시작하며
AB 테스트가 필요한 이유는 뭘까요?
기업이 새로운 서비스를 출시할 때 얼마나 많은 과정을 거치는지 생각해 보셨나요? 서비스 분석부터 설계, 개발, 테스트에 이르기까지 정말 많은 시간과 비용을 필요로 합니다. 이렇게 힘들게 출시한 신규 서비스임에도 대중의 호응을 얻을 것이라는 보장은 어디에도 없습니다. 물론 기존에 존재하는 자료를 토대로 추측할 수는 있습니다. 그러나, 실제 유저들의 반응을 정확히 예측하기는 어렵습니다. 만약 대중의 정확한 반응을 사전에 미리 알 수 있다면 서비스는 얼마나 빨리 발전할 수 있을까요? 그러한 데이터가 있다면 얼마나 많은 의사 결정 비용을 줄일 수 있을까요?
새로운 기능 중 일부는 출시하지 않는 것이 더 현명한 선택일 수도 있습니다.
이런 경우 많은 비용을 절약할 수 있게 됩니다.
우리는 AB 테스트를 통해 수많은 사항을 확인할 수 있습니다. 특히, 서비스에 변화가 있을 때 고객이 어떠한 행동을 보이는지, 우리가 기대한 효과가 실제로 일어나는지 말입니다. 이뿐만이 아닙니다. 무엇이 유저의 좋은 경험을 유도하는 Wow Point 인지 반면 어떤 부분이 유저의 불편함을 초래하는 Pain Point 인지 등도 알아낼 수 있습니다.
카카오페이가 성장함에 따라 유저 경험을 중요하게 생각하는 문화 또한 커지고 있습니다. 유저의 실제 데이터를 토대로 비즈니스의 의사결정을 내리고 싶은 내부의 요구도 함께 높아지고 있습니다. 잘 만들어진 AB 테스트 서비스가 있다면 이러한 요구를 충족할 수 있을 거라 기대했습니다. 서비스를 만드는 과정에서 궁금한 점이 있을 때 자유롭게 가설을 세울 수 있고, 유저로부터 받은 정확도 높은 결과를 비교해 서비스에 적용할 수 있다고 생각했습니다.
지금부터 어떤 고민을 통해 카카오페이만의 AB 테스트 서비스를 개발하게 되었는지 차례대로 이야기해보겠습니다.
AB 테스트란?
마케팅과 웹 분석에서, A/B 테스트(버킷 테스트 또는 분할-실행 테스트)는 두 개의 변형 A와 B를 사용하는 종합 대조 실험(controlled experiment)이다.
통계 영역에서 사용되는 것과 같은 통계적 가설 검정 또는 “2-표본 가설 검정”의 한 형태다.
웹 디자인 (특히 사용자 경험 디자인)과 같은 온라인 영역에서, A/B 테스트의 목표는 관심 분야에 대한 결과를 늘리거나 극대화하는 웹 페이지에 대한 변경 사항이 무엇인지를 규명하는 것이다 (예를 들어, 배너 광고의 클릭률(click-through rate).
공식적으로 현재 웹 페이지에 null 가설과 연관이 있다. A/B 테스트는 변수 A에 비해 대상이 변수 B에 대해 보이는 응답을 테스트하고, 두 변수 중 어떤 것이 더 효과적인지를 판단함으로써 단일 변수에 대한 두 가지 버전을 비교하는 방법이다.
- 위키피디아

이미지 출처: The Best A/B Testing Guide for Event Marketers - Purplepass
AB 테스트에 대한 구체적인 설명은 위키피디아의 정의와 아래 링크로 대신하겠습니다.
AB 테스트의 과정을 요약하면 크게 세 단계로 볼 수 있습니다.
- 실험 계획
- 실험 실행
- 데이터 분석 및 위너 버켓 선정
실험 계획은 실험의 목표 및 가설을 생성하는 단계입니다. 실험의 목표가 명확하지 않으면 제대로 가설을 세울 수 없고, 이는 결국 좋은 결과를 기대할 수 없게 되므로 매우 중요한 단계입니다. 그 다음 단계는 실험을 실행하게 되면서 발생합니다.
3가지 액션(할당, 노출1, 전환2)이 필요하며, 구체적인 내용은 아래에서 설명하겠습니다.
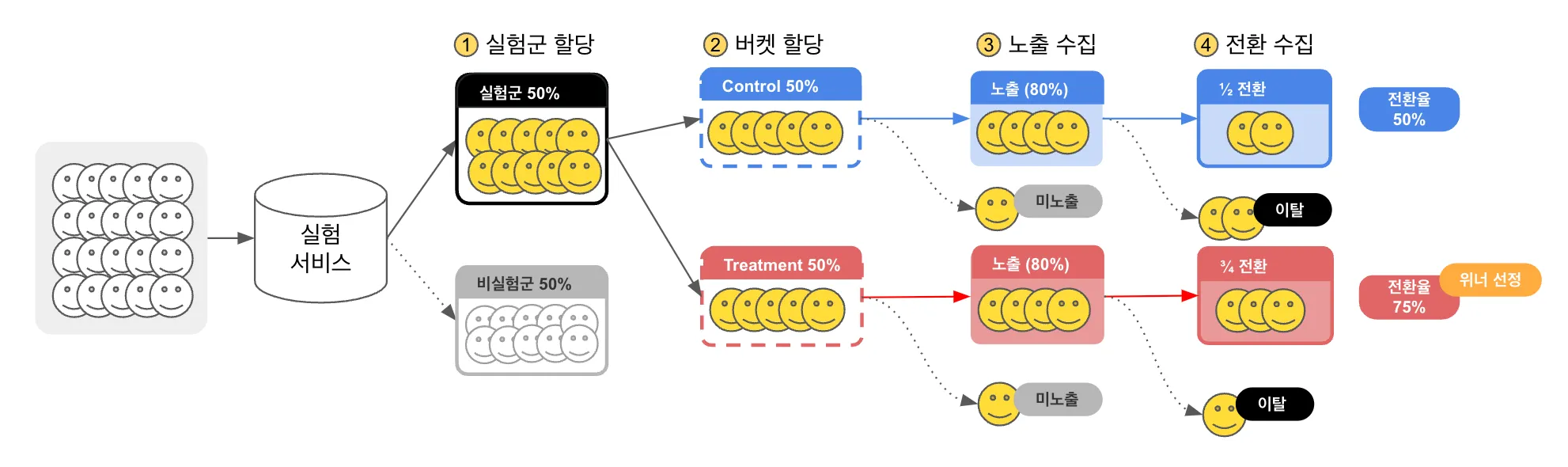
Control - 대조군 또는 비교집단, 어떤 변경도 없는 기존 그대로의 상태를 제공받는 유저 그룹
Treatment - 실험집단, 변경된 상태를 제공받는 유저 그룹 (Experimental Group 이라고도 합니다)
일반적으로 A, B 라고 표기하면 각각 Control, Treatment 라고 이해하시면 됩니다.
