시작하며
안녕하세요, 카카오페이 온라인 결제 서비스에서 백엔드 개발을 맡고 있는 브리입니다. 카카오페이 온라인 결제 서비스는 카카오페이 내에서 가장 오래된 서비스 중 하나인데요. 그만큼 서비스 크기가 크기도 하고, 트래픽 양도 지속적으로 성장하고 있는 서비스입니다. 매년 카카오페이 온라인 결제의 경우 가장 큰 결제량을 처리하는 날이 있습니다.
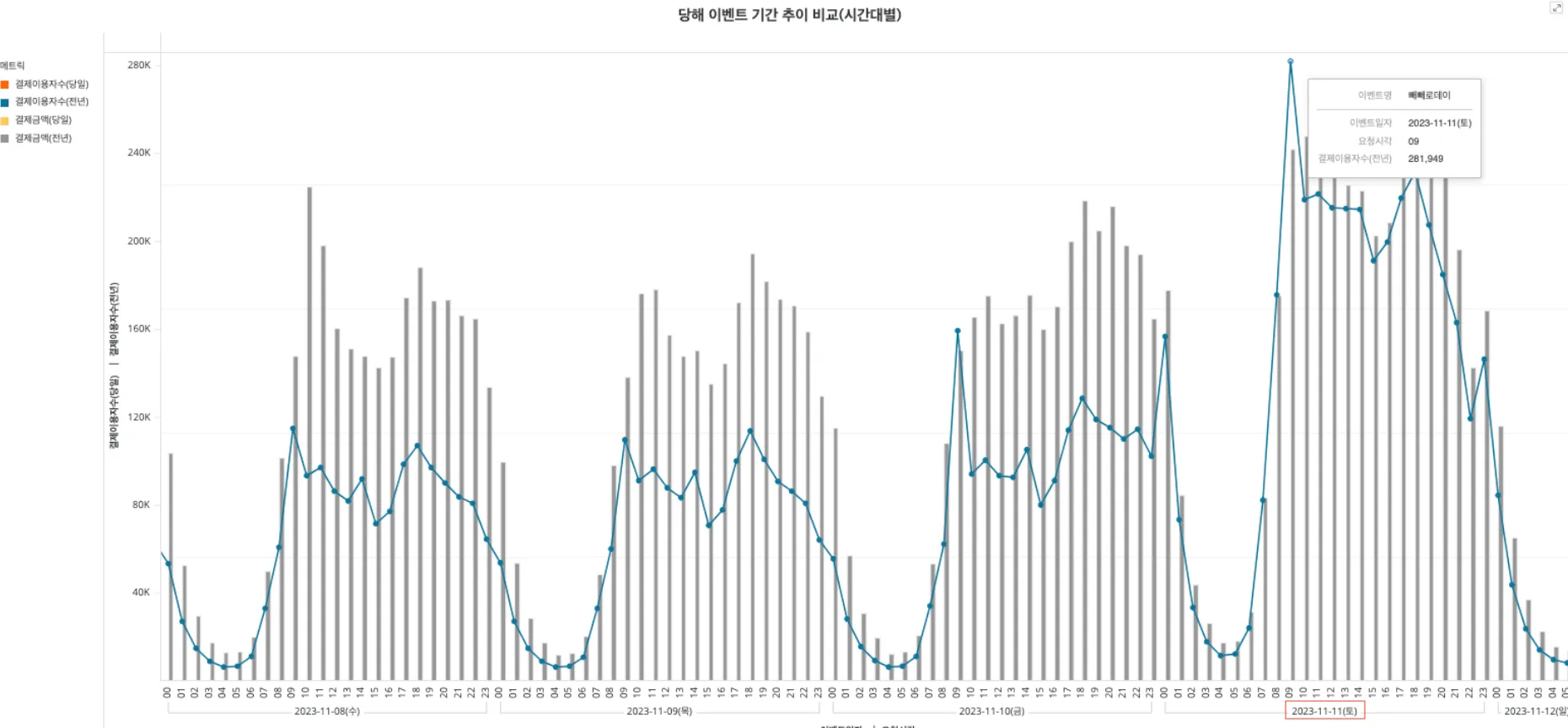
바로 11/11일 빼빼로데이입니다. 평소보다 3-5배 정도의 트래픽이 더 들어오고 매년 성장하는 서비스인 만큼 예상으로는 200 TPS 정도는 견뎌야 한다는 미션이 있었습니다. 그리고 여기에 11번가에 카카오페이 결제가 추가되는 게 올해 하나의 이벤트였습니다. 11번가는 매년 11/11일에 맞춰서 큰 이벤트를 하는지라 적어도 약 100 TPS는 더 처리해야 한다는 미션이 생겼죠. 평소 40-50 TPS를 처리하고 있는 온라인 결제 서비스에서 이번 11/11일 대비 총 300 TPS를 견뎌야 한다는 미션이 생겼고, 이에 따라 성능 개선 니즈 또한 분명해졌습니다. 지금부터 이 과정을 적어보려 합니다. 레거시한 시스템과 성능 개선 니즈를 같이 갖고 계신 분들이라면 카카오페이 온라인 결제 서비스 기록을 보시고 좋은 인사이트를 얻어 가시면 좋을 것 같습니다.
온라인 결제 서비스란?
가장 먼저 온라인 결제에 대해서 간략하게 말씀드려야 하는데요. 카카오페이 온라인 결제 서비스는 온라인으로 연결된 가맹점에서 결제 서비스를 담당합니다.
