시작하며
안녕하세요. 카카오페이에서 비즈플랫폼을 개발하고 있는 마틴입니다.
지난 번에 Jackson Deserializer 코드 분석해보기라는 글로 기술 공유를 드렸는데요, 많은 성원과 응원…은 없었지만🥲 (역시 관심을 이끌어내려면 어그로를… ‘스프링에서 json도 못쓰는 멍청한 개발자들 봐라’라고 제목을 했다면…? 악플도 관심이라 치면 저는 이미 셀럽) 지금이라도 늦지 않았습니다. 구독과 좋아요, 알림 설정을…
두 번째 주제로 Spring Bean Injection에 대한 코드 분석기를 공유하려고 합니다. Spring은 직관적인 사용과 편리한 기능을 통해 개발의 허들을 많이 낮춰주고 있는 프레임워크이기에 Bean이라는 것과 Injection이라는 것을 따로 공부하시거나 고민해보신 분들이 적을 것으로 생각됩니다. Bean에 대해서 그냥 ‘@Autowired 붙이면 가져다 쓸 수 있다’, ‘Singleton으로 생성된다’ 이 정도의 지식으로도 충분하게 우리가 원하는 서비스를 개발하고 비즈니스를 만들어낼 수 있습니다. 하지만 실제로 엔터프라이즈급의 코드를 운영해보시면 어떤가요? 우리가 하고 있는 많은 일들이 디버깅하고 오류를 수정하고 데이터를 보정하는 일들입니다. ‘근본적으로 코드에 손을 대는 순간부터 버그는 잠재되어 있다’고 하지만 그것으로 우리가 겪고 있는 오류와 버그들을 합리화 할 수는 없을 것 같습니다. 사실 많은 부분이 스프링을 너무 쉽게 썼기 때문에, 사실은 잘 모르고 사용하고 있는 경우가 많았던 것입니다.
그중에서 일부인 @Primary와 @Qualifier 어노테이션이 있을 경우에 어떻게 Bean이 Injection 되는지를 소스기반으로 분석하여 내용을 공유합니다. 오픈소스를 공유하다보니 글 자체가 조금 길어지기도 하지만, 천천히 한 번 읽어보시길 권해드립니다. 혹시 너무 바쁜 개발자분이 있으시다면 제일 하단에 ‘6줄 요약’을 함께 제공하고 있습니다.
사건의 시작
때는 바야흐로 가맹점 관리 시스템 고도화 작업을 할 때입니다. 연말 평가와 연초 계획으로 지친 심신을 코딩으로 풀어볼 심산이었는데… (개발자는 일할 때 코딩하고, 쉴 때 코딩하고, 리프레시가 필요할 때 코딩합니다 맞죠?)
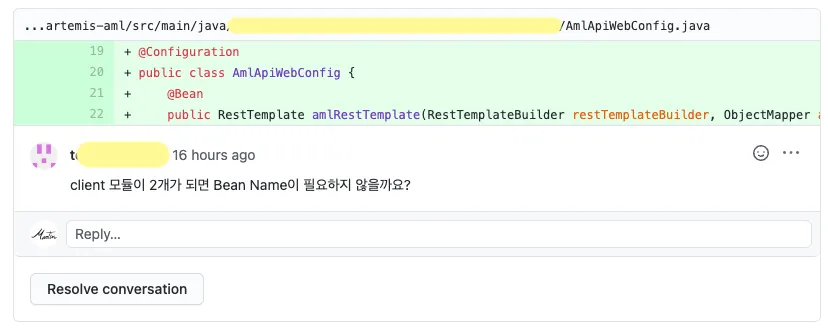
제가 만든 PR에 이런 리뷰가 달렸습니다. 갑자기 전두엽이 띵~하면서 어떻게 답변을 써야할지 몰랐습니다. 제가 띵~하고 순간 얼어붙은 이유는, ‘아… 예전에 기억으로는 뭔가 naming base로 bean injection이 됐던 것 같은데?’ 라는 생각이었습니다. 여기서 중요한 건 ‘됐던 것 같은데?’ 라는 것은 개발자의 언어가 아니라는 점입니다. 그래서 된다는 거야, 아닌거야. 확실하지 않… (말잇못) 개인적인 취향으로는 @Qualifier 어노테이션을 그리 좋아하지 않습니다. 이름을 대체할 거라면 모르는데, 보통 같은 필드명을 두 번씩 중복하여 기재하는 것이 대부분이기 때문입니다. 경력이 쌓이고 시니어가 되는게 기본적으로 역량의 성장을 의미하지는 않습니다. 단지 경험이 더 많이 쌓일 뿐이고, 역량의 성장은 별도의 노력이 더 필요합니다. 그래서!! 구글에 검색을 해보기 시작했습니다.
