시작하며
안녕하세요, 정산플랫폼팀 윤입니다. Spring Batch 애플리케이션 성능 향상을 위해 어떤 방식을 시도해 보셨나요? 성능 향상을 고려할 때, 적절한 접근 방식이 중요합니다. 처음부터 병렬 처리를 도입하여 구조를 크게 변경하는 것보다, 현재의 구조를 크게 바꾸지 않으면서도 성능 최적화를 시도하는 것이 좋습니다. I/O 작업을 한 번에 묶어서 처리하는 등 간단한 변경으로도 큰 성능 향상을 이룰 수 있습니다. 만약 과도한 병렬 처리나 구조적인 큰 변경을 통해 성능을 향상하는데 주력했다면, 이후에 더 큰 성능 향상을 요구할 때 더 많은 비용과 노력이 필요할 수 있습니다. 그러므로 성능 향상의 접근 방식은 신중하게 선택하는 것이 좋습니다.
이번 포스팅에서는 배치 애플리케이션이 어느 구간에서 쉽게 느려지는지 파악하고, 이를 해결하기 위한 방법에 대해 다룹니다. 특히, I/O 작업이 처리 시간에 큰 영향을 주는데, 이를 해결하기 위해 병렬 처리 및 벌크 I/O 처리를 활용하여 I/O 작업의 효율성을 높이는 성능 최적화 방법에 대해 다룹니다. 발표 영상이 궁금한 분들은 아래 링크를 확인해 주세요.