- 실험군(대상) 할당
- 실험 대상과 비 대상을 구분합니다. 유저를 다양하게 정의/식별하는 것이 중요합니다.
- 실험 대상은 버켓 할당 단계로 넘어갑니다.
- 비실험 대상은 Fallback 버켓을 할당 받습니다. (Fallback 버켓은 아래에서 설명합니다)
- 버켓 할당
- 준비된 버켓(Control, Treatment)중에 어떤 버켓을 할당하는지 결정합니다.
- 노출 수집
- 유저가 할당 받은 버켓으로 그린 UI를 보았다면 노출 결과를 기록합니다.
- 전환 수집
- 유저가 할당 받은 버켓을 보고 실험에서 요구한 액션을 실행했다면 (예를 들어, 가입, 구매 등) 전환 결과를 기록합니다.
주의: 할당, 노출, 전환은 동일한 실험 상태에서 중복 호출을 하더라도 동일한 결과를 줄 수 있어야 합니다.3
마지막 과정으로 데이터 분석 및 위너 버켓 선정이 있습니다. 이 단계는 유저의 전환 기록을 보고 목표에 따른 성과가 좋은 버켓을 위너로 결정합니다. 위너가 결정되면 모든 유저는 위너 버켓만 할당 받게 됩니다.
요구사항 분석 및 설계
우리의 여정은 Wasabi라는 오픈 소스를 이용한 실험 진행으로 시작되었습니다. Wasabi는 기본적인 실험을 위한 플랫폼을 제공합니다. AB 테스트 실험 초기에는 기본적인 실험만 진행해도 되었기에 Wasabi로 충분했습니다.
그러나, Wasabi만으로는 기본적인 실험을 넘어서 전사적으로 실험을 확산하기에는 어려움이 있었습니다. 대표적인 문제로 회사의 데이터와 연동하여 운영할 수 없었습니다. 외부 오픈소스이기 때문에 기능을 개선하거나 결과 분석이 용이하지 않았고, 내부 사용자가 자유롭게 실험을 설정할 수 없었습니다. 예를 들면, 특정 서비스를 사용하는 사람에게만 새로운 기능을 오픈을 한다든지 혹은 해당 서비스를 사용하지 않는 사람에게만 특별한 넛지4를 하는 등 맞춤화된 실험을 진행하기 어려웠습니다.
우리는 Wasabi의 한계를 뛰어넘기 위해 회사에 맞는 AB 테스트 서비스를 직접 개발하기로 결정했습니다. 처음부터 모든 기능을 구현할 수 없겠지만, 제한된 인력과 인프라를 최대한 활용하여 최소한의 기능을 가진 제품(MVP)을 신속하게 구현하는 것을 목표로 설정했습니다.
A. 요구사항 분석 및 정리
과거에 Wasabi로 실시했던 실험 경험과 우리가 필요하다고 예상되는 기능을 정리하면서 다음과 같은 요구사항을 도출했습니다.
유연하게 유저를 구분하는 방법이 필요합니다.
Wasabi는 트래픽 비율로만 유저를 구분하여 버켓에 할당합니다. 따라서 우리는 유저 트래픽의 일부에서 다음과 같은 유연한 설정을 할 수 있어야 합니다.
- 무작위 선택 (예: 트래픽의 20%)
- 유저 디바이스 정보 (예: iOS 유저, OS 버전)
- 앱 정보 (예: 앱 이름, 앱 버전)
- 유저의 서비스 실적 또는 데모그래픽 (예: 전월 구매 금액 1만원 이상, 30대 이상 남성)
그 외에도 새로운 기능이 추가될 때 확장이 용이하도록 설계해야 합니다. 이 부분은 아래에서 설명할 ANTLR를 통해 구현됩니다.
장애 상황에 대비한 응답이 필요합니다.
장애나 예상치 못한 에러 상황에도 응답 가능한 효과적인 에러 처리 방식이 필요합니다. 장애 상황이라도 응답을 줄 수 있는 정도의 장애(예를 들면, 서버 통신장애)라면 정상적인 실험을 진행할 수 없겠지만, 가능하다면 유입된 유저에게 최대한 응답 해 줘야 합니다. 즉, 서버의 장애 상황에도 유저의 트래픽이 계속 들어올 수 있기 때문에, 그에 대한 준비가 미리 되어 있어야 합니다. 실험 플로우에 맞는 요청 외에는 에러 응답을 주는 Wasabi와는 달리, 최대한 응답을 내려주어 클라이언트에서 안정적인 서비스를 가능하게 해야 합니다.
이 부분은 모든 실험에 Fallback 버켓을 추가하는 방법으로 개선하게 됩니다.
Fallback 버켓은 실험 대상이 아니거나 장애 시 잠시 할당되는 버켓입니다. 실험에 따라 Control 버켓과 동일하게 설정하기도 합니다. 그렇게 되면 장애 발생 시에 모든 유저는 실험을 중단하고 대조군이 보는 화면을 보게 됩니다
실험 데이터를 통계적으로 분석할 수 있어야 합니다.
실험 데이터는 유저의 액션의 결과(할당, 노출, 전환)를 전체적으로 카운트하는 것 말고도 시간에 따른 변화도 파악할 수 있어야 합니다. 그러기 위해서는 배치를 활용하여 주기적으로 데이터를 집계하는 방법이 필요합니다. 또한, 데이터 분석이 가능하도록 모든 실험 데이터를 하둡에 ETL5하는 것도 필요합니다. 그렇게 되면 통계적인 방법으로 자동으로 위너(승자)를 계산6하거나 담당자가 통계치를 보고 직접 위너를 결정할 수 있게 됩니다.
많은 실험을 진행할 수 있어야 합니다.
많은 실험을 진행할 수 있도록 실험에 따른 스케일 아웃이 자유로운 구조를 가져야 합니다. 또한, 스케일 아웃7에 따른 속도또한 보장이 될 수 있도록 리액티브8 형식의 서비스나 내부에서 응답을 캐시할 수 있는 구조로 구축을 해야합니다.
실험 수정이 가능해야 합니다.
통상적으로 실험의 수정이라는 것은 처음에 수행했던 실험의 가설이나 설계가 틀렸다는 것을 의미합니다. 대개 그런 경우 실험을 수정하지 않고 새로운 실험을 만들게 됩니다.
하지만, 이미 진행되고 있는 실험인 경우는 어떻게 해야 할까요? 배포가 쉽지 않은 모바일 환경이라면 어떻게 해야 할까요? 그런 경우에도 실험을 수정할 수 있어야 합니다. 실험의 수정 전 데이터와 실험 수정 후의 데이터가 명확하게 분리가 된다면 실험 수정 기능을 지원해도 된다고 판단했습니다. (그렇다고 해도 실험 수정 기능은 매우 제한이 되어야겠죠)
이 요구사항은 아래에서 설명하는 스냅샷 기능으로 해결합니다.
