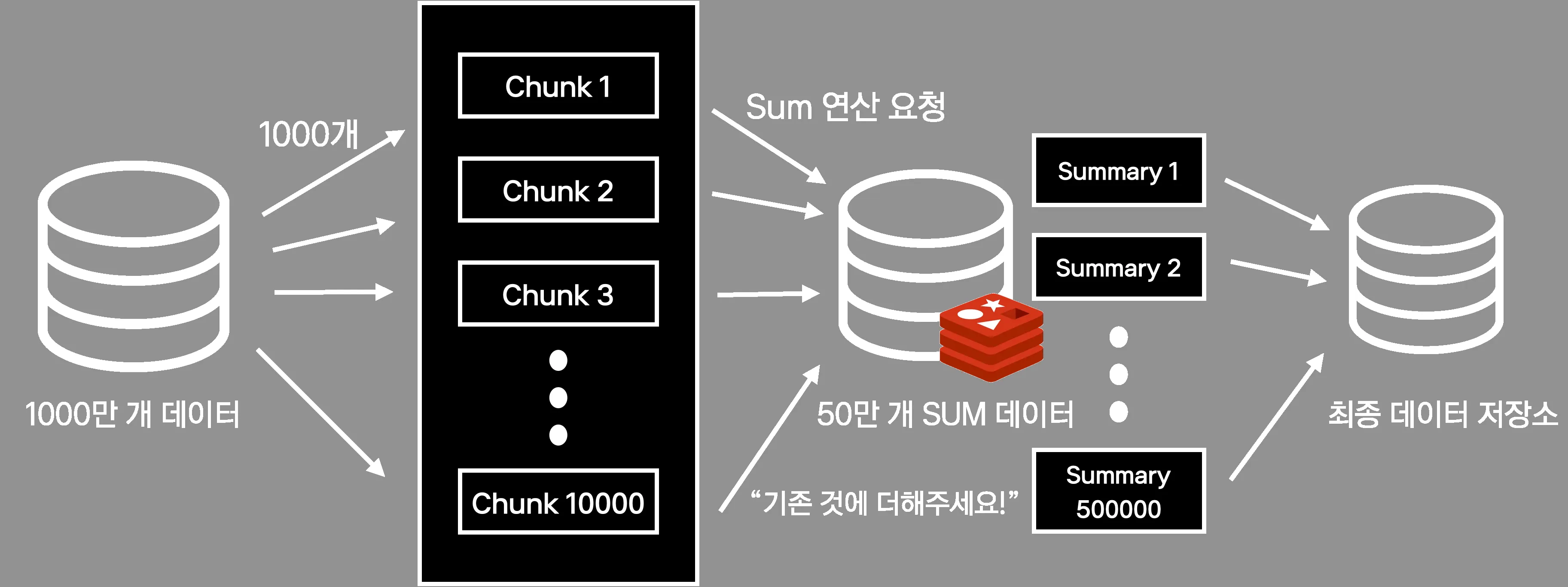
- 1000만 개의 데이터를 1000개씩 나누어 만개의 chunk로 처리
- chunk 단위로 반복해서 Redis에 SUM 연산 요청
- 결국에는 50만 개의 SUM 데이터가 Redis에 들어있음
- 50만 개의 데이터를 최종 데이터 저장소에 저장
왜 Redis인가?
- O(1) 연산 명령어 hincrby, hincrbyfloat 지원
- Redis는 대부분 명령어의 성능이 O(1), O(n)으로 보장되어 있습니다. 공식 문서에도 모든 명령어에 빅오 표기가 되어있습니다.
- 특히, 사용하고자 하는 hincrby, hincrbyfloat는 O(1)로 매우 빠른 누적 연산 명령어입니다.
- 50만 개는 쉽게 저장하는 넉넉한 메모리
- 보통 Redis를 구축할 때 메모리를 최소 수십 기가에서 수백 기가바이트까지도 구축하기 때문에 수 십만 개의 인스턴스 정도는 가뿐하게 저장합니다.
- In-Memory DB로 빠르게 저장하고 영구 저장 필요 없음
- In-Memory DB의 특성상 결과물이 디스크가 아닌 메모리에 저장돼서 연산이 매우 빠릅니다.
- 최종 데이터 저장소에 저장될 때까지만 유지하면 되므로 영구 저장할 필요도 없습니다.
Redis 호출 횟수를 줄여라
Redis 연산 자체는 O(1)로 오래 걸리지 않습니다. 그러나, Redis까지 요청을 보내고 응답을 받는 networking에 드는 시간이 너무 오래 걸립니다. 한 번 요청에 드는 시간을 정말 작게 잡아 1ms라도 하더라도 1000만 번 요청하면 약 3시간이 소요됩니다.