🔗 제2회 Kakao Tech Meet 발표 영상 보러 가기: Spring Batch 애플리케이션 성능 향상을 위한 주요 팁
카카오페이 정산플랫폼팀에서는 Batch 애플리케이션의 Performance를 향상하기 위해 많은 노력을 기울여왔습니다. 자세한 내용은 아래 링크에서 확인해 주세요.
🔗 if(kakao) 발표 영상 보러 가기: Batch Performance 극한으로 끌어올리기
유저 등급 업데이트 Batch

가장 흔한 Batch 애플리케이션 중 하나는 데이터 업데이트입니다. 이는 가맹점 정보 업데이트, 휴면 유저 전환 등과 같은 작업에 사용됩니다. 이 포스팅에서는 최근 거래 내역을 기반으로 유저 등급을 업데이트하는 Batch 애플리케이션을 예로 들겠습니다. 유저 등급은 주문 API를 통해 조회하고 업데이트됩니다.
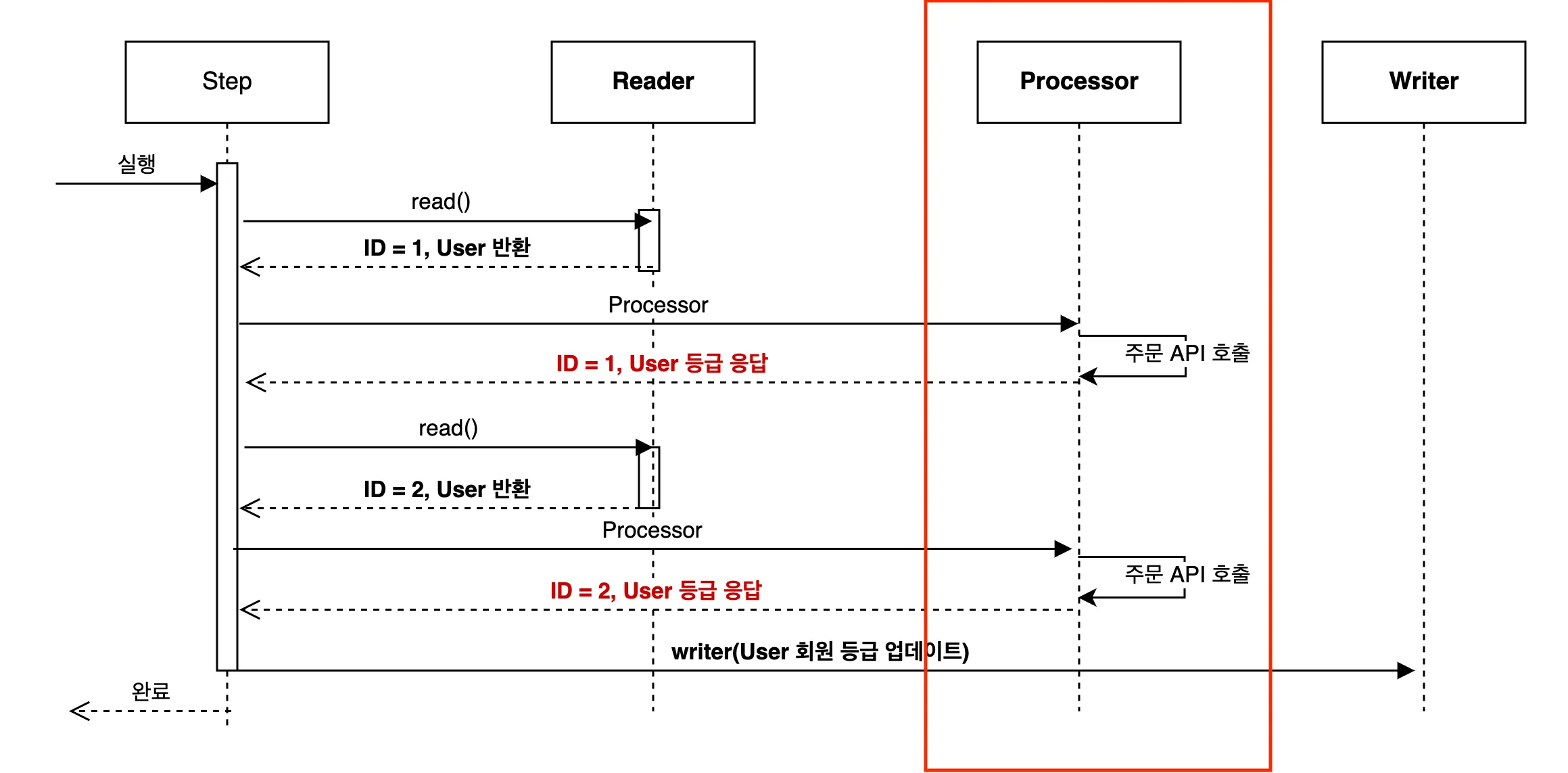
유저 등급 업데이트 Batch Flow
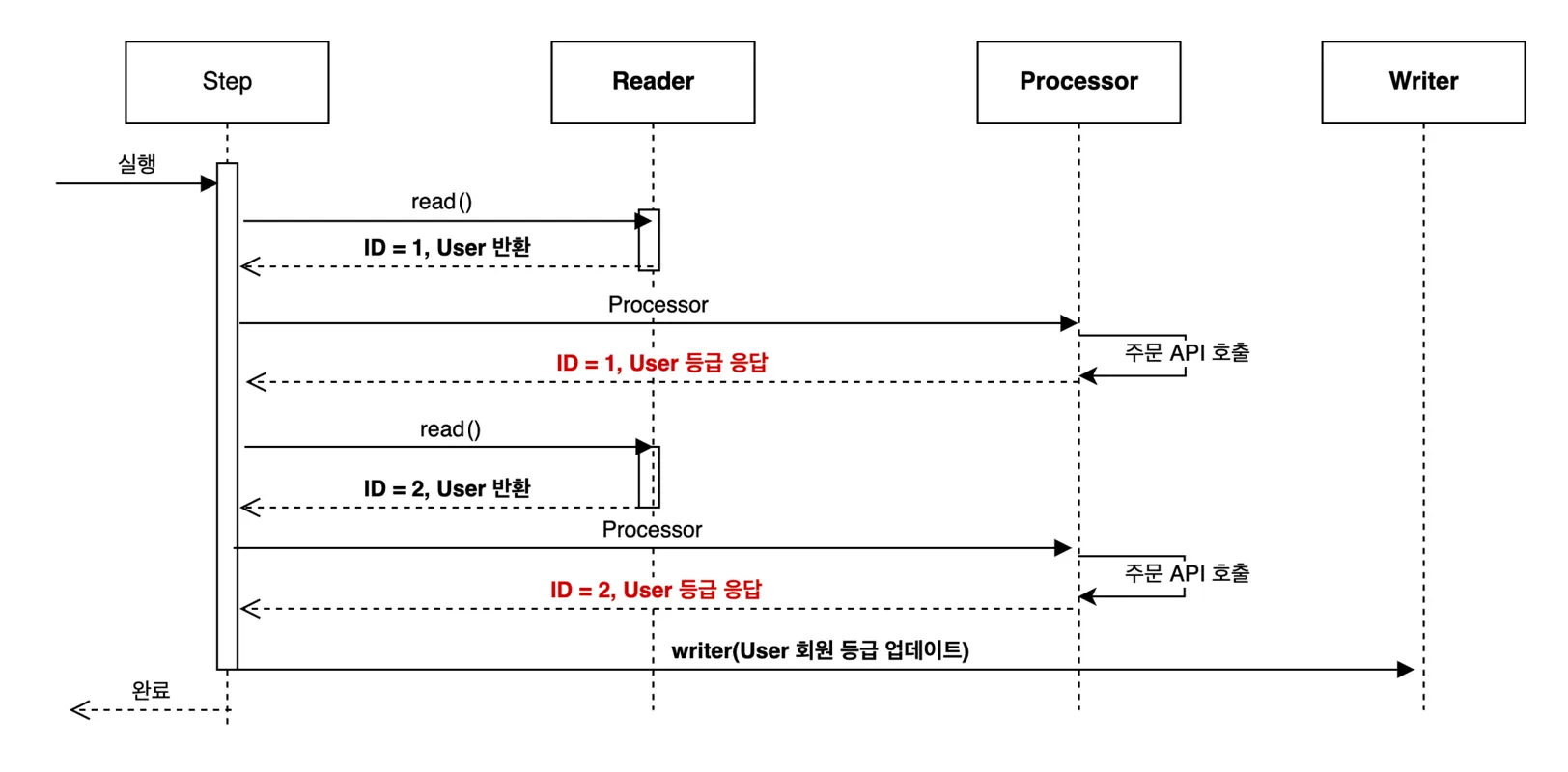
Batch Flow를 자세히 살펴보겠습니다.
- Reader는
read()메서드의 응답으로 유저를 1건씩 반환합니다. - Processor에서는 주문 API를 호출하여 한 유저의 등급을 받아옵니다.