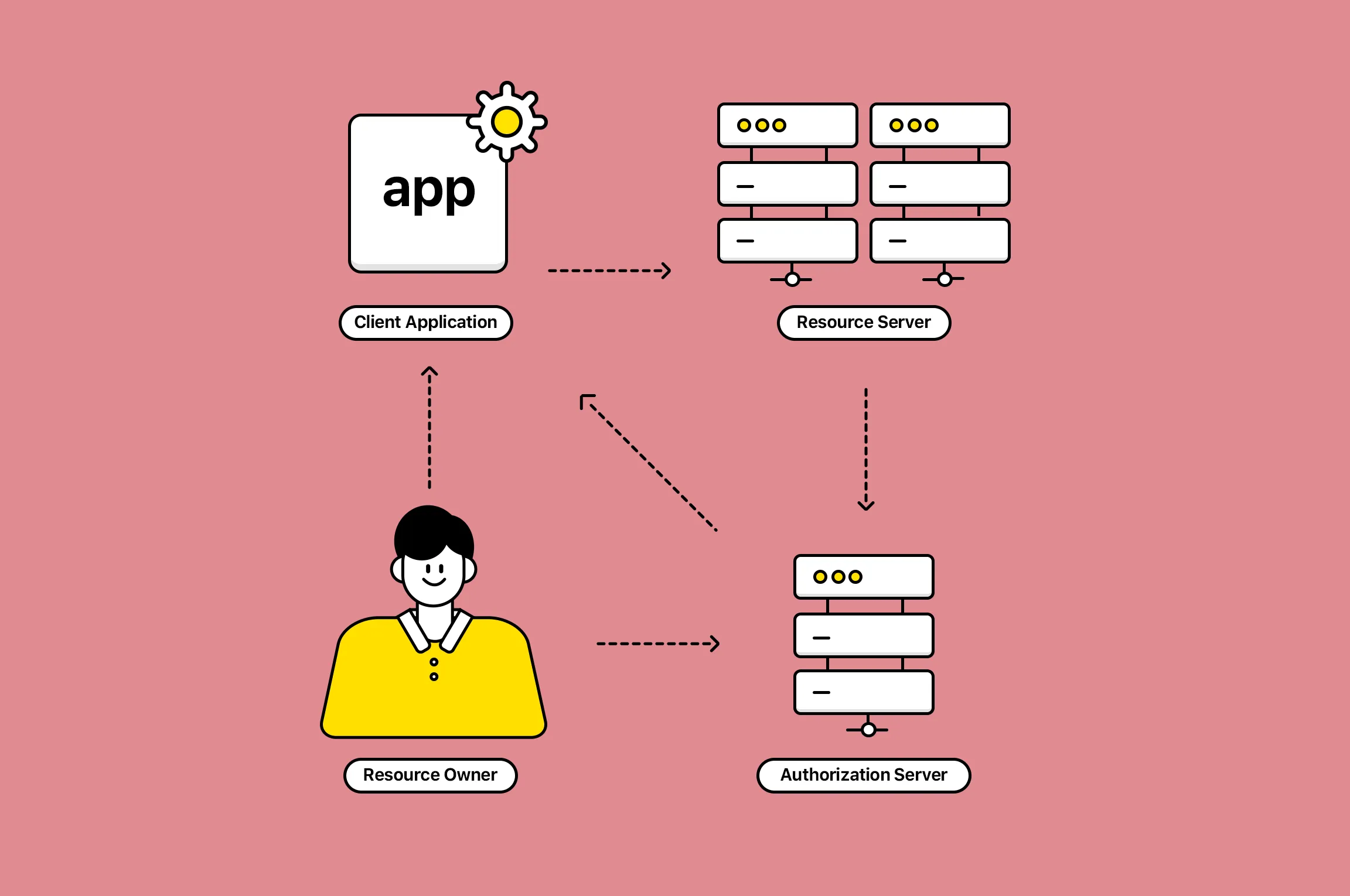
B. 서비스 구조 설계
요구사항을 바탕으로 예상되는 서비스를 다음 다섯 가지 부분으로 설계하였습니다.
- 실험 설정 어드민
- 계획된 실험을 설정하고, 실험의 승자를 결정합니다.
- 실험 서비스
- 계획된 실험을 실행합니다(할당, 노출, 전환 등).
- 실험 데이터 수집 배치
- 주기적으로 유저의 행동 데이터(할당, 노출, 전환)를 집계합니다.
- 실험 데이터 ETL
- 분석을 위해 모든 실험 데이터의 스냅샷을 하둡에 ETL합니다.
- 데이터베이스
- 실험 설정과 통계 요약정보는 MySQL을 사용하고, 유저의 실험 정보는 MongoDB를 사용합니다.
간략하게 그려보면 아래와 같습니다.
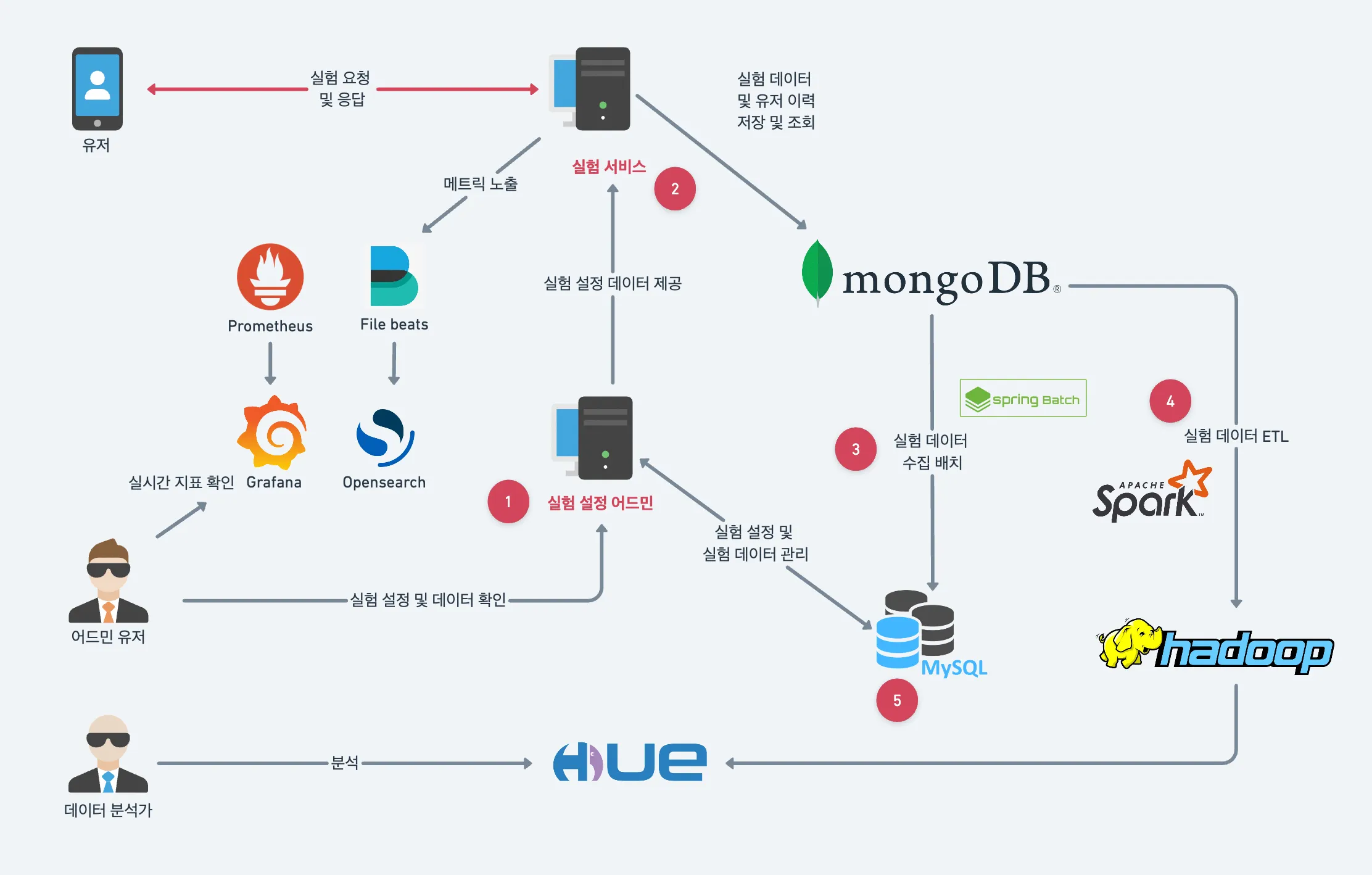
추가로 위 그림에 나오는 3명의 역할을 설명하면 다음과 같습니다.