검색어 : spring, bean, injection, byName, byType
붉은 강낭콩 판매가 왠말…ㅠ.ㅠ 사실 너무 general한 단어들이기도 하고, byName, byType은 최근에는 사용하지 않는 속성인지 xml로 된 Spring 문서만 잔뜩 나왔습니다.
(잠시 삼천포로…)
구글은 모든 개발자의 친구이자, 독이 든 성배일 수도 있습니다. 개발자들은 단지 블로그 포스팅 날짜를 보고 최신이라 착각하지만, 실상은 옛날 기술을 답습하곤 합니다. 예를 한번 들어보겠습니다. 누군가 2015년에 버그를 수정하기 위해 A를 적용했습니다. 그리고 공유는 개발자의 기본 소양이기에 블로그를 쓰고 구글에 공개되었죠. 다른 사람이 2016년에 버그를 고치려다가 그 글을 보고 A를 적용했습니다. 버그가 해결되었습니다. 그래서 자신의 블로그에 글을 썼습니다. 또 다른 사람이 2017년에 2016년 블로그를 보고 A를 적용하고 버그를 해결했습니다. (반복) 어떤 사람이 2023년에 2022년 최신(?) 해결책을 구글에서 검색해서 적용해서 해당 문제를 해결했습니다. 하지만, 사실 내용을 들여다보면 최근 내용이 아닙니다. 알고보니 2015년 해결책이었던 셈입니다. 대부분의 오픈소스들은 하위 호환을 잘 지키기 때문에 해결은 됐지만 최선의 선택으로 볼 수 없습니다. 이미 해당 오픈소스는 그 문제의 해결책을 내재화시켜서 더 편리하고 안정적인 방법을 제공했기 때문입니다. 그럼에도 2023년에 새로운 방법을 적용한 사람의 블로그는 도큐먼트 랭킹의 하위에 있고, 2015~2022년의 글을 서로의 연관링크가 걸리고 더 많은 사람들이 클릭을 했습니다. 때문에 2023년에도 여전히 2015년 시리즈의 글이 더 높은 랭크를 받고 상위에 노출됩니다.
그래서 개발자들의 친구인 구글에게 조언을 살짝 구해보고, 진리를 찾아서 실제 스프링 코드를 탐색해 보게 됩니다.
‘라떼는 말이야…☕️ 소스도 없이 jar로 묶여서 배포된 오픈소스 javap로 디컴파일해서 보고 그랬다. 요즘은 소스까지 다 배포되는데, 배가 불렀…’ (카카오페이의 공식적인 입장이 아님을 밝힙니다)
빈 주입에 대해 스프링 코드 뜯어보기
스프링에서 bean을 주입하는 코드는 아래처럼 DefaultListableBeanFactory.doResolvedDependency()부터 살펴보려고 합니다.
public class DefaultListableBeanFactory extends AbstractAutowireCapableBeanFactory
implements ConfigurableListableBeanFactory, BeanDefinitionRegistry, Serializable {
...
@Nullable
public Object doResolveDependency(DependencyDescriptor descriptor, @Nullable String beanName,
@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {
InjectionPoint previousInjectionPoint = ConstructorResolver.setCurrentInjectionPoint(descriptor);
try {
Object shortcut = descriptor.resolveShortcut(this);
if (shortcut != null) {
return shortcut;
}
Class<?> type = descriptor.getDependencyType();
Object value = getAutowireCandidateResolver().getSuggestedValue(descriptor);
if (value != null) {
if (value instanceof String strValue) {
String resolvedValue = resolveEmbeddedValue(strValue);
BeanDefinition bd = (beanName != null && containsBean(beanName) ?
getMergedBeanDefinition(beanName) : null);
value = evaluateBeanDefinitionString(resolvedValue, bd);
}
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
try {
return converter.convertIfNecessary(value, type, descriptor.getTypeDescriptor());
}
catch (UnsupportedOperationException ex) {
// A custom TypeConverter which does not support TypeDescriptor resolution...
return (descriptor.getField() != null ?
converter.convertIfNecessary(value, type, descriptor.getField()) :
converter.convertIfNecessary(value, type, descriptor.getMethodParameter()));
}
}
Object multipleBeans = resolveMultipleBeans(descriptor, beanName, autowiredBeanNames, typeConverter);
if (multipleBeans != null) {
return multipleBeans;
}
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);
if (matchingBeans.isEmpty()) {
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
return null;
}
String autowiredBeanName;
Object instanceCandidate;
if (matchingBeans.size() > 1) {
autowiredBeanName = determineAutowireCandidate(matchingBeans, descriptor);
if (autowiredBeanName == null) {
if (isRequired(descriptor) || !indicatesMultipleBeans(type)) {
return descriptor.resolveNotUnique(descriptor.getResolvableType(), matchingBeans);
}
else {
// In case of an optional Collection/Map, silently ignore a non-unique case:
// possibly it was meant to be an empty collection of multiple regular beans
// (before 4.3 in particular when we didn't even look for collection beans).
return null;
}
}
instanceCandidate = matchingBeans.get(autowiredBeanName);
}
else {
// We have exactly one match.