- 이 작업(1~2)을 Chunk Size 만큼 반복한 후, Writer에서 회원 등급 업데이트를 수행합니다.
User Entity
@Entity
@Table(name = "user")
class User(
@Enumerated(EnumType.STRING)
@Column(name = "status", nullable = false)
var grade: GradeStatus
) {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
var id: Long? = null
}
enum class GradeStatus(description: String) {
BASIC("기본 등급"),
PREMIUM("프리미엄 등급"),
VIP("VIP 등급")
}User Entity 객체는 기본키와 유저 등급 필드를 가지는 간단한 엔티티로 구성되어 있습니다.
Processor
Processor 처리를 살펴보도록 하겠습니다.
private fun processor(): ItemProcessor<User, User> {
return ItemProcessor { user ->
// 유저 등급 조회 응답 속도 150ms 고정
user.status = orderClient.getGrade(user.id)
user
}
}Processor에서 유저 등급을 조회하기 위해 API 통신을 수행합니다. API의 응답 시간은 일관된 성능 측정을 위해 150ms로 고정했습니다. 이 응답 시간은 빠른 응답에 속합니다.
Writer
Writer 작업은 JpaItemWriter을 통해서 진행합니다.
private val writer: JpaItemWriter<User> =
JpaItemWriterBuilder<User>()
.entityManagerFactory(entityManagerFactory)
.build()JpaItemWriter를 사용하여 엔티티 상태의 변화를 감지하고, 변경된 내용을 자동으로 Database에 반영합니다.
성능 측정 결과
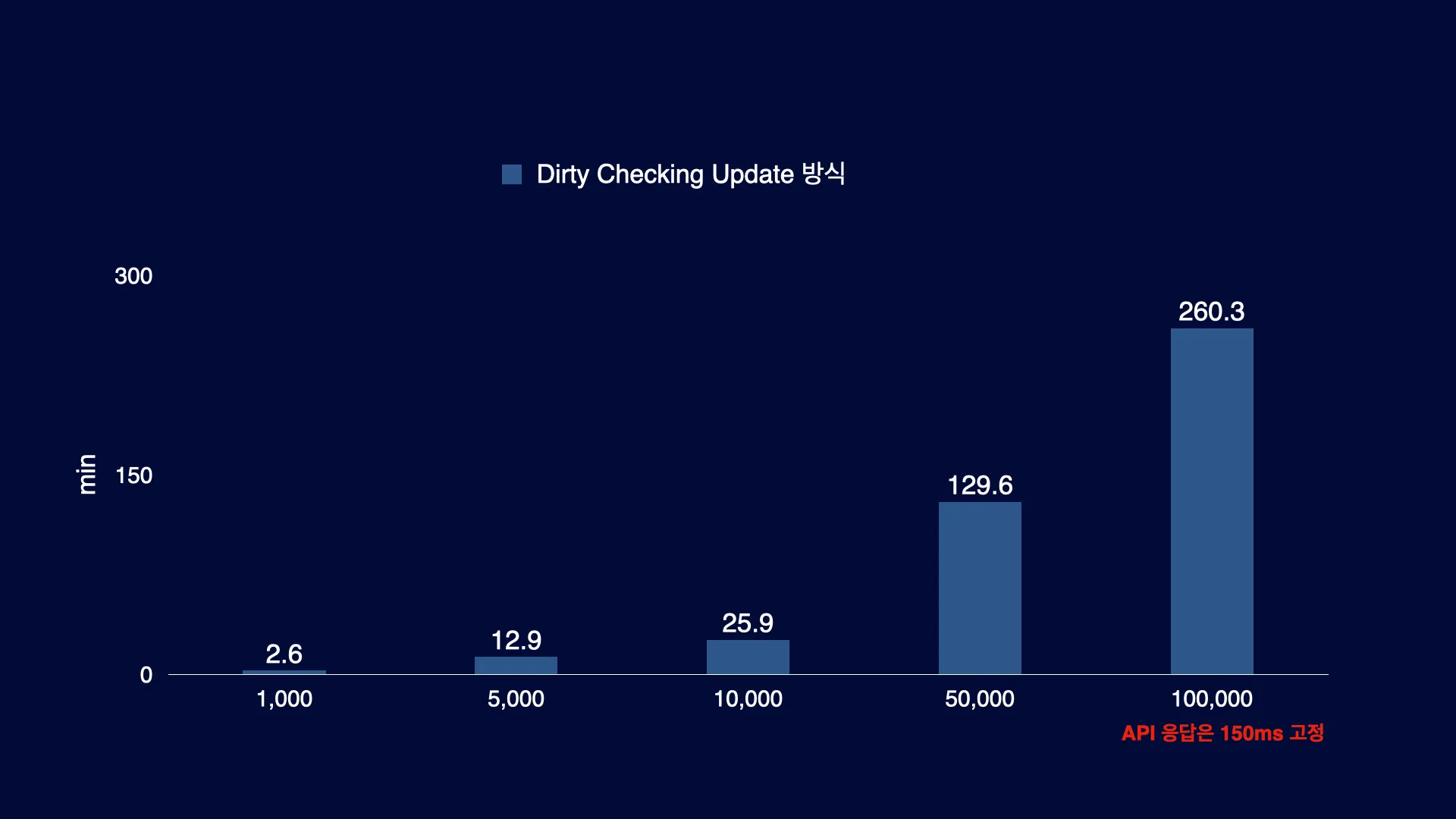
성능 측정 결과를 요약하면 다음과 같습니다. API 응답 속도가 150ms로 고정되어 있음에도 불구하고, 처리 대상 레코드가 5만 개 이상인 경우에는 처리 시간이 1시간을 넘어가고 있습니다. User의 수가 앞으로 더 증가할 것을 고려하여 성능 최적화를 진행해야 합니다.