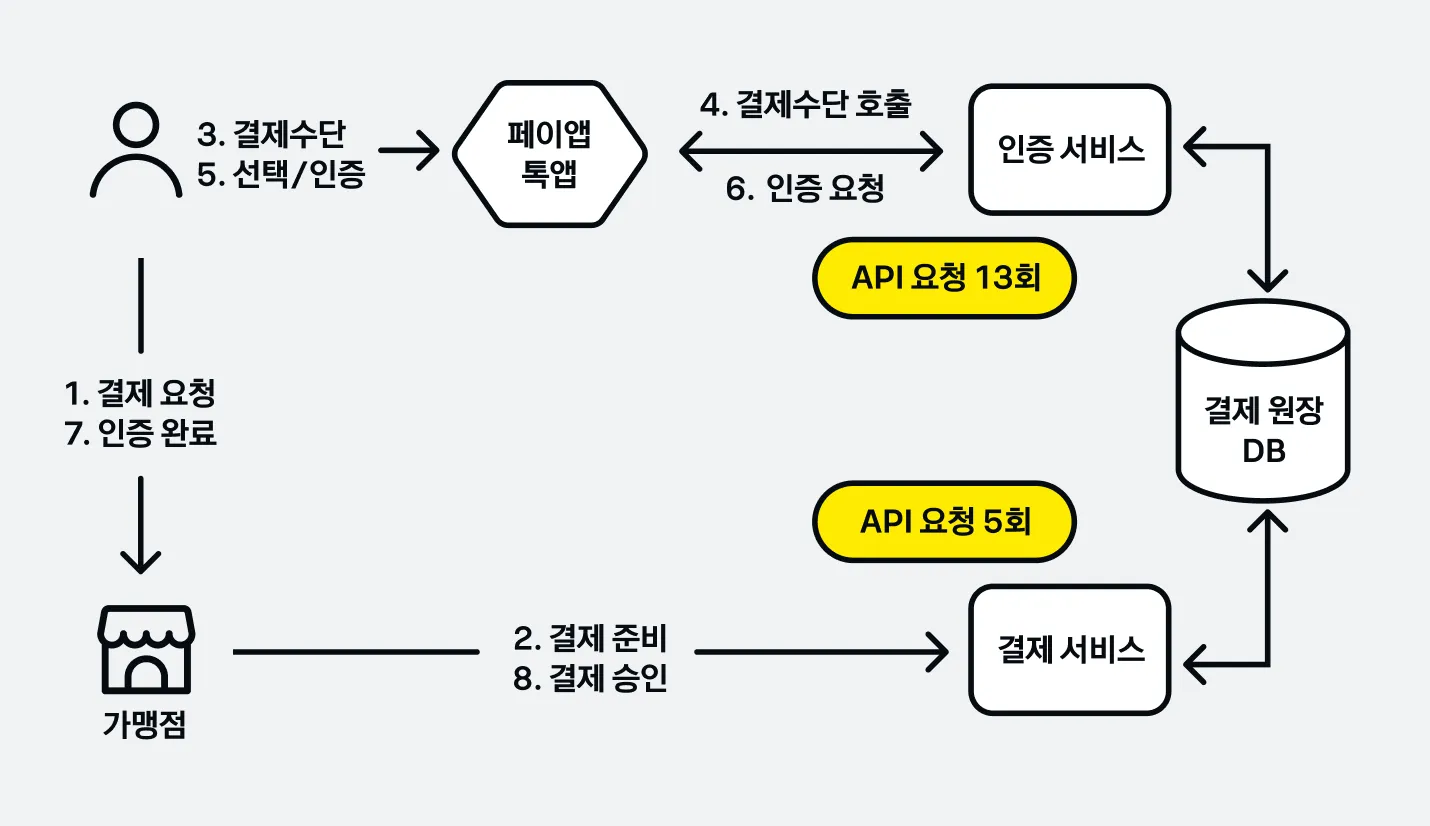
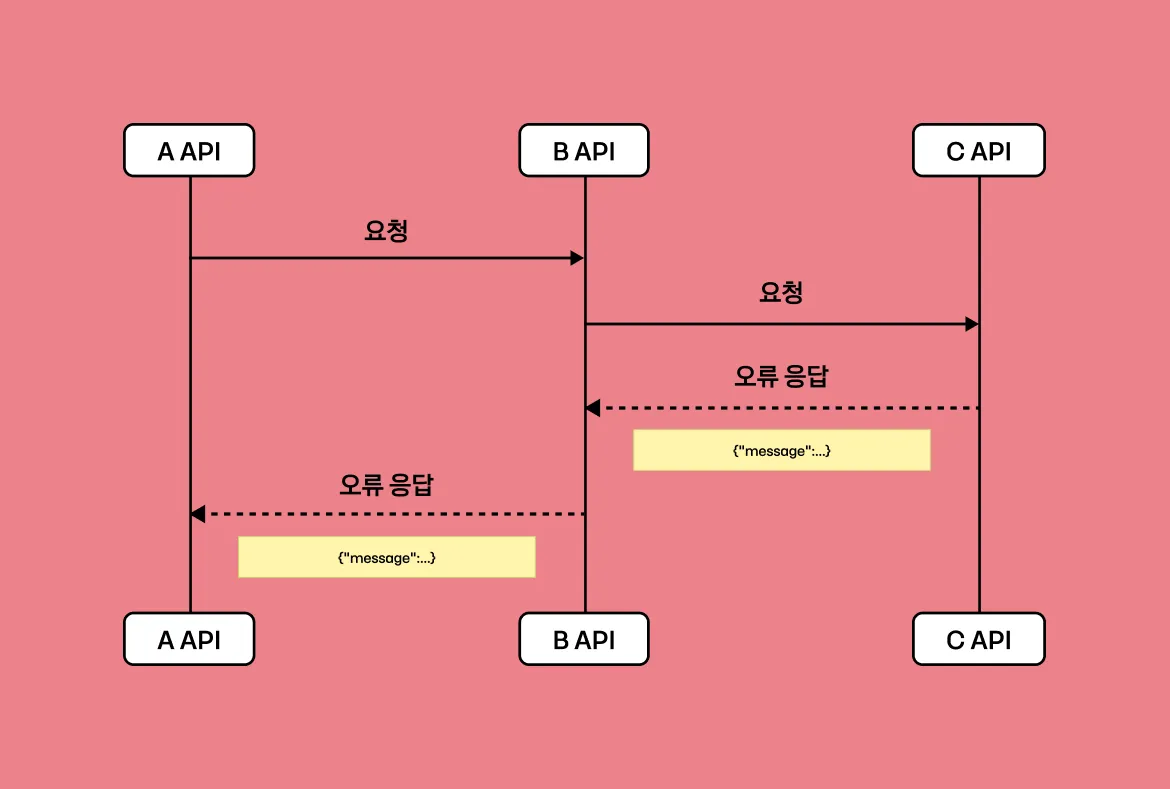
위 그림과 같이 하나의 결제 안에 여러 동작이 진행되는데요. 가맹점이 결제 준비 요청을 하고 나면 유저가 결제창을 카카오 톡이나 페이 앱으로 띄우게 되고, 그러고 나면 인증 서비스에서 약 10-13 단계의 긴 인증 요청을 처리합니다. 이후 인증 완료한 상태로 사용자가 원래 가맹점 앱으로 돌아가면 가맹점이 결제 서비스로 확인 및 승인 요청을 하게 됩니다. 이러한 일련의 과정이 하나의 결제 트랜잭션이고, 그 안에서 카카오 온라인 결제 서비스는 약 16-20개의 API를 호출합니다.