Map.Entry<String, Object> entry = matchingBeans.entrySet().iterator().next();
autowiredBeanName = entry.getKey();
instanceCandidate = entry.getValue();
}
if (autowiredBeanNames != null) {
autowiredBeanNames.add(autowiredBeanName);
}
if (instanceCandidate instanceof Class) {
instanceCandidate = descriptor.resolveCandidate(autowiredBeanName, type, this);
}
Object result = instanceCandidate;
if (result instanceof NullBean) {
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
result = null;
}
if (!ClassUtils.isAssignableValue(type, result)) {
throw new BeanNotOfRequiredTypeException(autowiredBeanName, type, instanceCandidate.getClass());
}
return result;
}
finally {
ConstructorResolver.setCurrentInjectionPoint(previousInjectionPoint);
}
}
...
}사실 위 PR에서 리뷰한 내용은 여러 개의 같은 타입의 bean이 있을 때(물론, bean 자체는 singleton이기 때문에 name은 유일합니다) 어떻게 bean을 주입하는지가 중요합니다. 그래서 아래 로직으로 좁혀볼 수 있습니다.
(코드에서 특별한 부분이 보여서 잠시 샛길)
일단 Bean이 없는 경우에 Runtime에 NullPointerException이 발생합니다. 그런 이유로 @Autowired를 활용한 Field Injection은 deprecated되고 요즘엔 (주로 Lombok의 @RequiredArgConstructor를 통한) Constructor Injection을 활용합니다.
그 부분이 아래와 같은 코드로 인해서 발생하는 것입니다. 결국 matching되는 bean이 없으면 return null이 됩니다. Field Injection의 경우에는 null이 될 것이고, Constructor Injection의 경우에는 final 접근자로 인해서 bean Injection 시점(spring context loading시)에 오류가 발생합니다.
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);
if (matchingBeans.isEmpty()) {
if (isRequired(descriptor)) {
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
return null;그리고 다시 본론으로 돌아오면, findAutowireCandidates()에서 bean injection의 후보군을 추렸을 때, 1개인 경우 바로 주입되고, 여러 개인 경우에는 다시 determineAutowireCandidate()를 실행하게 됩니다. size()는 0이상의 자연수이기 때문에 음수는 없을 것이고, 0은 앞의 로직에서 빠졌고, 2이상은 determinAutowireCandidate()를 타기 때문에, else가 1의 경우로 암묵적 처리됩니다.
(사실 가독성 측면에서는 직관적일 수 있겠지만, 로직(statement)들이 순서를 보장받아야 하는 경우여서, 잠재적으로는 오류가 발생할 수 있는 포인트라고 생각 합니다)
String autowiredBeanName;
Object instanceCandidate;
if (matchingBeans.size() > 1) {
autowiredBeanName = determineAutowireCandidate(matchingBeans, descriptor);
if (autowiredBeanName == null) {
if (isRequired(descriptor) || !indicatesMultipleBeans(type)) {
return descriptor.resolveNotUnique(descriptor.getResolvableType(), matchingBeans);
}
else {
// In case of an optional Collection/Map, silently ignore a non-unique case:
// possibly it was meant to be an empty collection of multiple regular beans
// (before 4.3 in particular when we didn't even look for collection beans).
return null;
}
}
instanceCandidate = matchingBeans.get(autowiredBeanName);
}
else {
// We have exactly one match.