성능 저하의 원인 및 개선 방법
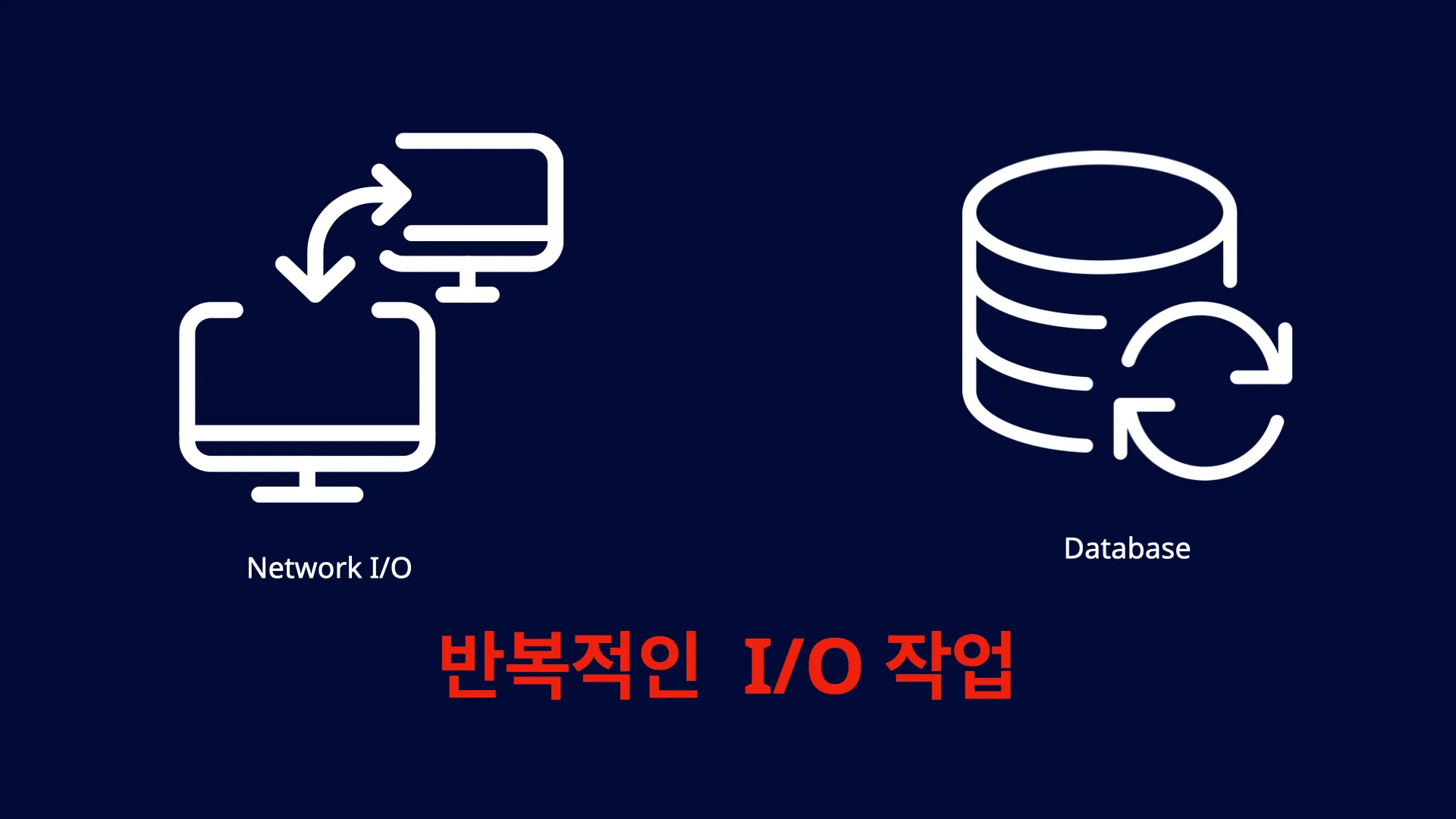
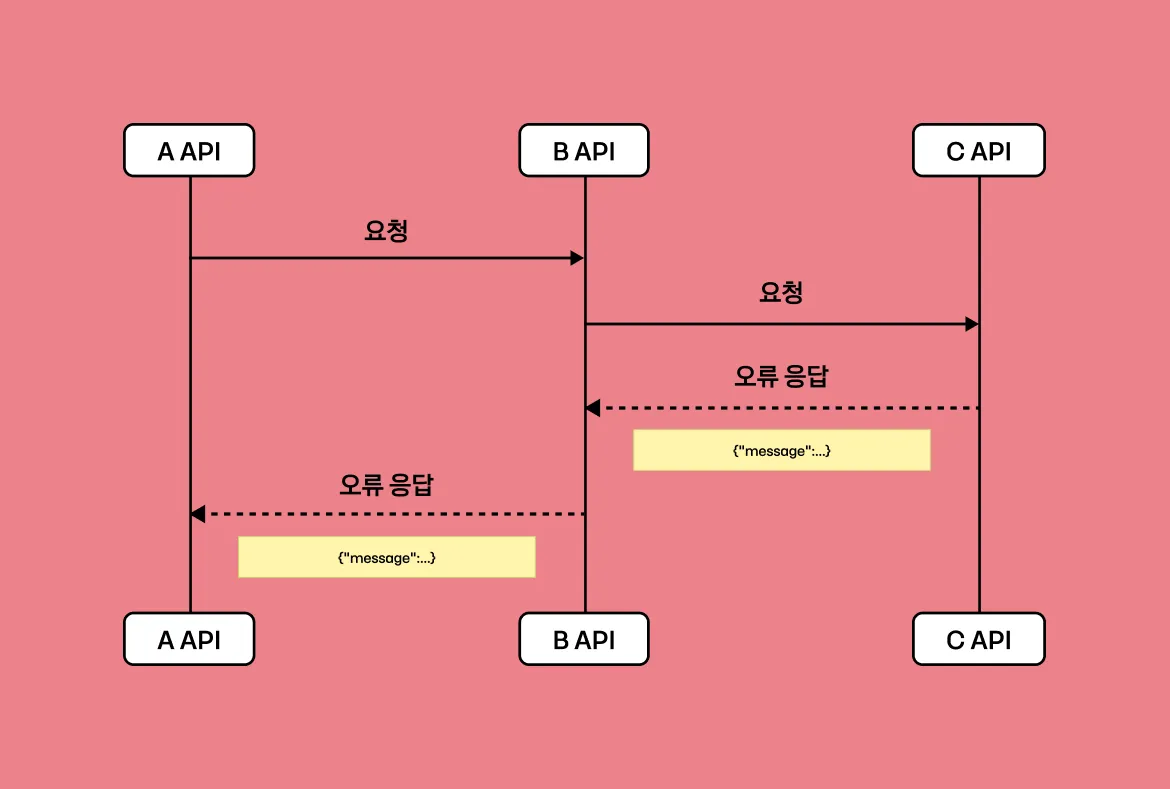
성능 저하의 첫 번째 원인은 Chunk Size 만큼 Network I/O가 발생하는 동안 대기 상태를 갖는 것입니다. 단일 요청이 150ms로 빠르게 느껴질 수 있지만, Chunk가 1,000이라면 150,000ms(2.5분) 동안 대기 상태로 머무르게 됩니다. 이로 인해 성능이 저하됩니다.
두 번째 성능 저하 원인은 Chunk Size 만큼 Database I/O 작업이 발생한다는 것입니다. 이러한 I/O 작업은 빠르게 처리되더라도 I/O 작업의 빈도가 높으면 성능이 저하됩니다. 구체적으로 어느 구간에서 문제가 발생하는지 Batch Flow를 통해서 살펴보겠습니다.
Processor에서 Network I/O 성능 저하
public interface ItemProcessor<I, O> {
// ItemProcessor에서는 Item 단건을 처리하게 디자인 됨
O process(@NonNull I item) throws Exception;
}Spring Batch의 ItemProcessor는 Item을 단건으로 처리하도록 디자인되어 있습니다. Processor에서 주문 API를 단건으로 조회하기 때문에 Chunk Size 만큼 HTTP 통신을 진행하게 되며, 이로 인해 응답 시간만큼의 대기 시간이 발생하여 성능 저하가 이뤄지고 있습니다.
Writer에서 Database I/O 성능 저하
JpaItemWriter의 Dirty Checking을 통해 업데이트를 진행하기 때문에 단건으로 처리됩니다. 따라서 1,000 개의 User의 변경이 감지되면 Database I/O도 동일하게 1,000 번 발생하게 됩니다.