유저
- 화면에 진입하여 연결된 실험의 새로운 버켓을 할당 받습니다.
- 화면을 보게 되면 노출을 진행하고, 실험에서 유도한 행동을 하면 전환을 진행합니다.
- 유저는 실험 진행 여부를 알 수 없습니다.
서비스 담당자(어드민 유저)
- 실험을 계획하고 어드민을 이용해서 실험을 설정합니다.
- 실험을 상태를 관리합니다.(실험의 시작과 종료 등)
- 실시간 지표를 확인하며 실험의 위너를 결정합니다.
데이터 분석가
- 전체 실험 데이터를 통해 진행된 실험의 가설을 검증하고 계획된 목표를 달성했는지 분석합니다.
기술의 선택
지금까지 카카오페이만의 AB 테스트를 만들기 위해 요구사항을 정리해 보았고, 어떻게 서비스를 구성할 것인지도 그려보았습니다. 그렇다면 우리가 요구사항을 해결하기 위해 어떤 기술적인 고민을 했는지 설명해보겠습니다.
지금은 기술을 선택한 이유를 쉽게 설명할 수 있지만 그 과정은 어려웠습니다. 선택한 기술이 닭 잡는 칼로 소를 잡는 것은 아닌지, 정말 옳은 선택인지 많은 시간 논의했습니다. 예상하지 못한 운도 따랐습니다. 평소에 팀에서 스터디 했던 기술이 우리가 해결해야 할 요구사항을 만족하는 경우도 있었고, 개발자끼리 이야기하면서 귓동냥으로 들었던 것이 도움이 되기도 했습니다. 그 중에 꼭 소개하고 싶은 내용만 간추려 보겠습니다.
ANTLR
유저를 구별하는 기능은 이 프로젝트에 있어 절대적으로 중요한 요소입니다. (요구사항의 가장 첫 번째에 위치한 내용입니다) 다양한 목적에 따라 유저를 구별하려면 유저를 정의하는 기능이 매우 유연해야 합니다. 우리는 논의 끝에 데이터베이스 SQL처럼 표현력이 우수한 방법이 필요하다고 생각했습니다.
예를 들어,
아이폰 유저이고 서비스-A 경험이 없는 유저는 아래와 같고,
OS = IOS AND SERVICE_A(FALSE)
서비스-A 경험이 없거나 서비스-B의 경험이 없는 유저는 아래처럼 표현이 될 수 있어야 합니다.
SEREVICE_A(FALSE) OR SERVICE_B(FALSE)
물론 전통적인 방법인 데이터베이스 테이블로도 해결할 수 있습니다. 하지만, 테이블로 위와 같은 관계를 만드는 것은 경험상 구현이 복잡하고 관리가 어렵기 때문에 최대한 피하고 싶었습니다. 우리는 이를 해결할 수 있는 방법을 고민하였고, 그 과정에서 ANTLR라는 도구를 선택하게 되었습니다.
![]()
ANTLR는 문법을 생성하고 관리할 수 있게 도와주는 오픈소스 라이브러리 입니다.
이미 많은 오픈소스에서 다양하게 사용되고 있습니다. 9ANTLR는 정의한 문법에 따라 필요한 코드를 자동으로 생성해주는 강력한 기능이 있습니다.
이로 인해 개발자는 복잡한 문법 처리를 하지 않고도, 원하는 기능 구현에 초점을 맞출 수 있게 됩니다.
ANTLR의 도움을 받아 문법을 정의하게 되면, 다음과 같은 표현이 가능해집니다.
OS=IOS AND OS_VER > 12.0.0
문법(g4)으로 정리하면 아래와 같습니다. 10
expression:
OS op=(EQ|NEQ) value='IOS'|'ANDROID'
| OS_VER op=(EQ|NEQ|GT|GTE|LT|LTE) value=NUMBER_WITH_DOT
| expression AND expression # AND 사용으로 재귀적인 문법을 가능하게 합니다.
| expression OR expression. # OR 사용으로 재귀적인 문법을 가능하게 합니다.
| left='(' expression right=')' # 괄호 사용으로 문법의 우선순위를 결정할 수 있습니다.