Redis Pipeline
이런 문제를 해결하기 위해 요청을 한 번에 묶어서 처리하는 Redis Pipeline을 사용했습니다. 1개의 chunk에 1번의 연산 요청만 발생하도록 처리하였습니다. 즉, 1000만 개의 데이터라고 할지라도 chunk가 1만 개라면 1만 번의 요청만 발생합니다.
최종 결론
- 많은 개발자들은 통계 데이터를 만들 때 배치로 개발한다.
- 통계 배치를 만들 때 GroupBy+SUM 쿼리를 사용한다.
- 복잡한 GroupBy+SUM 쿼리는 연산이 데이터베이스에 의존적이며 성능 저하, 난해한 쿼리 튜닝의 원인이 된다.
- Redis를 통해 데이터를 직접 Aggregation하는 아키텍처를 만들었다.
- Redis Pipeline의 사용으로 네트워크 I/O를 줄였다.
- 쿼리가 단순해져서 데이터베이스 의존도를 낮추고 성능이 개선되었다.
마치며
이번 게시글에서는 기존 Aggregation방식의 문제를 공유하고 새로운 아키텍처를 소개했습니다. 새로운 아키텍처는 실제 업무에 적용해서 사용하고 있습니다. RDBMS 시스템 사양이 좋거나 충분히 소화할 수 있는 간단한 GroupBy쿼리는 RDBMS에 Aggregation을 위임하는 것이 더 간편하고 빠른 경우도 많았습니다. 그러나 복잡하게 쿼리를 만들어야 하는 경우, index 추가가 어려운 경우, 데이터가 많은 경우에는 새로운 아키텍처를 적용해 배치 성능을 눈에 띄게 개선했습니다.
배치를 만드는 서버 개발자들 중에 제가 했던 고민과 같은 고민을 하고 있는 분이 계신다면 도움이 되기를 바랍니다. 배치 Read 성능에 고민이 있다면 Batch Performance를 고려한 최선의 Reader 게시글도 읽어보시길 바랍니다.


















![[if(kakaoAI)2024] 카카오페이증권의 Kubernetes 지능형 리소스 최적화 (feat. Dr.Pym Project 공유)](/_astro/thumb.CGBHxK2H_ZWFBjN.webp)









![[Project Loom] Virtual Thread에 봄(Spring)은 왔는가](/_astro/thumb.I22_MPmz_1XD63p.webp)



















![[if kakao 2022] Batch Performance를 고려한 최선의 Reader](/_astro/thumb.CZPDDx8q_221xKf.webp)
![[if kakao 2022] 사례로 보는 모바일 자동화 테스트를 통한 모니터링](/_astro/thumb.Dvo2o5eU_95dIV.webp)
![[if kakao 2022] 카카오페이 iOS 웹뷰 소개, 그리고 세션에서 못다한 이야기](/_astro/thumb.DTsQI1Wt_Z1kMSMB.webp)
![[if kakao 2022] ML 모델 학습 파이프라인 설계 (feat. MLOps 플랫폼)](/_astro/thumb.Dc_4_pap_ACvPj.webp)