또한 영속성 컨텍스트를 기반으로 Dirty Checking을 진행하기 때문에 I/O 횟수뿐만 아니라 엔티티의 변경을 감지하는 비용도 발생합니다. 대량 처리가 목적이라면 Projection을 통해서 영속성 컨텍스트를 사용하지 않는 것이 성능 향상에 좋습니다
성능 향상을 위한 I/O 횟수 최적화

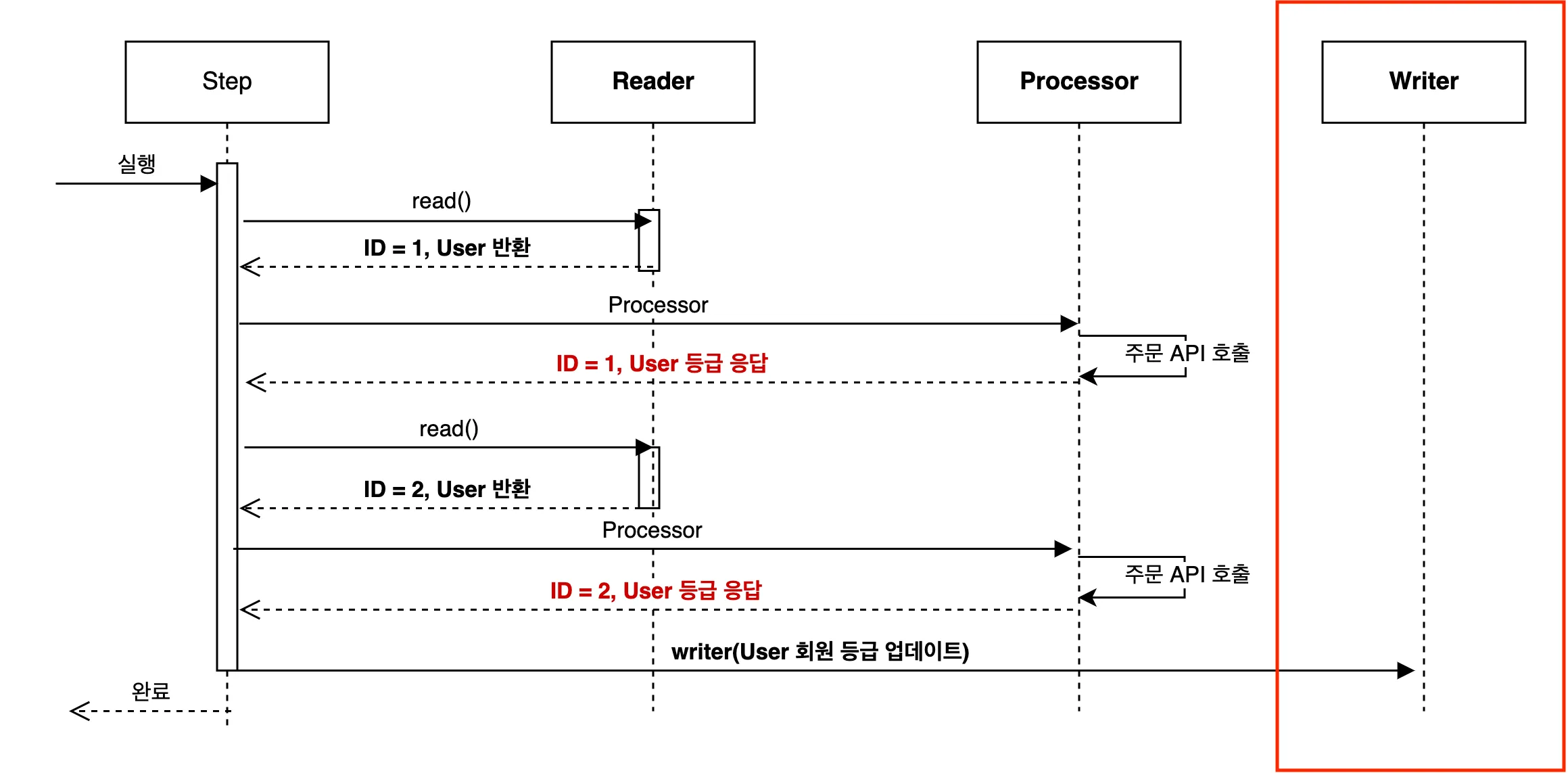
가장 큰 성능 저하 원인은 Chunk Size 만큼의 I/O 작업과 이에 따른 대기 시간 소비입니다. 이를 해결하기 위해 벌크 처리가 가능하도록, Processor를 제거하고 Writer에서 해당 작업을 진행할 수 있도록 개선해 보겠습니다.
private fun rxWriter(): ItemWriter<UserProjection> {
return ItemWriter { userProjections ->
userProjections
.toFlowable()
.parallel()
.runOn(Schedulers.io())
.map { user ->
// 주문 API 150ms 으로 응답 시간 고정
Pair(user, orderClient.getGrade(user.id))
}
.sequential()
.blockingSubscribe(
{ user: Pair<UserProjection, UserGrade> ->
user.first.grade = user.second.grade
},
{
log.error(it.message, it)
},
{
// grade 그룹화 하여 In Update을 활용하여 업데이트 진행
val gradeGroups = stores.groupBy { it.grade }
for (gradeGroup in gradeGroups) {
userQueryService.updateGrade(
ids = gradeGroup.value.map { it.id },
status = gradeGroup.key
)
}
}
)
}
}Processor를 제거했기 때문에 Writer에서 주문 API 통신을 진행합니다. 더불어 Dirty Checking을 기반으로 업데이트를 진행하지 않기 때문에 Projection을 통해서 User 객체를 넘겨받습니다. Writer에서는 Chunk Size 만큼 Item을 넘겨받을 수 있기 때문에 벌크 작업이 가능해졌습니다.
병렬 처리로 HTTP 통신 대기 시간 최소화
주문 API에서 대량 유저 조회로 변경하는 것이 가장 좋은 해결책입니다. 하지만 변경이 불가능하다고 가정하고, 대신 클라이언트 측면에서 병렬처리를 활용하여 최적화를 진행해 보겠습니다. 병렬 처리를 위해 RX Kotlin을 사용했으며, Reactor, Coroutine 등 다른 방법을 사용하는 것도 가능합니다.