Map.Entry<String, Object> entry = matchingBeans.entrySet().iterator().next();
autowiredBeanName = entry.getKey();
instanceCandidate = entry.getValue();
}일단, findAutowireCandidates()를 살펴보겠습니다. Candidate라는 메서드 네이밍처럼, 주입할 후보 대상을 찾습니다. 사실상 구글에 byType, byName 검색어로 검색을 했을 때, spring xml 설정에는 있는데, 요즘 문서가 검색되지 않는 이유인 것 같습니다.(삼천포에서 말씀드린 것처럼 이미 내재화 개선됨) 예전에는 명시적으로 bean injection을 타입으로 할지, 이름으로 할지 선택해야 했다면, 요즘에는 타입이든 이름이든 모두 candidate로 만들어두고, 그중에서 가장 적합한 bean을 선택하게 되는 것 같습니다.
protected Map<String, Object> findAutowireCandidates(
@Nullable String beanName, Class<?> requiredType, DependencyDescriptor descriptor) {
String[] candidateNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
this, requiredType, true, descriptor.isEager());
Map<String, Object> result = CollectionUtils.newLinkedHashMap(candidateNames.length);
for (Map.Entry<Class<?>, Object> classObjectEntry : this.resolvableDependencies.entrySet()) {
Class<?> autowiringType = classObjectEntry.getKey();
if (autowiringType.isAssignableFrom(requiredType)) {
Object autowiringValue = classObjectEntry.getValue();
autowiringValue = AutowireUtils.resolveAutowiringValue(autowiringValue, requiredType);
if (requiredType.isInstance(autowiringValue)) {
result.put(ObjectUtils.identityToString(autowiringValue), autowiringValue);
break;
}
}
}
for (String candidate : candidateNames) {
if (!isSelfReference(beanName, candidate) && isAutowireCandidate(candidate, descriptor)) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
if (result.isEmpty()) {
boolean multiple = indicatesMultipleBeans(requiredType);
// Consider fallback matches if the first pass failed to find anything...
DependencyDescriptor fallbackDescriptor = descriptor.forFallbackMatch();
for (String candidate : candidateNames) {
if (!isSelfReference(beanName, candidate) && isAutowireCandidate(candidate, fallbackDescriptor) &&
(!multiple || getAutowireCandidateResolver().hasQualifier(descriptor))) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
if (result.isEmpty() && !multiple) {
// Consider self references as a final pass...
// but in the case of a dependency collection, not the very same bean itself.
for (String candidate : candidateNames) {
if (isSelfReference(beanName, candidate) &&
(!(descriptor instanceof MultiElementDescriptor) || !beanName.equals(candidate)) &&
isAutowireCandidate(candidate, fallbackDescriptor)) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
}
}
return result;
}이제는 determineAutowireCandidate() 로직을 볼 차례입니다. 사실 앞의 코드까지는, (나름 시니어의…) 경험과 촉에 따른 지식과 거의 일치합니다. 사실 제가 경험으로 이미 알고 있던 것을 명확하게 확실할 수 있는 재확인 과정이었습니다. 그런데, 이 다음 부분 코드부터는 가슴이 서늘해지고, 제가 전혀 몰랐으면서도, 자칫 잘못하면 대형 오류가 발생할 수도 있는 부분이 있었습니다.(그래서 개발자는 코드가 정답지… Don’t trust anyone.)
@Nullable
protected String determineAutowireCandidate(Map<String, Object> candidates, DependencyDescriptor descriptor) {
Class<?> requiredType = descriptor.getDependencyType();
String primaryCandidate = determinePrimaryCandidate(candidates, requiredType);
if (primaryCandidate != null) {
return primaryCandidate;
}
String priorityCandidate = determineHighestPriorityCandidate(candidates, requiredType);
if (priorityCandidate != null) {
return priorityCandidate;
}
// Fallback
for (Map.Entry<String, Object> entry : candidates.entrySet()) {
String candidateName = entry.getKey();
Object beanInstance = entry.getValue();
if ((beanInstance != null && this.resolvableDependencies.containsValue(beanInstance)) ||
matchesBeanName(candidateName, descriptor.getDependencyName())) {
return candidateName;
}
}
return null;
}위 코드를 보면, @Primary 어노테이션이 있으면 선주입하게 됩니다. 사실 @Priority 어노테이션은 사용해 본적이 없어서 몰랐지만, jakarta (javax)에서 @Primary처럼 제공하는 어노테이션인 것 같고, 해당 어노테이션은 @Primary보다는 후순위로 주입됩니다. 그리고 아무런 어노테이션도 없는 경우에는, bean 중에서 beanName 기반으로 값을 가져오게 됩니다.
여기서 중요한 것!
@Primary가 있고 Multiple Bean Candidate가 있는 경우에는 이름이고 뭐고 무조건 @Primary가 가장 우선되어 적용된다는 사실입니다. 누군가 해당 Type의 Bean을 @Primary로 적용해놨다면 (사실 어노테이션 기반의 코딩이, 코드 커플링을 낮춰놓은 편이라, 남이 저렇게 해놓은 것을 본인이 코딩하는 시점에 알기 어렵습니다) 묵시적인 bean name을 무시하고 @Primary가 주입되는 (무서운) 오류가 발생할 것입니다.