저희는 사내에서 현재 모니터링 지표를 결제 건 기준으로 TPS1(Transaction Per Second, 이하 TPS)를 정하고 있는데요, 개선 전 기준 150 TPS를 최대치로 잡았었고 이때에 실제 온라인 결제 서비스는 API2(Application Programming Interface, 이하 API) 요청 기준으로 약 2,700 TPS 정도가 나옵니다.
성능 개선 결정 원인
1. 너무 많은 QPS 증가와 그에 따른 DB CPU 사용량 문제
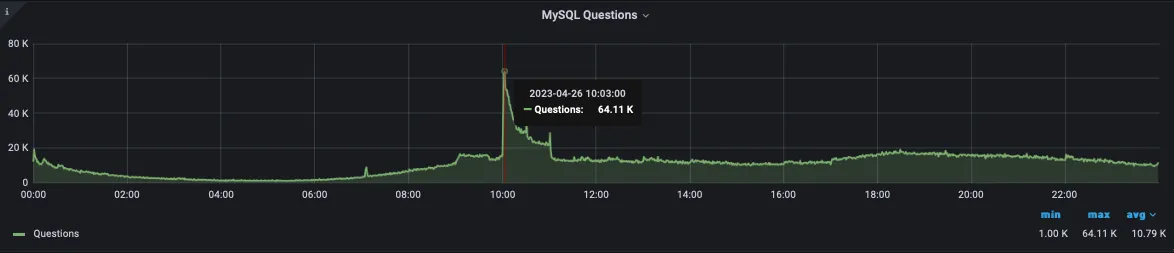
4월 중 나이키에서 프로모션을 진행했습니다. SNKRS 앱에서 10시마다 평상시에 팔지 않는 레어 아이템을 럭키 드로우로 정가에 판매하는 프로모션인데요. 이때 판매하는 나이키의 조던 농구화 등의 아이템은 리셀을 하게 되면 더 높은 금액으로 팔 수 있기 때문에 사람들이 많이 몰립니다. 이 프로모션에 주요 결제 중 하나로 카카오페이 결제가 있었고 선착순은 아니지만 10시부터 10시 30분까지만 판매가 열려서 10시를 기준으로 급격하게 트래픽이 몰리는 현상이 있었고, 이벤트 시작과 동시에 결제량이 급격하게 많아지면서 동시에 QPS3(Query Per Second, 이하 QPS)도 많아졌었습니다.
아래 그림은 당시 DB CPU 사용량 지표입니다.
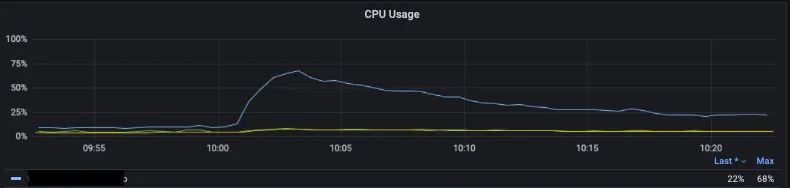
롱 쿼리도 아닌 순수하게 QPS가 넘쳐서 생긴 CPU 사용량 경고였고, 다행(?)인지 불행인지 조회 쿼리가 총쿼리의 98%를 차지하고 있었습니다.
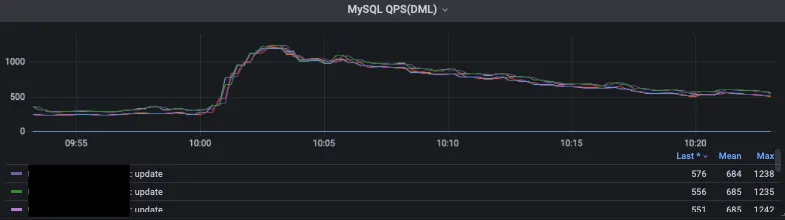
2. 너무 긴 Transaction 길이
다음은 4월 11일 나이키에서 프로모션을 진행했던 다른 날의 SLOW QUERY 분석 로그입니다. 이날은 설정 이슈가 있어서 DB 로그를 확인했었는데요.
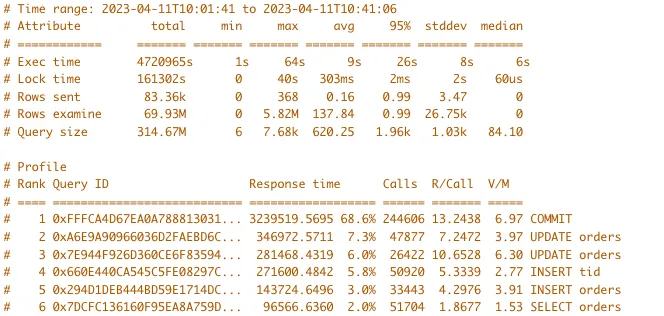
해당 로그를 보니 다량의 COMMIT 쿼리가 SLOW QUERY로 잡혀 있었습니다. 이건 Transaction 시간이 길었다는 것을 의미합니다.
개선 방향
위와 같은 이유들로 자체적으로 성능 테스트 진행했습니다.