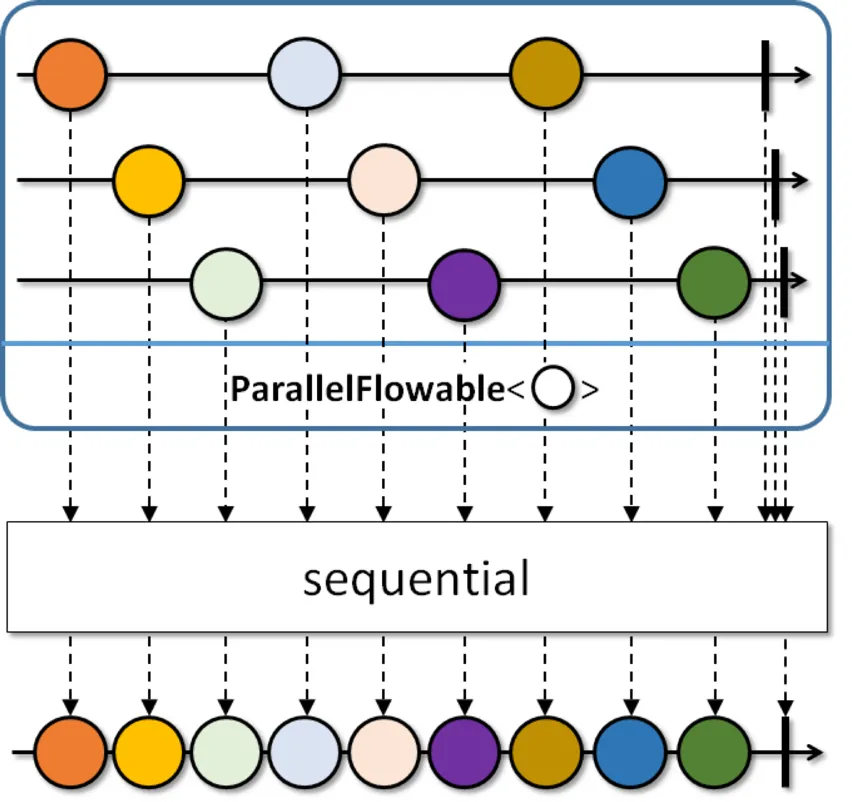
병렬 처리를 위해 데이터를 여러 개의 “레일”로 분할합니다. 이 경우, 레일의 수는 Schedulers.io()를 사용하여 시스템에 적합한 수로 선택합니다. 레일로 병렬로 주문 API를 호출하면 동일한 150ms 대기 시간 동안에 레일 수만큼 처리되므로 성능이 향상됩니다. 그런 다음, 병렬 처리된 데이터를 다시 sequential()으로 병합합니다. 병합된 데이터를 기반으로 업데이트를 수행합니다. 업데이트 최적화에 대해서도 자세히 살펴보겠습니다.
In Update를 통한 Database I/O 최소화
Chunk Size에 의해 Database I/O가 발생하므로 이 문제를 해결해야 합니다.
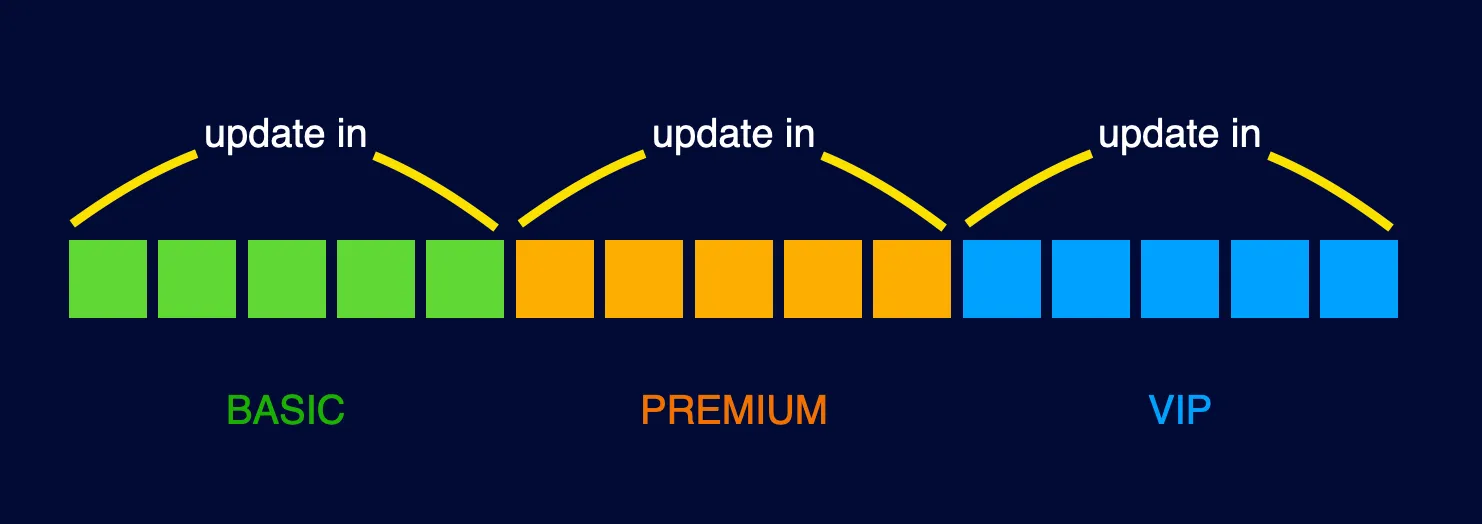
유저의 등급은 BASIC, PREMIUM, VIP으로 3개로 업데이트되며, 이를 그룹화하여 최적화할 수 있습니다.