(솔직히 테스트 같은 거 하거나 spring loading 할 때, bean이 여러 개라 ambigouos하다고 오류나면, 아묻따 @Primary 달아서 해결하신 경험… 다들 있으시잖아요;;)
문서를 정리하다보니, 그러면 @Primary와 @Qualifier를 경쟁붙이면 누가 이길 것인가? 당연히 @Qualifier가 이기는 것이 더 직관적일 것으로 생각되는데, 맞는지 내용을 좀더 찾아보겠습니다. (또 사설) 문서를 정리하거나, 누군가에게 정보를 전달하는 행위가 개발자에게 중요한 것은, 이 케이스처럼 그 행위를 위해 더 분석하고 더 찾아보면서 스스로의 역량을 더 발전시키기 때문입니다.
findAutowireCandidates()를 실행하기 전 코드블록에 다음과 같은 코드가 있습니다.
Class<?> type = descriptor.getDependencyType();
Object value = getAutowireCandidateResolver().getSuggestedValue(descriptor);
if (value != null) {
if (value instanceof String strValue) {
String resolvedValue = resolveEmbeddedValue(strValue);
BeanDefinition bd = (beanName != null && containsBean(beanName) ?
getMergedBeanDefinition(beanName) : null);
value = evaluateBeanDefinitionString(resolvedValue, bd);
}
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
try {
return converter.convertIfNecessary(value, type, descriptor.getTypeDescriptor());
}
catch (UnsupportedOperationException ex) {
// A custom TypeConverter which does not support TypeDescriptor resolution...
return (descriptor.getField() != null ?
converter.convertIfNecessary(value, type, descriptor.getField()) :
converter.convertIfNecessary(value, type, descriptor.getMethodParameter()));
}
}여기서 중요한 부분이 getAutowireCandidateResolver().getSuggestedValue()입니다. AutowireCandidateResolver.getSuggestedValue()는 default로 null을 반환하고 있으나, interface로 정의되어 있습니다. 구현체를 찾아보면 QualifierAnnotationAutowireCandidateResolver.getSuggestedValue()를 사용하고 있습니다. (오늘 사설이 많네요) 클래스 이름을 보면, 옛날처럼 짧게 줄이는 것보다 길더라도 명확한 네이밍을 쓰는 것이 트렌드인 것 같습니다. 제발 쓰지 말아주세요 getUdtdttm() ㅠ.ㅠ
/**
* Determine whether the given dependency declares a value annotation.
* @see Value
*/
@Override
@Nullable
public Object getSuggestedValue(DependencyDescriptor descriptor) {
Object value = findValue(descriptor.getAnnotations());
if (value == null) {
MethodParameter methodParam = descriptor.getMethodParameter();
if (methodParam != null) {
value = findValue(methodParam.getMethodAnnotations());
}
}
return value;
}
/**
* Determine a suggested value from any of the given candidate annotations.
*/
@Nullable
protected Object findValue(Annotation[] annotationsToSearch) {
if (annotationsToSearch.length > 0) { // qualifier annotations have to be local
AnnotationAttributes attr = AnnotatedElementUtils.getMergedAnnotationAttributes(
AnnotatedElementUtils.forAnnotations(annotationsToSearch), this.valueAnnotationType);
if (attr != null) {
return extractValue(attr);
}
}
return null;
}
/**
* Extract the value attribute from the given annotation.
* @since 4.3
*/
protected Object extractValue(AnnotationAttributes attr) {
Object value = attr.get(AnnotationUtils.VALUE);
if (value == null) {
throw new IllegalStateException("Value annotation must have a value attribute");
}
return value;
}그래서 @Qualifier 어노테이션을 사용하면, Multiple Bean을 검색하기 전에 있는지 없는지 찾아보고 Bean Injection을 시키고 없으면 오류를 발생시킵니다. 즉, @Qualifier 어노테이션이 @Primary 어노테이션에 우선하여 적용됩니다.
(테스트를 통해서) 내용을 씹고 뜯고 맛보고 즐겨보자
개발자라면 코드만 보고 다 믿을 수 없습니다(라고 개인적으로 생각합니다, Don’t trust anyone again) 내 눈으로 보기 전까진 절대 못 믿겠다, 라고 생각하는 훌륭한 개발자 분들을 위해서 테스트를 만들어서 확인해겠습니다.
아래처럼 코드를 만들었고, 같은 Type의 각각 다른 method name으로 bean을 생성하고 주입되는 것을 확인해보겠습니다.