;
EQ: '=';
NEQ: '!=';
GT: '>';
GTE: '>=';
LT: '<';
LTE: '<=';
NUMBER: [0-9]+;
NUMBER_WITH_DOT: NUMBER'.'NUMBER'.'?NUMBER?;
WS: [ \t\r\n]+ -> skip;위의 예시를 그대로 가져와 해석하면 아래처럼 파싱 트리가 생성되게 됩니다. (IntelliJ에서 ANTLR 플러그인 으로 테스트 했습니다)
OS=IOS AND OS_VER > 12.0.0
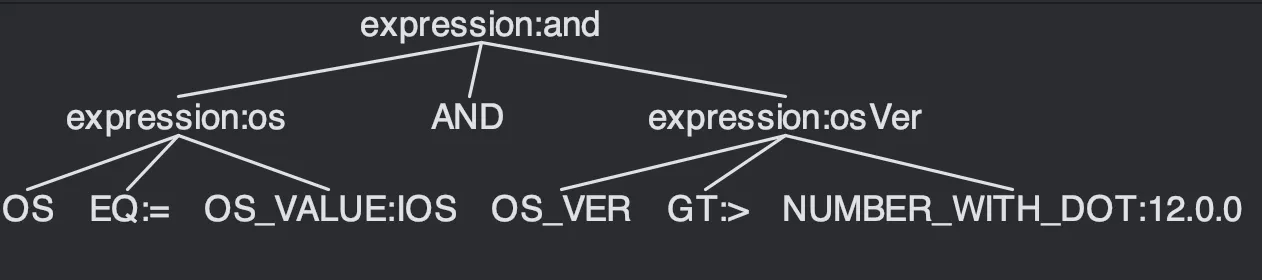
새로운 문법이 필요하게 된다면, 기존에 정의된 문법에 새로운 문법을 덧붙이는 방식으로 유연하게 확장할 수 있습니다. 우리는 ANTLR를 이용하여, 다음 두 서비스에서 활용합니다.
- 실험 어드민: 실험 설정의 유효성을 검증합니다. 그래서 실험 시작 전에 잘못된 설정을 가려냅니다.
- 예를 들어, 유저가 아이폰 유저이면서 안드로이드 유저일 수는 없습니다
- 실험 서비스: 실험을 설정대로 진행합니다.
그런데 ANTLR를 사용하는데 성능상 문제가 한 가지 있습니다. 서비스의 트래픽에 직접 적용하기에는 파싱과 실행의 2가지 측면에서 ANTLR의 실행 속도를 담보할 수 없었습니다.
문법이 길어지면 매 요청마다 파싱하는데 걸리는 시간이 길어집니다. IO 기능(외부 서비스 호출)이 있는 경우 실행하는데 오랜 시간이 걸릴 수 있습니다.
문법 파싱 속도의 문제는 아래 그림처럼 문법 파싱 로직을 비동기로 빌드하는 방식으로 해결했습니다.
비동기 방식으로 빌드하는 것은 어드민의 변경 내역을 서비스에서 Pull 방식으로 가져가기 때문에 변경 사항을 바로 적용하지 못하는 단점이 존재합니다.
어드민의 설정을 바로 적용하는 것보다 안전하게 실험을 진행하는 게 우선이기 때문에 이 방법을 선택했습니다.
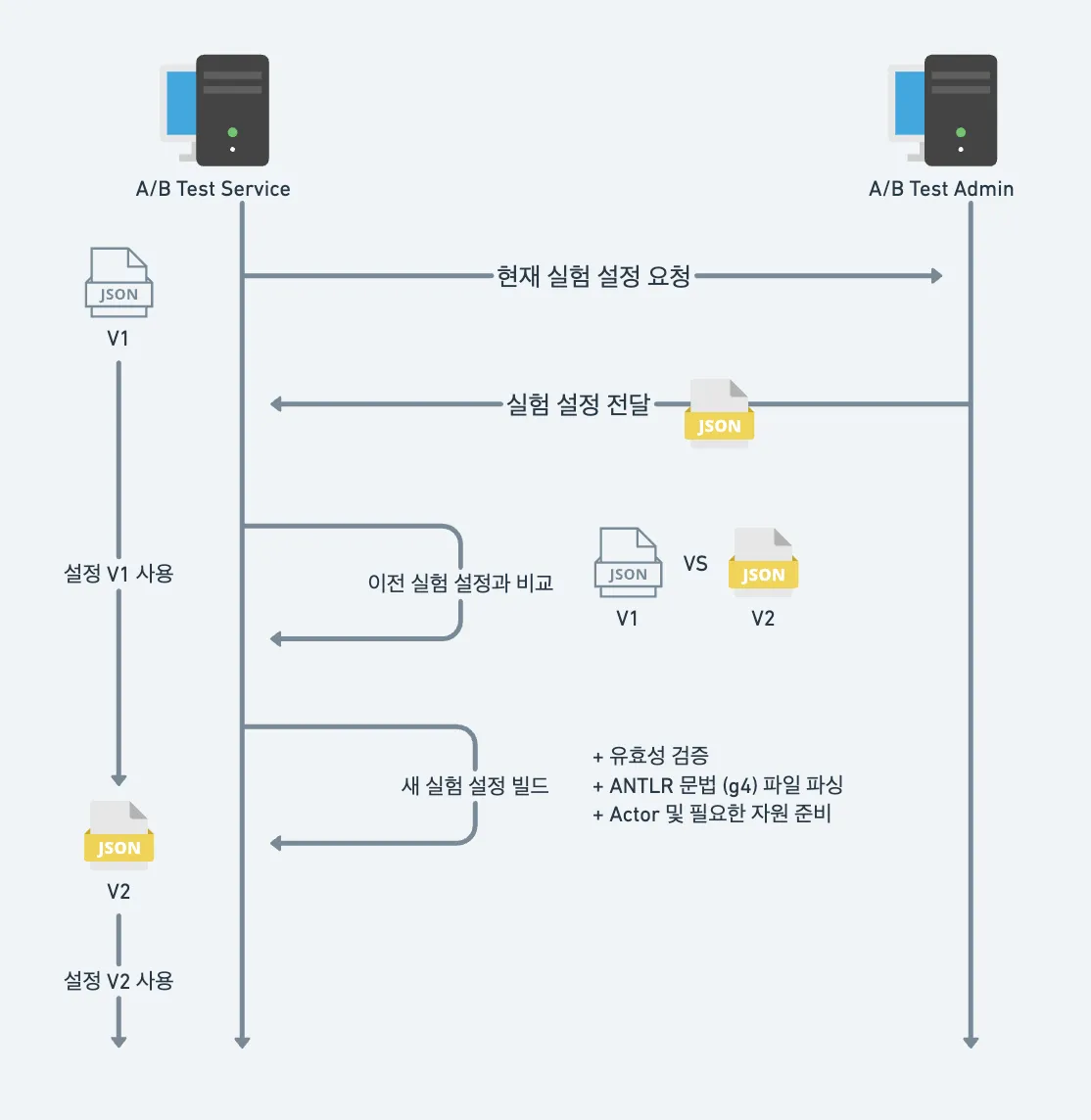
실험에 변경사항이 있으면 실험 설정이 V1 버전과 수정된 V2 버전이 공존하게 됩니다. 실시간으로 문법을 파싱하거나 변경사항을 적용하지 않는 대신, 우리는 주기적으로 백드라운드에서 설정을 비교하는 방식을 채택해 ANTLR 문법을 파싱하는 시간과 초기화 작업 시간을 벌 수 있었습니다. 현재는 5분마다 주기적으로 실험 설정 변경 여부를 확인합니다.