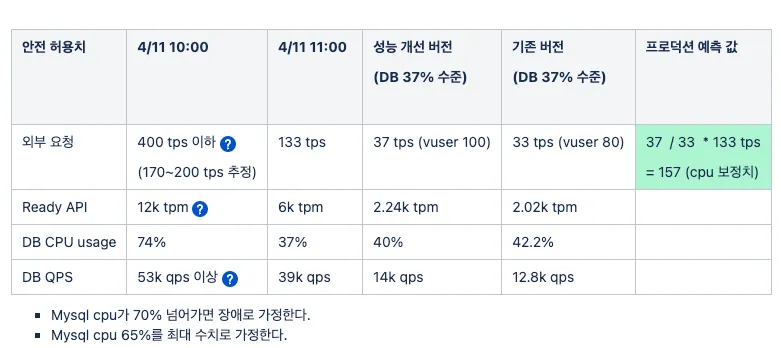
테스트 결과, 안전 허용치로는 157 TPS가 가능한 것으로 나왔습니다. 따라서 올해 빼빼로데이 목표인 300 TPS를 처리하기 위해서는 적어도 2배의 성능을 개선해야 했습니다. 결제 서비스가 인증 서비스, 결제 서비스 두 개의 모듈로 크게 분리되어 있어 DB 분리도 고려를 했었습니다. 하지만 다음 이유로 성능 개선 개발을 우선 진행하기로 했습니다.
- 전산 원장이라 DB 분리가 쉽지 않다(정산팀, 어드민 등 다른 팀, 서비스 여파)
- 서비스 애플리케이션 상 CPU 사용량은 여유가 넘쳐난다.
- 일정이 촉박하다.
- 레거시 시스템이라 비즈니스 로직 상 개선 여지가 많다.
이와 같은 이유로 DB CPU 사용량을 줄이는 목적으로 성능 개선 개발을 진행하게 되었습니다.
성능 개선 1. QPS를 줄이기 위한 노력
1.1 비즈니스 로직에 녹여 적용한 Redis 처리
4월 트래픽이 증가했던 시기에 API 지표들을 확인하던 중 특이사항을 발견했습니다.
Metric 상 나타났던 API TPM
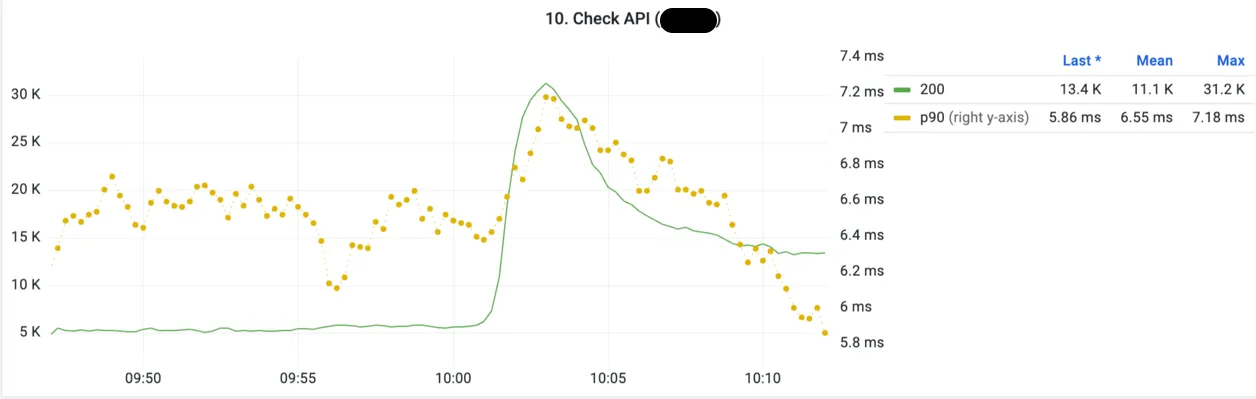
위 그림은 처음에 나온 60K QPS로 DB에 과부하가 될 때의 특정 API 그래프입니다. 결제 상태를 체크하는 Check API의 TPM (Transaction Per Minute, 이하 TPM) 그래프인데요. 다른 API들의 평균 TPM이 3-4K였던 거에 비하면 10배 수준이었습니다. 해당 API가 결제 인증 상태를 따로 조회하는 API였고 결제하려는 유저들이 몰리면서 인증 과정 자체가 길어지다 보니 결제 건 당 해당 API 요청 수가 많아지면서 전체 API 요청 수가 크게 많아졌었습니다.
우선 선적용 해본 redis 조회
그래서 우선적으로 Check API가 DB를 조회하기보다 Redis에 결제 상태를 저장하고 Redis 조회를 하도록 적용합니다. 논리적으로는 Cache의 의미였지만 결국 해당 API는 실시간으로 변화하는 결제 상태에 대한 조회였기 때문에 결국 각 결제 단계 변경 시점마다 상태 업데이트를 해줘야 했습니다. 따라서 매 결제 단계마다 Redis 업데이트 요청이 필요했고 Check API에서는 해당 Redis를 조회하도록 적용이 되었습니다. 이 적용 방법은 캐싱이라기보단 Sub로 사용되는 MemoryDB 활용의 느낌이었습니다. 이는 당연히 비즈니스 로직 복잡도 증가를 야기하고 장기적으로 볼 때에 필요 없어질 수 있는 로직이라 유지 보수에 악영향을 미칩니다. 따라서 다른 방향의 개선이 완료되면 지워질 코드로 만들었습니다.
1.2 Entity 기준에서의 Redis Cache와 Spring CacheManager
캐시를 비즈니스에 녹여 적용하기보다 캐시답게 Entity 기준으로 DB 조회를 기준으로 제한적으로 캐시를 적용하기로 했습니다. Redis cache는 기본적으로 immutable한 데이터 위주로 작업했고요. 중요한 mutable 테이블 하나가 조회 량이 많아서 몇 가지 설정을 이용해 entity caching 처리를 했습니다. mutable한 캐시의 경우 CacheManager에서 CachePut을 사용했는데요. 여기서 동시성 이슈가 나타납니다.