@Configuration
public class FooConfig {
@Bean
public ObjectMapper fooObjectMapper() {
return new ObjectMapper();
}
@Bean
public ObjectMapper barObjectMapper() {
return new ObjectMapper();
}
}
@SpringBootTest
@ActiveProfiles("test")
public class FooTest {
@Autowired
private ObjectMapper fooObjectMapper;
@Autowired
private ObjectMapper barObjectMapper;
@Test
void test() {
System.out.println(">>> " + fooObjectMapper);
System.out.println(">>> " + barObjectMapper);
}
}결과를 보면, 분명 서로 다른 bean class가 주입되었습니다.
>>> com.fasterxml.jackson.databind.ObjectMapper@539f0729
>>> com.fasterxml.jackson.databind.ObjectMapper@ebad9a거기에 또다른 Autowired를 만들어 보겠습니다.
@SpringBootTest
@ActiveProfiles("test")
public class FooTest {
@Autowired
private ObjectMapper fooObjectMapper;
@Autowired
private ObjectMapper barObjectMapper;
@Autowired
private ObjectMapper zzzObjectMapper;
@Test
void test() {
System.out.println(">>> " + fooObjectMapper);
System.out.println(">>> " + barObjectMapper);
System.out.println(">>> " + zzzObjectMapper);
}
}그러면 결과는? 위 코드에서 봤던 것처럼 autowiredCandidate로 같은 타입인 fooObjectMapper와 barObjectMapper를 가져왔지만, 매핑을 할 수 없어서 오류가 발생합니다.
Caused by: org.springframework.beans.factory.NoUniqueBeanDefinitionException: No qualifying bean of type 'com.fasterxml.jackson.databind.ObjectMapper' available: expected single matching bean but found 2: fooObjectMapper,barObjectMapperObjectMapper Bean 하나를 제거해보겠습니다.
@Configuration
public class FooConfig {
@Bean
public ObjectMapper fooObjectMapper() {
return new ObjectMapper();
}
// @Bean
// public ObjectMapper barObjectMapper() {
// return new ObjectMapper();
// }
}그러면 결과는 정상적으로 매핑이 됩니다. multiple candidate가 아니라 1개만 존재하기 때문에, Type base로 bean 주입이 일어났습니다.
>>> com.fasterxml.jackson.databind.ObjectMapper@4c3133a1
>>> com.fasterxml.jackson.databind.ObjectMapper@4c3133a1
>>> com.fasterxml.jackson.databind.ObjectMapper@4c3133a1주석은 다시 해제하고 @Qualifier를 붙여서 해봅니다.
@Autowired
@Qualifier("barObjectMapper")
private ObjectMapper zzzObjectMapper;그러면 Qualifier에 맞는 bean name으로 주입이 일어납니다.
>>> com.fasterxml.jackson.databind.ObjectMapper@639f7054
>>> com.fasterxml.jackson.databind.ObjectMapper@26f6fbbd
>>> com.fasterxml.jackson.databind.ObjectMapper@26f6fbbd만약, Qualifier를 잘못 쓰면 어떻게 될까요? (물론 요즘 IDE는 너무 좋아서, 인텔리제이 컴파일타임에 오류를 알려줍니다)
@Autowired
@Qualifier("anObjectMapper")
private ObjectMapper zzzObjectMapper;방금 전에 했던 것과는 다른 에러 메시지가 발생합니다. multiple candidate 로직까지 가지 못한 걸 확인할 수 있습니다.
Caused by: org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type 'com.fasterxml.jackson.databind.ObjectMapper' available: expected at least 1 bean which qualifies as autowire candidate. Dependency annotations: {@org.springframework.beans.factory.annotation.Autowired(required=true), @org.springframework.beans.factory.annotation.Qualifier("anObjectMapper")}위에서 제 간담을 서늘하게 했던 @Primary를 테스트해보겠습니다.
@Bean
@Primary
public ObjectMapper fooObjectMapper() {
return new ObjectMapper();
}Bean Name과 관련없이 일괄 @Primary Bean으로 꽂아버립니다. (이정도면 bean 주입도 아닙니다. 냅다 꽂아버리는…)
>>> com.fasterxml.jackson.databind.ObjectMapper@639f7054
>>> com.fasterxml.jackson.databind.ObjectMapper@639f7054
>>> com.fasterxml.jackson.databind.ObjectMapper@639f7054여기에서 @Primary와 @Qualifier 어노테이션의 싸움을 붙여 보도록 하겠습니다.