이제 코드 실행 속도를 어떻게 해결했는지 설명하겠습니다. 이해를 돕기 위해 관련된 코드를 아래에 첨부하였습니다.
when (calculationType) {
ExpressionType.IMMUTABLE,
ExpressionType.MUTABLE_FAST -> testDirect(request)
ExpressionType.MUTABLE_SLOW -> {
// 매우 느린 마지막 연산끼리만 병렬로 진행한다.
if (this@combine.depth == 1 && b.depth == 1) { // 트리의 최상위, 마지막 연산
parZip(
Dispatchers.IO, // 아래 두 개의 연산을 병렬 처리
{ this@combine.test(request) },
{ b.test(request) }
) { left, right ->
left.zip(right) { leftValue, rightValue ->
when (conjunction) {
Conjunction.AND -> leftValue && rightValue
Conjunction.OR -> leftValue || rightValue
else -> throw IllegalStateException("알 수 없는 타입($conjunction) 입니다")
} // when
} // zip
} // parZip
} else {
testDirect(request)
}
}
}위 코드를 보면 연산을 3가지로 구분하고 있습니다.
- IMMUTABLE - 빠르고 항상 동일한 응답을 받을 수 있음
- MUTABLE_FAST - 빠르지만 항상 동일한 응답을 받을 수 없음
- MUTABLE_SLOW - 가장 느리고 IO 작업이 포함되어 있음
파싱 트리를 가장 하위부터 상위로 올라가면서 연산을 조합하게 되는데, 파싱 트리를 순회하면서 한 번이라도 MUTABLE_SLOW 가 포함이 되어 있으면 병렬처리를 하게 됩니다.
이러한 룰은 내부에서 정한 Semigroup11을 통해 진행됩니다.12
fun Semigroup.Companion.expressionType(): Semigroup<ExpressionType>
= Semigroup { b ->
when (Pair(this@Semigroup, b)) {
Pair(ExpressionType.IMMUTABLE, ExpressionType.IMMUTABLE) -> ExpressionType.IMMUTABLE
Pair(ExpressionType.IMMUTABLE, ExpressionType.MUTABLE_FAST) -> ExpressionType.MUTABLE_FAST
Pair(ExpressionType.IMMUTABLE, ExpressionType.MUTABLE_SLOW) -> ExpressionType.MUTABLE_SLOW // SLOW
Pair(ExpressionType.MUTABLE_FAST, ExpressionType.IMMUTABLE) -> ExpressionType.MUTABLE_FAST
Pair(ExpressionType.MUTABLE_FAST, ExpressionType.MUTABLE_FAST) -> ExpressionType.MUTABLE_FAST
Pair(ExpressionType.MUTABLE_FAST, ExpressionType.MUTABLE_SLOW) -> ExpressionType.MUTABLE_SLOW // SLOW
Pair(ExpressionType.MUTABLE_SLOW, ExpressionType.IMMUTABLE) -> ExpressionType.MUTABLE_SLOW // SLOW
Pair(ExpressionType.MUTABLE_SLOW, ExpressionType.MUTABLE_FAST) -> ExpressionType.MUTABLE_SLOW // SLOW
Pair(ExpressionType.MUTABLE_SLOW, ExpressionType.MUTABLE_SLOW) -> ExpressionType.MUTABLE_SLOW // SLOW
else -> throw IllegalStateException("실행 타입을 합칠 수 없습니다 : ${this@Semigroup} + $b")
}
}코드에서는 실행 속도를 단순 연산으로 해결될 수 있는 작업과 외부 호출 작업(I/O) 작업을 분리하는 것으로 해결하고 있습니다. 이로써 IO 작업이 추가되는데 있어서 ANTLR 실행에 부담이 다소 줄게 되었습니다.
Coroutines (+ Actor)
![]()
실험 프로젝트에서는 주 언어로 코틀린을 사용하고 있어, 이를 기반으로 코루틴을 도입해 서버를 구축하게 되었습니다. 코루틴은 Reactor에 비해 기능이 많이 부족합니다만, 비동기 코드를 동기 코드처럼 간결하게 작성할 수 있다는 것이 가장 큰 장점입니다. 13
또한, 코루틴은 다양한 편의성 기능 (쉬운 컨텍스트 전환과 조합)으로 개발자가 비즈니스 코드에 집중할 수 있게 해 줍니다. 코루틴에서 지원하는 Actor 기능은 멀티쓰레드 환경에서의 로직 구현을 단순하게 해주는 훌륭한 도구입니다. 이는 실험 기능을 구현하는 과정에서 매우 효과적으로 사용되고 있습니다.
주로 사용하고 있는 커스텀 액터 두 가지만 소개하겠습니다.
중복 요청을 제어하는 액터
이 액터는 액터의 기본적인 기능을 활용한 것으로, 반복적인 연산을 한 번만 수행하도록 도와줍니다. 아래의 코드는 실험 대상인 유저에게 버킷을 할당하는 코드입니다. 할당 로직은 상황에 따라 어드민에서 실험 설정 정보를 가져오기도 하고, 내부 캐시도 확인하고, 디비도 조회하는 등 하는 일이 많습니다.
suspend fun executeAssign(
context: AbTestContext,
request: UserSingleRequest,
coroutineContext: CoroutineContext
): Either<Throwable, AssignResult>
= sequentialRunner.delegate( // 아래 로직을 액터에게 위임합니다.
{ // suspend 함수 주입
repository
.find(request.actionHistoryKey()) // 할당 이력 조회
.flatMap {
if (it.isEmpty()) { // 할당된 이력이 없다면, 할당 진행
context
.assign() // 할당 시도
.map { bucket -> // 할당 결과 저장
handleNewBucket(request, context, bucket)
}
} else { // 이미 할당된 이력 존재
AssignResult.ofAlreadyAction(context, it).right()
}
}
}, coroutineContext)이 액터를 이용해서 (동일한 실험, 동일한 유저의) 할당 연산을 서버 인스턴스 당 한 번만 수행하도록 제한할 수 있기 때문에, 중복 실행 문제14의 위험을 많이 낮춰줍니다.
inline fun <reified T, M> sequentialRunner(
crossinline buildMessage: (
suspend () -> T, CoroutineContext, CompletableDeferred<T>
) -> M
): SequentialRunnable<T>
where T : Any,
M : DeferredMessage<T>,
M : SequentialRunnerMessage<T>
= object : SequentialRunnable<T> {
// 액터를 생성합니다.
private val actor = sequentialRunnerActor<T, M>(
coroutineContext +
CoroutineExceptionHandler { _, exception ->
// error logging
}).buildActionSenderDeferred()
override suspend fun delegate(
f: suspend () -> T, // 액터에게 위임할 함수
context: CoroutineContext // 함수가 실행할 컨텍스트
): T = actor.sendAndGet { buildMessage(f, context, it) }
}마지막 메서드에서, suspend 함수와 실행할 코루틴 컨텍스트를 액터에게 전달해 준 뒤 실행 결과를 기대합니다.