Cacheable과 CachePut의 충돌 그리고 데이터 정합성 문제
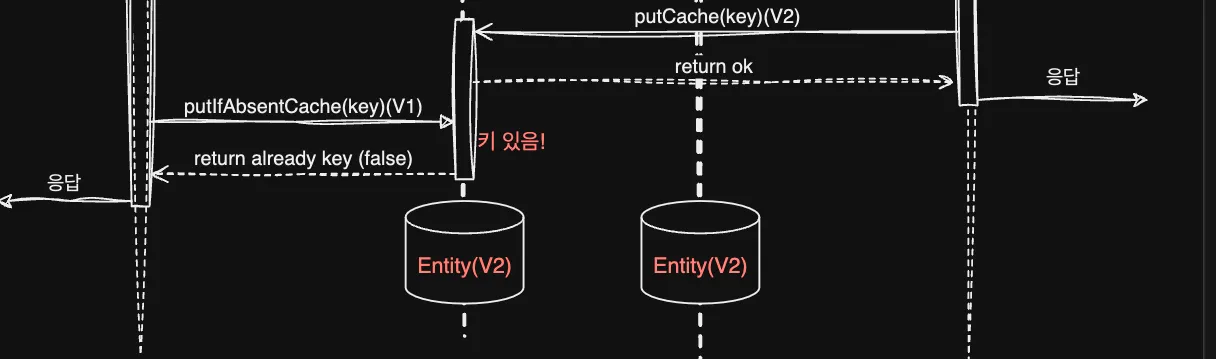
Cacheable과 CachePut 사이의 동시성 이슈가 나타나 데이터 정합성이 깨지는 현상이 발생했는데요. 우선 cacheable 동작의 순서도를 봅시다.
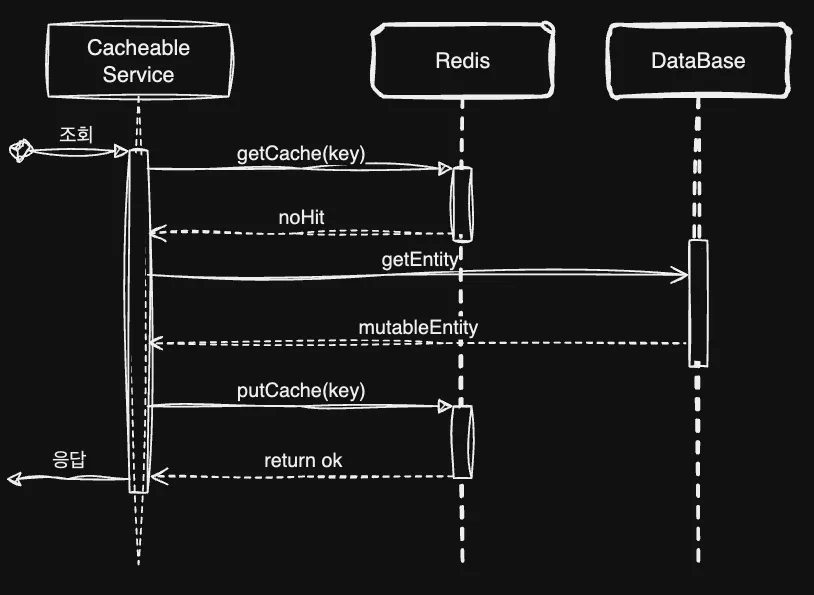
다음과 같이 조회 후 없으면 DB에서 가져오는 순서입니다. 다음은 CachePut입니다.
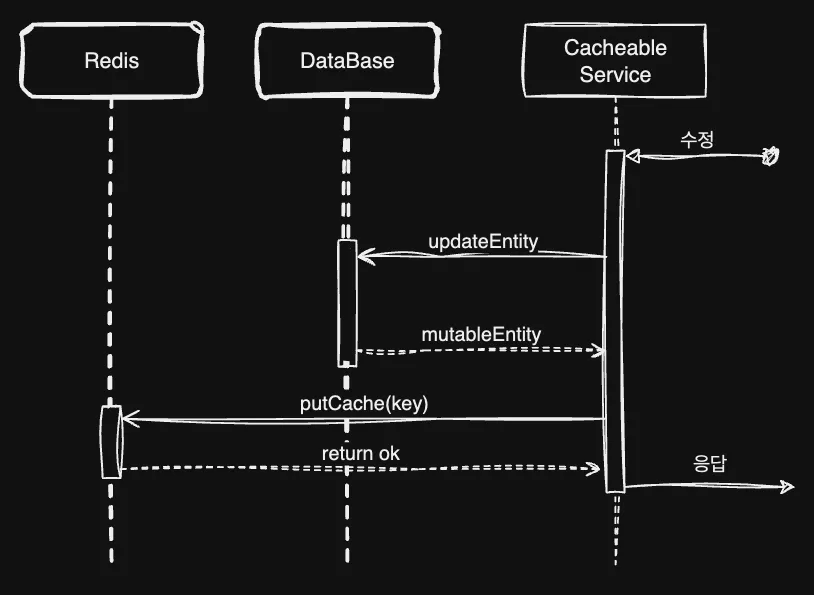
Cacheable과 같지만 최초 캐시가 존재하는지 확인하지 않는다는 특징이 있죠. 이 두 가지 조회가 동시에 여러 인스턴스, 서로 다른 서비스에서 만나게 되면 데이터 정합성에 오류가 일어납니다.
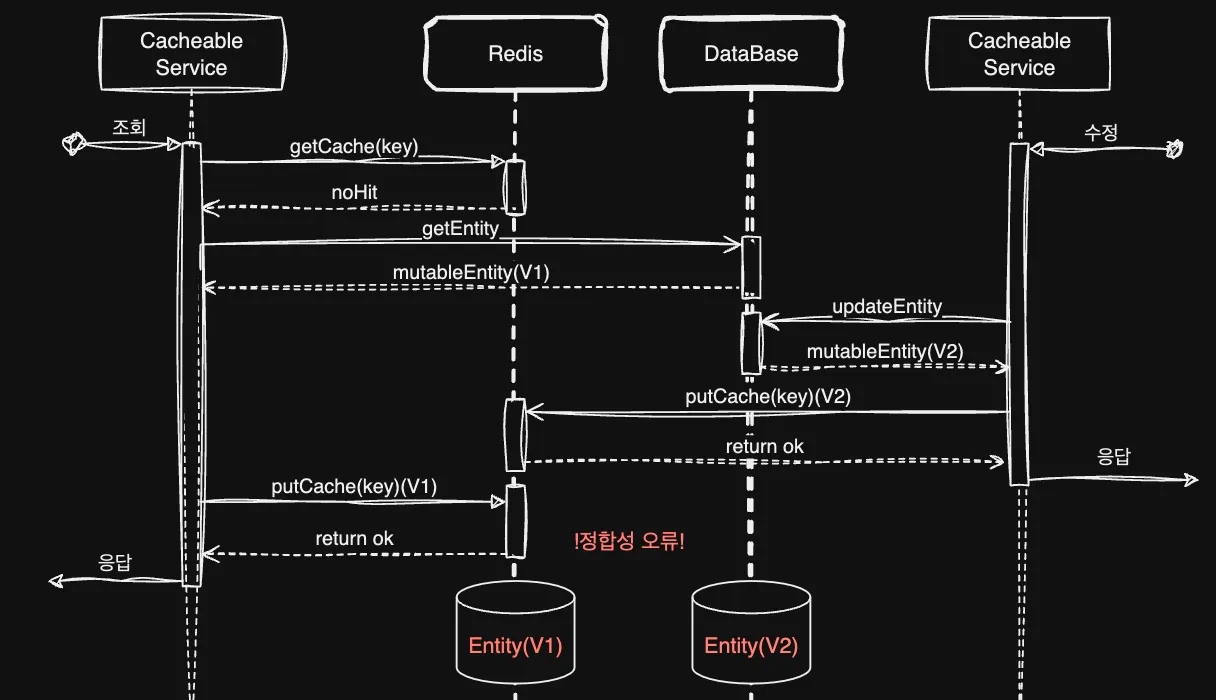
보시면 CachePut 동작으로 Database에서 이미 V2로 업데이트가 되었지만 이후 putCache 동작이 Cacheable이 모종의 이유로 더 늦게 수행하게 되어 redis 안에서는 V1으로 다시 덮어 씌는 현상이 발생합니다. 이렇게 인스턴스 및 서비스가 여러 개 걸쳐 있기 때문에 redis 자체는 singleThread를 지원한다 하더라도 정합성 문제가 생길 수 있습니다.