@Configuration
public class FooConfig {
@Primary
@Bean
public ObjectMapper fooObjectMapper() {
return new ObjectMapper();
}
@Bean
public ObjectMapper barObjectMapper() {
return new ObjectMapper();
}
}방금 전의 테스트를 다시 한번 더 반복해 보겠습니다.
@SpringBootTest
@ActiveProfiles("test")
public class FooTest {
@Autowired
private ObjectMapper fooObjectMapper;
@Autowired
private ObjectMapper barObjectMapper;
@Test
void test() {
System.out.println(">>> " + fooObjectMapper);
System.out.println(">>> " + barObjectMapper);
}
}예상처럼 @Primary Bean으로 모두 도배해 버립니다.
>>> com.fasterxml.jackson.databind.ObjectMapper@73ae82da
>>> com.fasterxml.jackson.databind.ObjectMapper@73ae82da위 테스트에서 @Qualifier를 붙여보도록 하겠습니다.
@SpringBootTest
@ActiveProfiles("test")
public class FooTest {
@Autowired
private ObjectMapper fooObjectMapper;
@Autowired
@Qualifier("barObjectMapper")
private ObjectMapper barObjectMapper;
@Test
void test() {
System.out.println(">>> " + fooObjectMapper);
System.out.println(">>> " + barObjectMapper);
}
}결과적으로 서로 다른 Bean이 매핑됩니다. 무적 @Qualifier 입니다.
>>> com.fasterxml.jackson.databind.ObjectMapper@687e561b
>>> com.fasterxml.jackson.databind.ObjectMapper@299786b16줄 요약
바쁜 현대인 개발자를 위한 6줄 요약을 제공해 드립니다.(대충(?)보고 어서 개발하셔야 하니까요…)
- @Bean 으로 bean을 생성하게 되면, method name이 bean name으로 생성된다.
- 같은 Type의 bean이 1개만 있다면, bean name과 관련없이 bean을 주입해준다.
- 같은 Type의 bean이 여러 개 있으면, @Qualifier가 없어도 bean name과 field name을 매칭해서 bean을 주입해준다.
- (!) @Primary가 있으면, bean name을 무시하고 Type 기반으로 Primary인 Bean을 주입한다.
- @Qualifier가 있으면, 무조건 bean name 기준으로 주입해준다. (없으면 오류가 발생한다)
- @Qualifier 어노테이션이 @Primary 어노테이션보다 우선하여 적용된다.
마치며
스프링에 대한 실전 책들이 많습니다. 저도 많은 도움을 받고 있고, 책을 쓰시는 분들은 저보다 훌륭한 개발자들이십니다. 그러나 오픈소스는 책이 출판되는 것보다 빠른 속도로 변화하고 있습니다. 책으로 지식을 쌓고 자신의 코드를 개발하는 것만으로는 조금 부족한 경우가 많습니다. 내가 작성한 코드는 아니지만, 시간날 때 혹은 좀더 의식적으로 노력해서 오픈소스를 열어보고 하나씩 어떻게 동작하는지를 살펴보신다면 더 정확한 동작을 이해하실 수 있습니다.
컴퓨터 프로그래머는 0과 1을 다루는 직업입니다. 하지만 정작 우리는 ‘아마도 될 껄’, ‘해보니까 되더라’, ‘그냥 그렇게 하면 되더라’ 하는 식의 개발 지식을 가지고 있지 않나요? 오늘 제가 포스팅한 글에서 부족한 부분이 있을 수도 있습니다. 하지만 이 포스팅이 보시는 분들께 오픈소스를 열어서 동작원리를 한번씩 볼 수 있는 계기를 제공할 수 있다면 이 포스팅의 목적을 다 했다고 이야기 할 수 있을 것 같습니다. 아무쪼록 개발자가 되기를 원하는 분들, 이미 개발자로서 활동하고 계신 분들 모두 좋은 개발자가 되시길 간절히 기원합니다.

도움이 되셨다면 구독, 좋아요, 알림 설정, 채용 지원 꾹꾹꾹~. 아, 카카오페이 기술블로그 관심 많이 가져주세요 😊
기술 제보
개발자에게 공유가 중요한 것은 위에 사설로 썼던 것처럼 스스로 역량을 발전시키는 부분도 있지만, 제가 부족한 부분에 대한 다른 전문가의 조언을 받을 수도 있기 때문입니다. 이 포스팅을 쓰고 나서, 팀내의 다른 개발자가 추가적인 제보를 해주셔서 첨부합니다.
질문:
일반적으로 compile 시점에 argument의 이름이 지워질텐데, java에서 spring loading시에는 runtime이고, bean name을 알지 못해서 name base의 bean 주입이 안될 것 같은데요?