우리는 각 실험마다 액터를 다양하게 준비하고 있으며, 위와 같은 방법으로 동일한 연산을 한 번만 실행하도록 합니다.
런타임 할당을 지원하는 액터
할당은 실험 서비스에서 가장 중요한 기능이며, 그 중에서도 유저를 랜덤하게 할당하는 것이 필요했습니다. (예: 트래픽 유저의 30% 할당) 할당 방식에는 크게 두 가지(해시함수 할당과 런타임 할당)가 있는데, 그 중에서 우리는 런타임 할당을 채택했습니다.
타사의 AB 테스트 서비스에서는 MurmurHash와 같은 해시 함수를 사용하거나, 직접 해시 함수를구현하여 유저를 랜덤하게 할당합니다.
해시함수 할당 - 해시 함수를 이용하기 때문에 유저가 언제 들어와도 고정된 할당 결과를 받습니다. 런타임 할당 - 유저가 들어오는 순서대로 할당을 해주므로 할당 결과가 고정되지 않습니다.
런타임 할당 방식을 선택한 이유는 우리가 유저를 선택할 때 비율로 랜덤하게 선택하는 방법 말고도 다양한 방식을 지원해야 하기 때문입니다.만약 우리가 유저를 할당할 때 랜덤한 기능만 필요했다면 해시 함수로 구현했을 것입니다. 또한, 이 방법은 해시 함수를 사용하는 것과는 달리 적은 유저의 유입으로도 비교적 정확하게 할당 가능하다는 장점도 있습니다.
서버가 1대라고 가정하면, 100명의 유저만 들어와도 정확한 할당이 가능합니다.
내부에서는 여러 값 중에 한 개의 값만 선택하는 기능을 가지고 있어서 Select One 액터라고 불립니다. 이 액터를 어떻게 구현했는지 아래 예시에서 보여드리겠습니다.
// 리스트가 셔플 되어서 들어옵니다.
fun <T : Any> CoroutineScope.selectOne(candidates: List<T>)
: SendChannel<DeferredMessage<T>> {
check(candidates.isNotEmpty()) { "선택할 후보 리스트가 없습니다" }
return actor(capacity = Channel.BUFFERED) {
val size = candidates.size
var index = 0
fun one(): T {
if (index >= size) { // 모두 선택했다면 다시 처음으로
index = 0
}
return candidates[index++] // 위험하지 않습니다 :-)
}
for (message in channel) {
message.response.complete(one()) // 요청이 오면 안전하게 할당
}
}
}액터에서는 1개의 코루틴이 실행되는 것을 보장하기 때문에 위와 같은 ++ 기능도 문제 없이 잘 동작합니다. 이 액터를 이용해서 100개의 값 중에 1개를 취하는 방식으로 트래픽에서 랜덤하게 유저를 선택하도록 구현하였습니다.
Off Heap Cache
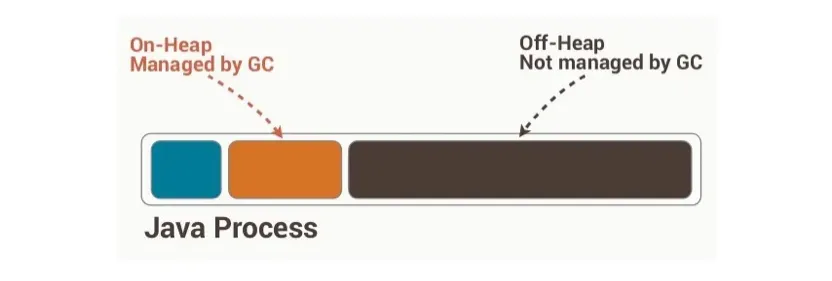
4번째 요구 사항인 많은 실험을 진행하고, 이에 따른 유저의 실험 정보를 효율적으로 관리하기 위해 캐시 기능을 도입했습니다. 유저의 실험 정보는 유저 수와 실험 수에 비례해 증가합니다. 실험을 많이 할수록 이를 전부 힙 메모리에 저장하기에는 그 양이 너무 많았습니다. 또한, 가비지 컬렉션(Garbage Collection, 이하 GC)으로 인한 성능 저하 위험 때문에, 우리는 힙 외부에 정보를 저장해야 했습니다. 이에 따라, 우리는 오프힙 캐시를 도입하기로 결정했습니다. 오프힙 캐시는 직렬화와 역직렬화 과정에서 추가적인 CPU 연산이 필요하고, 관리가 어렵긴 하지만, 가비지 컬렉션으로 인한 문제를 피하는 데 가장 현실적인 해결책입니다.
로컬 캐시 대신 글로벌 캐시를 활용하면 이상적이겠지만, 그에 따른 추가적인 인프라를 도입하는 것을 원치 않았습니다. 우리의 목표는 가능한 한 로컬 환경을 활용하여 문제를 해결하는 것이었습니다. 만약 실험의 수가 급증하고 캐시의 히트율이 뚜렷하게 하락한다면, 그 때 글로벌 캐시를 고려하기로 했습니다.
캐시 라이브러리를 찾다가 카산드라에서 사용하는 오프힙 캐시인 OHC를 알게 되었습니다.
바로 OHC를 실험 서비스에 적용하였고, 오프힙 캐시로 유저의 실험 정보를 GC 위험 없이 관리할 수 있게 되었습니다.
안타깝게도, 유저 요청이 여러 서버에 분산되어 들어오게 되므로 로컬 캐시가 일반적인 글로벌 캐시처럼 높은 히트율을 가지긴 어렵습니다.
실제로 이 오프힙 캐시도 약 8% 정도의 적은 히트율을 기록하고 있습니다만, 매우 적은 리소스(70MB 이하)를 사용하면서 이 정도의 캐시 기능을 유지하고 있기 때문에 유의미한 결과를 내고 있다고 생각합니다.
스냅샷 기능의 도입
실험의 변경을 지원하기 위해 데이터 모델링에 스냅샷 기능을 추가했습니다. (다섯 번째 요구사항)
스냅샷은 아래 두 가지 기능으로 구현됩니다.
- 실험 설정 스냅샷
- 유저 데이터 스냅샷
실험 설정 스냅샷은 실험 정보를 수정하면 발생합니다.
아래 그림은 어떤 실험을 2번 수정하여, 997번과 999번 스냅샷이 생긴 것을 보여줍니다.

유저 데이터 스냅샷은 실험 변경으로 인한 데이터의 오염을 막고자 각 실험 설정 스냅샷 단위로 쌓게 됩니다. 위의 그림에서 두 스냅샷이 모두 실험을 진행했다고 가정했을 때, 2개의 유저 데이터가 분리되어 저장됩니다. 유저 데이터가 스냅샷 단위로 분리되기 때문에 실험이 변경이 되어도 데이터 오염없이 유저 데이터를 분석할 수 있습니다.