해결 방법
해결법은 단순합니다. Cacheable 동작 시 putCache를 안 하면 됩니다. 다만 이렇게 되면 Cacheable 동작의 기댓값이 달라지게 되겠죠 (no hit 시 caching을 진행하고 추후 조회 시 hit 기대) 이렇게 의도치 않은 동작(CachePut으로 누군가 caching)을 기대해야 하기 때문에 다른 방식을 선택하게 되는데요. cacheable 동작 시에만 putCache 대신 putIfAbsent (데이터 없을 시 insert)를 수행하는 방법입니다.
CacheManager 설정 방법
우선 put 대신 putIfAbsent를 사용하도록 proxy RedisCacheWriter를 만들고요.
// DefaultRedisCacheWriter 를 계승하는 프록시 클래스
public class PutToPutIfAbsentRedisCacheWriterProxy implements RedisCacheWriter {
//...
//프록시 객체
private final RedisCacheWriter proxyObject;
private PutToPutIfAbsentRedisCacheWriterProxy(RedisCacheWriter proxyObject) {
this.proxyObject = proxyObject;
}
// put 요청 시 put 대신 putIfAbsent
@Override
public void put(String name, byte[] key, byte[] value, Duration ttl) {
proxyObject.putIfAbsent(name, key, value, ttl);
}
//...
}cacheable, cachePut 따로 동작해야 하기 때문에 각각 cacheManager를 만들고 operation에 맞춰서 cacheManger가 적용되게끔 설정하면 됩니다.
@EnableCaching
@Configuration
public class CacheConfig {
@AutoWired
private RedisCacheWriter redisCacheWriter;
@Bean("cacheableCacheManger")
public RedisCacheManager cacheableManager() {
return RedisCacheManager.builder()
.cacheWriter(
new PutToPutIfAbsentRedisCacheWriterProxy(redisCacheWriter))
.build();
}
@Bean("cachePutCacheManger")
public RedisCacheManager cachePutManager() {
return RedisCacheManager.builder()
.cacheWriter(redisCacheWriter)
.build();
}
// cacheable 일때만 proxyManger 쓰게끔 설정
@Bean
@Override
public CacheResolver cacheResolver() {
CacheManager cacheableManager = cacheableManager();
CacheManager cachePutManager = cachePutManager();
return (context) -> {
Collection<Cache> caches = new ArrayList<>();
if (context.getOperation() instanceof CachePutOperation) {
caches.add(cachePutManager.getCache(context.getOperation().getCacheNames().iterator().next()));
} else {
caches.add(cacheableManager.getCache(context.getOperation().getCacheNames().iterator().next()));
}
return caches;
};
}
}주의할 점
완벽하지 못한 동시성 해결
다만 이 방법이 완벽하지는 않습니다. 기본적으로 CachePut 끼리의 동시성은 해결되지 않습니다. 완벽한 동시성을 제공하려면 결국 분산 lock을 고려해 봐야 하죠. 온라인 결제 서비스의 경우 캐싱 대상이 되는 mutable 한 테이블이 1개에 불과하고 해당 테이블 또한 하나의 key 기준으로는 동시 업데이트가 일어날 구간이 없습니다. 온라인 결제 일련의 과정을 담는 테이블이기 때문이죠. (요청, 인증, 승인) 그래서 성능 개선이 중요한 상황에서 lock 과정을 필요 없이 넣어서 redis로의 요청 구간을 늘리는 것보다는 저희 서비스에 맞는 정도로만 설정했습니다.
또한 cachePut 상황에서 timeout 또는 redis 실패 시에도 정합성 오류가 납니다. cache의 기본 속성이 속도를 위한 임시 저장소라 cacheable 내부에서의 redis 호출 오류는 간단한 로깅 후 서비스 진행을 시키도록 했지만, cachePut의 경우에는 에러 응답을 하도록 적용했습니다. 결제의 경우 무엇보다 데이터 정합성이 중요하기도 하고, 최근 3년간 redis 가용률 100%였던 걸 고려해서 적용했습니다.
redis timeout 설정
위에 cacheable 설명을 드린 것과 같이 성능 개선을 위해 로직이 추가가 되었지만 결과적으로는 API 콜 수가 0-2개 늘어납니다. 기존 DB 조회 1건이었던 로직이, cache Hit일 경우엔 redis 콜 1개로 동일하지만 nohit 시 cache 조회, DB 조회, cache 삽입으로 3개로 늘어나죠. 만약 이 상황에 redis에서 timeout이 발생한다면 서비스 지연 구간이 더 늘어나게 됩니다. 그래서 저희는 redis 평균 응답 시간(4ms)을 고려해 timeout 설정을 100ms로 비교적 짧게 잡았습니다.