자답:
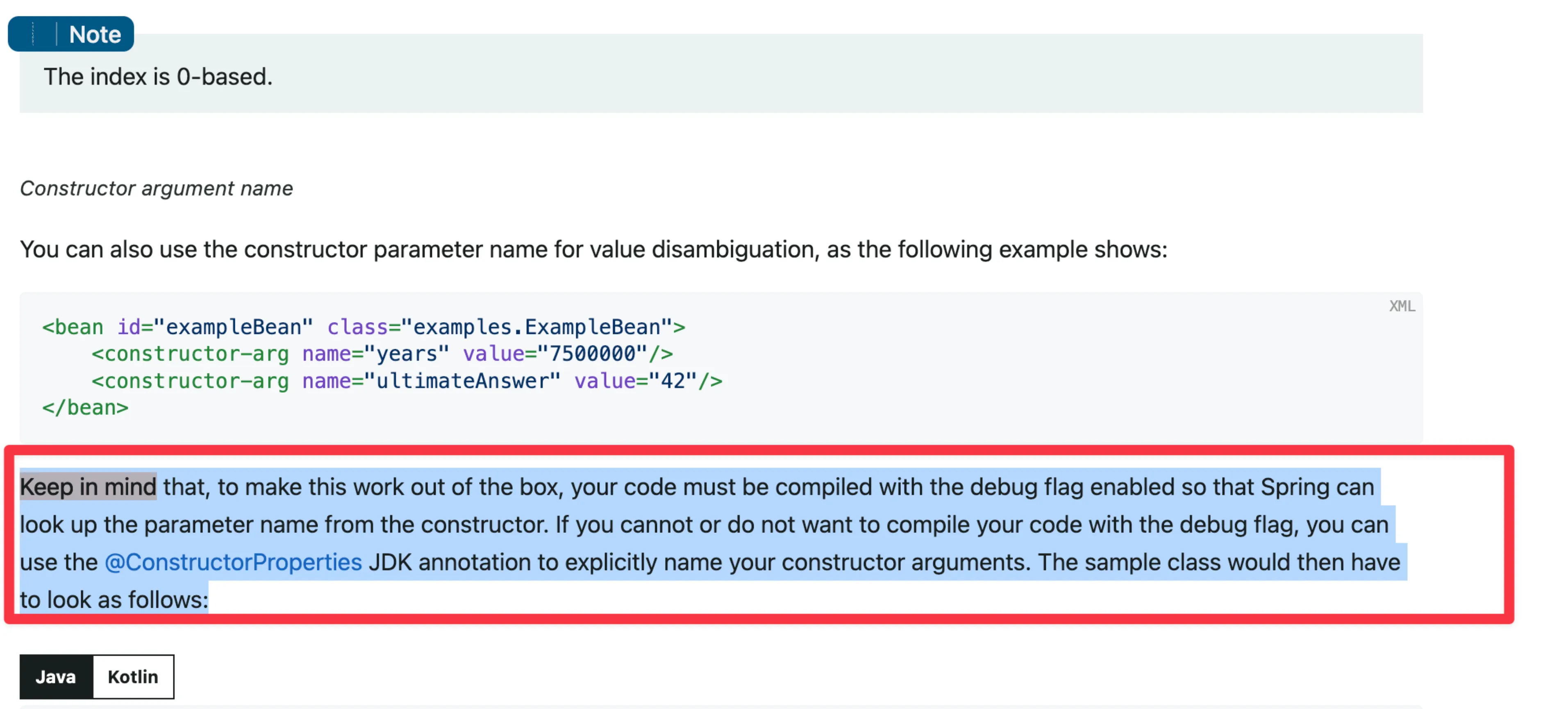
constructor의 경우 javac -parameter 옵션이 켜져 있어야 compile time에도 name이 argN과 같이 지워지지 않고 살아남습니다. 이걸 안 쓴다면 ConstructorProperties MarkAnnotation에 접어넣어서 런타임까지 가져가야 합니다. Spring은 이것을 사용하고 있어서 ByName Inject이 잘 되는 것 같습니다.
참조 링크

























![[Project Loom] Virtual Thread에 봄(Spring)은 왔는가](/_astro/thumb.I22_MPmz_1XD63p.webp)

















![[if kakao 2022] Batch Performance를 고려한 최선의 Aggregation](/_astro/thumb.MGIp4JrG_2cerCK.webp)
![[if kakao 2022] Batch Performance를 고려한 최선의 Reader](/_astro/thumb.CZPDDx8q_221xKf.webp)