아래는 유저 데이터 스냅샷이 합산된 어떤 실험의 전체 데이터 입니다.
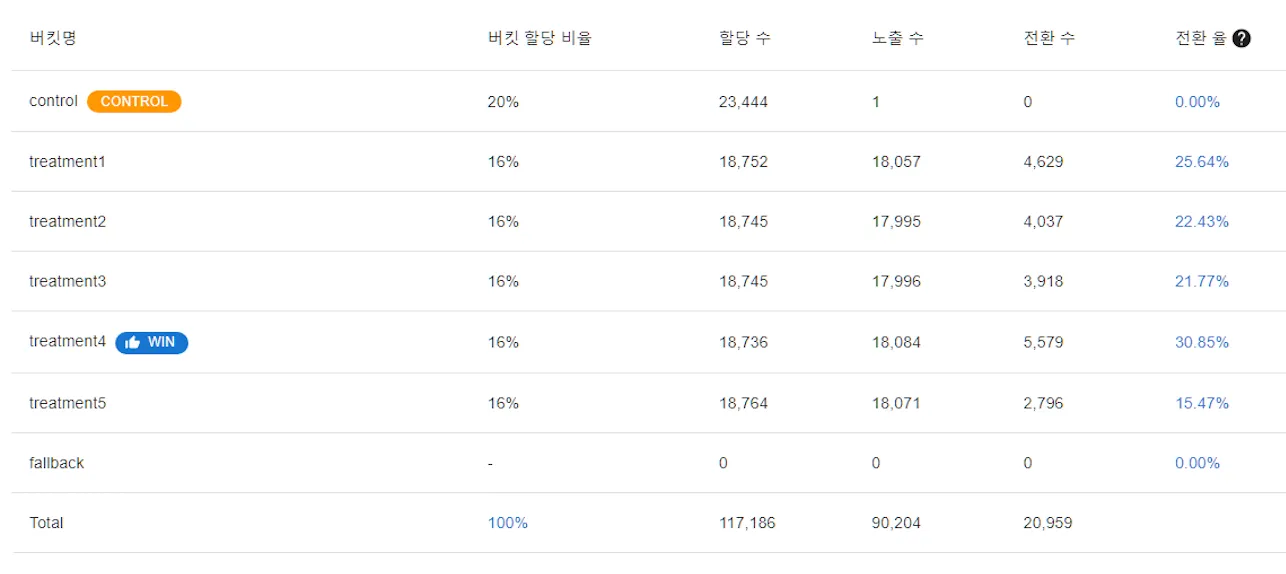
treatment4의 전환율이 가장 좋아서 위너로 선택된 것을 알 수 있습니다.
(내부에서는 위너를 선정할 때, P Value를 계산해서 함께 고려하고 있습니다)
마치며
지금까지 우리만의 AB 테스트 서비스를 만든 이유에 대해 안내해 드렸습니다.
단순하게 유저를 랜덤하게 할당만 되던 Wasabi에서 확장 가능한 커스텀 문법으로 다양하게 유저를 할당할 수 있게 했고,
앱을 배포한 후에도 실험을 수정할 수 있는 기능과, 더 많은 실험을 안정적으로 운영할 수 있도록 노력했습니다.
적은 지면이라 다 보여드리지 못했지만, 카카오페이에서 AB 테스트 서비스를 만들면서 어떤 고민을 하고 있는지 조금이나마 보여드렸다고 생각합니다.
여기서 여정이 끝난 것은 아닙니다. 항상 실험 문화를 정착하고 증대하는 방법을 고민하고 있고, 가까운 시기에는 다양한 편의 기능을 제공할 예정도 있습니다. (실험 기간 계산기15, Feature Flag16, 대시보드 등) 앞으로도 전사적으로 데이터 기반한 의사 결정을 하는데 있어서 부족함이 없도록 계속 발전해 나갈 것입니다. 긴 글 읽어주셔서 감사합니다.
Footnotes
-
노출(impression) - 유저의 이벤트 중에 하나이며, 유저가 할당된 결과를 보았다는 것을 의미합니다. 이 기능은 클라이언트의 구현에 의존합니다. ↩
-
전환(conversion) - 실험에서 의도한 행동. 예를 들어 실험을 통해 서비스 가입을 유도했을 때, 서비스 가입이 전환이 된다. ↩
-
몇 번을 호출하든지 결과가 동일해야 합니다. HTTP 메서드의 멱등(Idempotent)란? ↩
-
Nudge - 사람들을 바람직한 방향으로 부드럽게 유도하되, 선택의 자유는 여전히 개인에게 열려있는 상태를 말한다. ↩
-
ETL - Extract, Transform, Load의 약자. 위키피디아 참고 ↩
-
MAB(Multi-armed Bandit), A/B 테스트의 확장판, MAB (Multi-Armed Bandits) 알고리즘 ↩
-
리액티브 프로그래밍은 데이터 흐름(data flows)과 변화 전파에 중점을 둔 프로그래밍 패러다임(programming paradigm)이다. 이것은 프로그래밍 언어로 정적 또는 동적인 데이터 흐름을 쉽게 표현할 수 있어야하며, 데이터 흐름을 통해 하부 실행 모델이 자동으로 변화를 전파할 수 있는 것을 의미한다. from Wikipedia(en), from 블로그 ↩
-
Semigroup (반군) - 추상대수학에서 반군(半群, 영어: semigroup)은 결합법칙을 따르는 하나의 이항 연산이 부여된 대수 구조이다. (위키피디아: https://ko.wikipedia.org/wiki/반군). 쉽게 설명하면 2개의 동일한 타입이 어떤 연산을 통해 1개의 동일한 타입으로 결합될 수 있는 성질을 의미합니다. 여기선 연산을 3가지로 정의하고, 3가지의 모든 경우 수의 조합을 세미그룹의 규칙으로 정의합니다. ↩
-
arrow-kt - 함수형 프로그램을 코틀린에서 할 수 있도록 지원해주는 라이브러리. (https://arrow-kt.io) ↩
-
코루틴 공식 가이드 읽고 분석하기가 많은 도움이 되었습니다. ↩
-
서버로 복수의 요청이 동시에 들어와서 오류를 발생시키는 상황 또는 문제. (aka 따닥) ↩
-
유의미한 실험이 되기 위해 통계적인 방법을 사용하여 최소한의 실험 진행 기간을 가이드해 줍니다. 참고 사이트 ↩























![[Project Loom] Virtual Thread에 봄(Spring)은 왔는가](/_astro/thumb.I22_MPmz_1XD63p.webp)

















![[if kakao 2022] Batch Performance를 고려한 최선의 Aggregation](/_astro/thumb.MGIp4JrG_2cerCK.webp)
![[if kakao 2022] Batch Performance를 고려한 최선의 Reader](/_astro/thumb.CZPDDx8q_221xKf.webp)