성능 개선 2. Transaction 길이를 줄이기 위한 노력
우선 내부 비즈니스 로직에 Transaction 처리 구간들을 살펴보기 시작했습니다. 하지만 Transaction 구간들은 나름 잘 분리가 되어 있었고 해당 구간 안에서 다른 API를 요청한다던가 하는 등의 특이한 구간은 없었습니다.
2.1 OSIV 설정과 커넥션 풀 이슈
다시 한번 봤더니 OSIV4 설정이 default (true) 상태 그대로 있었습니다. 이 경우 tomcat thread가 아무리 많아도 db connection pool 개수에 따라서 스레드 사용량이 제한되기 때문에 application 성능을 충분히 쓰지도 못하고 요청받은 스레드 전 구간에 Transaction이 걸려있어 3rdParty 요청/응답받는 구간이 DB Transaction에 포함 되게 되어서 DB cpu 사용량에도 영향을 많이 미칩니다.
따라서 OSIV를 제거하기로 했습니다. OSIV를 제거할 경우 api 요청 전 구간에 걸려있던 Transactional 이 없어지면서 lazy loading 이슈가 생길 수가 있어 상당히 귀찮은 작업이었는데요. 다행히 직전에 서비스 개선 활동으로 JPA EntityGraph 제거, Entity 대신 Dto 쿼리 작업을 진행한 이후여서 부담스럽지 않게 진행할 수 있었습니다.
추가. Monitoring의 중요성 (feat. APM)
여기까지 진행한 후 성능 테스트 도중 일정 TPS를 뛰어넘지 못하는 현상이 발생했습니다. Grafana, Matrix5에서 나타나지 않지만 느려지는 구간이 발생했고 현격하게 느려지는 구간에 대해서는 추적이 되지 않는 상황이 발생했습니다.
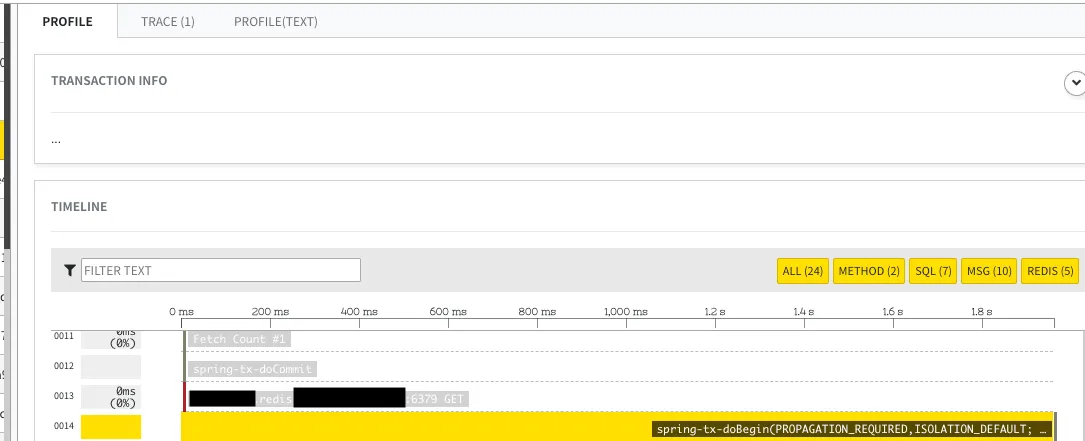
여기서 좌절을 한번 맛보게 되는데요…
최대한 모니터링 불가능한 영역을 줄이기
먼저 Matrix에서 해당 구간을 볼 수 있는 방법이 있는지 확인해 봤습니다.

다른 분의 물음이었는데 최근까지 좌절의 답변이 있었습니다… 그래서 어쩔 수 없이 코드를 파보기 시작했습니다. 그리고 다행히 해결 방법을 (제가 아닌 카카오페이 내부의 다른 분이) 찾아주셨는데요.. 해리 감사합니다 ㅠㅠ
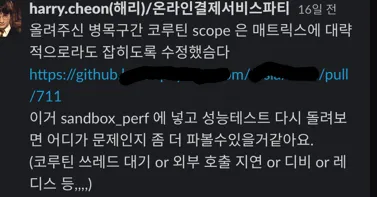
Matrix에서 메서드 호출 시간으로 트래킹을 지원해 주는 부분이 있어서, 코루틴 scope를 줄이고 해당 코루틴 메서드를 트래킹하면 되는데요.
class ApiCallService {
//...
@ApmMethod
private fun apiCallWithCoroutine(): ApiResult {
val apiResult = runBlocking {
// 1. 3rd party 조회1
val callResult1 =
async {
// apiCall1
}
// 1. 3rd party 조회2
val callResult2 =
async {
// apiCall2
}
ApiResult(
callResult1.await(),
callResult2.await(),
)
}
return apiResult
}
}이렇게 하면 해당 호출 구간에 대해서 구분이 가능하고 코루틴 scope 또한 줄일 수 있어서 나머지 로직에 대해 트래킹이 가능합니다.
![]()
그리고 충격적인 결과를 맞이합니다.

왼쪽은 하나의 호출에서 스레드가 동작한 시간 분배고, 오른쪽은 해당 호출에서 외부 호출 수입니다. redis 호출이 226건이었던 것이죠. 목킹을 어느 정도 처리한 성능 테스트용 요청이었다고 해도 너무 많은 호출을 진행하고 있었고 해당 병목구간을 확인하여 코드 개선 수정 작업을 진행하였습니다.
Local Cache까지의 도입
위의 충격적인 결과를 맞이하고 나서 성능 테스트 시 병목 구간이 redis였다는 것을 깨닫고 다시 한번 생각에 잠깁니다. redis 또한 scale out이 쉽지 않고. scale up으로 해결해야 하는 솔루션이며, DB가 감당해야 할 일을 어느 정도 나눠갖는 정도밖에 해결이 되지 않는다는 것을 깨달았습니다. 그래서 immutable 테이블에 대해 로컬 캐시를 추가로 도입했고요, mutable 테이블은 최대한 조회를 적게 하는 방향으로 개선 작업을 진행했습니다.

결과
여기까지 작업을 완료하고 나니 약 2.5배 정도의 성능을 우선적으로 확보할 수 있게 되었습니다.
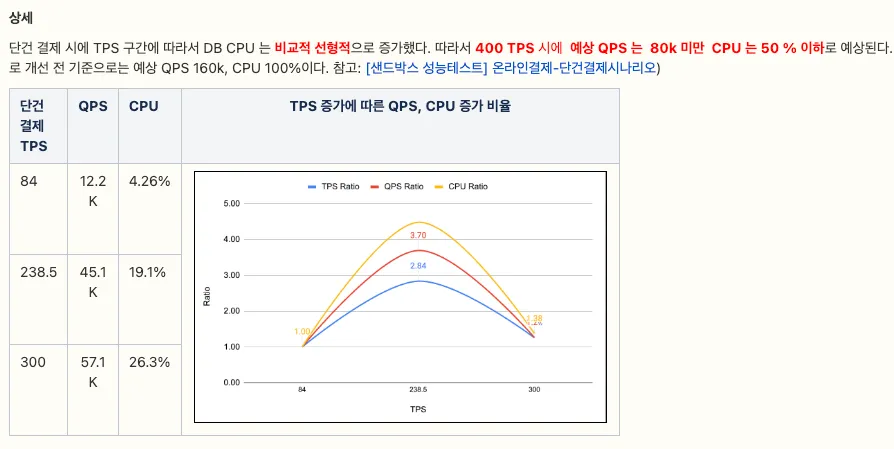
| 비고 | TPS | QPS | DB CPU |
|---|---|---|---|
| 개선 전 | 170 | 53K | 74% |
| 개선 후 | 400 | 80K | 50% |
TPS 기준 QPS가 줄어든 것도 있고 OSIV 제거로 인해 DB CPU 사용량이 적어진 것도 있네요.
마치며
사실 MSA (Micro Service Architecture, 이하 MSA) 전환 중인 레거시 서비스를 맡게 되면서 성능 개선을 하게 되었고, 당장 트래픽이 큰 이벤트를 대응하다 보니 여유가 충분하진 않았습니다. 다른 회사 MSA 전환 과정들을 돌아보지 않고 몸으로 부딪히면서 여러 삽질을 하기도 했지만, 그 와중에 분명 깨달은 점이 있었습니다.
1. Monitoring에 신경을 더 많이 쓰자.
가장 먼저 성능 관련한 지표들을 확인할 수 있는 첫 번째 방법이 이런 Monitoring 시스템입니다. prometheus나 grafana 같은 metric 지표만 봐도 기본적으로 전체 시스템 상 몰리는 병목 구간이 되는 API를 확인할 수 있고, APM을 잘 활용하면 메서드 콜 수, sql 쿼리 수 등의 지표들로 현재 우리 서비스의 상황을 더 자세히 알 수 있어 개선하려는 의지도 더 생기게 되는 것 같습니다. 특히 레거시 시스템의 경우에는 내가 모르는 깊이 숨겨진 로직들이 숨겨져 있어서 쉽게 손대기도 꺼려지는 상황이 나올 수 있는데 해당 구간이 병목인 게 확연히 나타나면 의지를 갖고 수정하게 되는 것 같습니다. 그렇기 때문에 만약 추적이 불가능한 구간들이 있다면 최대한 추적 가능하게끔 수정을 하고 눈으로 각자 서비스의 상태를 봤을 때 더 정확한 대응을 할 수 있을 것 같습니다.
2. Redis가 만능은 아니다.
Redis 또한 결국 그 속성을 보면 하나의 inMemoryDB에 불과합니다. 결국 caching을 위한 여러 방식의 DB를 갖게 되는 상황이 되며 이 redis 또한 리소스가 한계가 있습니다. 가장 좋은 것은 Local Caching 이 효과가 가장 좋으며 비즈니스 로직의 복잡도를 최대한 피하고 싶다면 Transactional 하지 않은, 상태가 잘 변경되지 않는 정보성 데이터에 하시길 바라고 제한적으로 적용하시길 바랍니다.
3. MSA 전환을 진행하면서 DB 분리가 우선적으로 진행돼야 한다.
DB의 경우에는 scale out이 쉽지 않습니다. 이번 성능 이슈 중 하나는 모듈이 분리가 되었는데 큰 관점에서 서비스는 아직 1개여서 (온라인 결제) DB는 아직 1개다 보니 성능 개선 및 MSA 화 이전에 서비스가 먼저 더 빨리 커버려서 나타난 이슈였네요. 이번 개선 작업을 기점으로 앞으로 DB 분리될 방향이 잡혀서 앞으로의 일정이 자연스럽게 나오게 되었습니다. (인증과 결제 승인의 분리)
더 이상 application 서비스 scale out으로 감당이 안 되는 지점이 다가오는 것처럼 느껴지신다면 미리미리 준비하셔서 DB 분리부터 시작해서 서비스 분리를 고려하시길 바랍니다. 감사합니다.
참고 자료
- https://redis.io/commands/set/
- https://docs.spring.io/spring-data-redis/reference/redis/redis-cache.html
Footnotes
-
Transaction Per Second의 약자로 초당 서비스 처리량, 트랜젝션 기준을 어떤 걸로 삼느냐에 따라 달라진다. 여기서는 결제 전체 Transaction 기준, API 요청 기준 2가지 의미로 사용한다. ↩
-
Application Programming Interface의 약자로 서비스가 제공하는 각 요청 단위를 말한다. ↩
-
Query Per Seconds의 약자로 초당 DB 쿼리 요청량. ↩
-
Open Session In View의 약자, 스프링에서 제공하는 방식으로 API 요청 당 DB 트랜젝션을 정의한다. https://www.baeldung.com/spring-open-session-in-view ↩
-
카카오에서 내부에서 사용하는 APM 서비스. ↩























![[Project Loom] Virtual Thread에 봄(Spring)은 왔는가](/_astro/thumb.I22_MPmz_1XD63p.webp)


















![[if kakao 2022] Batch Performance를 고려한 최선의 Aggregation](/_astro/thumb.MGIp4JrG_2cerCK.webp)
![[if kakao 2022] Batch Performance를 고려한 최선의 Reader](/_astro/thumb.CZPDDx8q_221xKf.webp)