BASIC, PREMIUM, VIP 3개의 그룹으로 나누어 각각에 해당하는 user id를 in 절로 적용하게 되면 Database I/O를 최소화할 수 있습니다. 업데이트 코드를 살펴보겠습니다.
class UserCustomRepositoryImpl :
UserCustomRepository,
QuerydslRepositorySupport(User::class.java) {
override fun updateGrade(ids: List<Long>, grade: GradeStatus) =
update(user)
.set(user.grade, grade)
.where(user.id.`in`(ids))
.execute()
}위에서 언급했듯 대량 처리 시 영속성 기반 엔티티 처리는 비용이 크기 때문에 Dirty Checking을 사용하지 않고 Querydsl을 기반으로 업데이트 작업을 수행합니다.
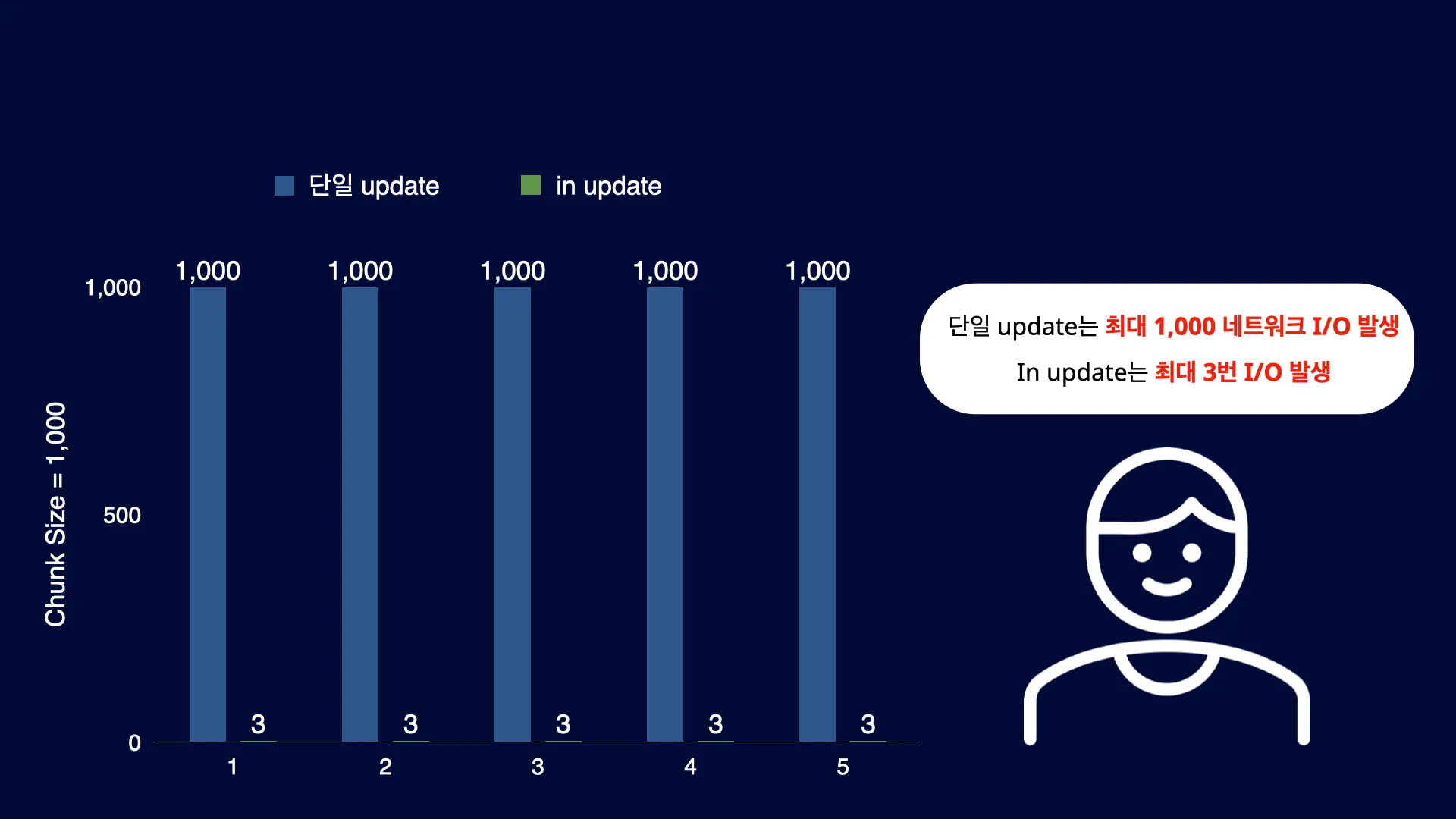
단일 Update 기준으로는 최대 1,000번의 Database I/O가 발생하는 반면, In Update에서는 최대 3번만 발생하므로 Database I/O를 크게 줄일 수 있습니다
성능 개선 측정
병렬 처리 및 In Update 성능 측정
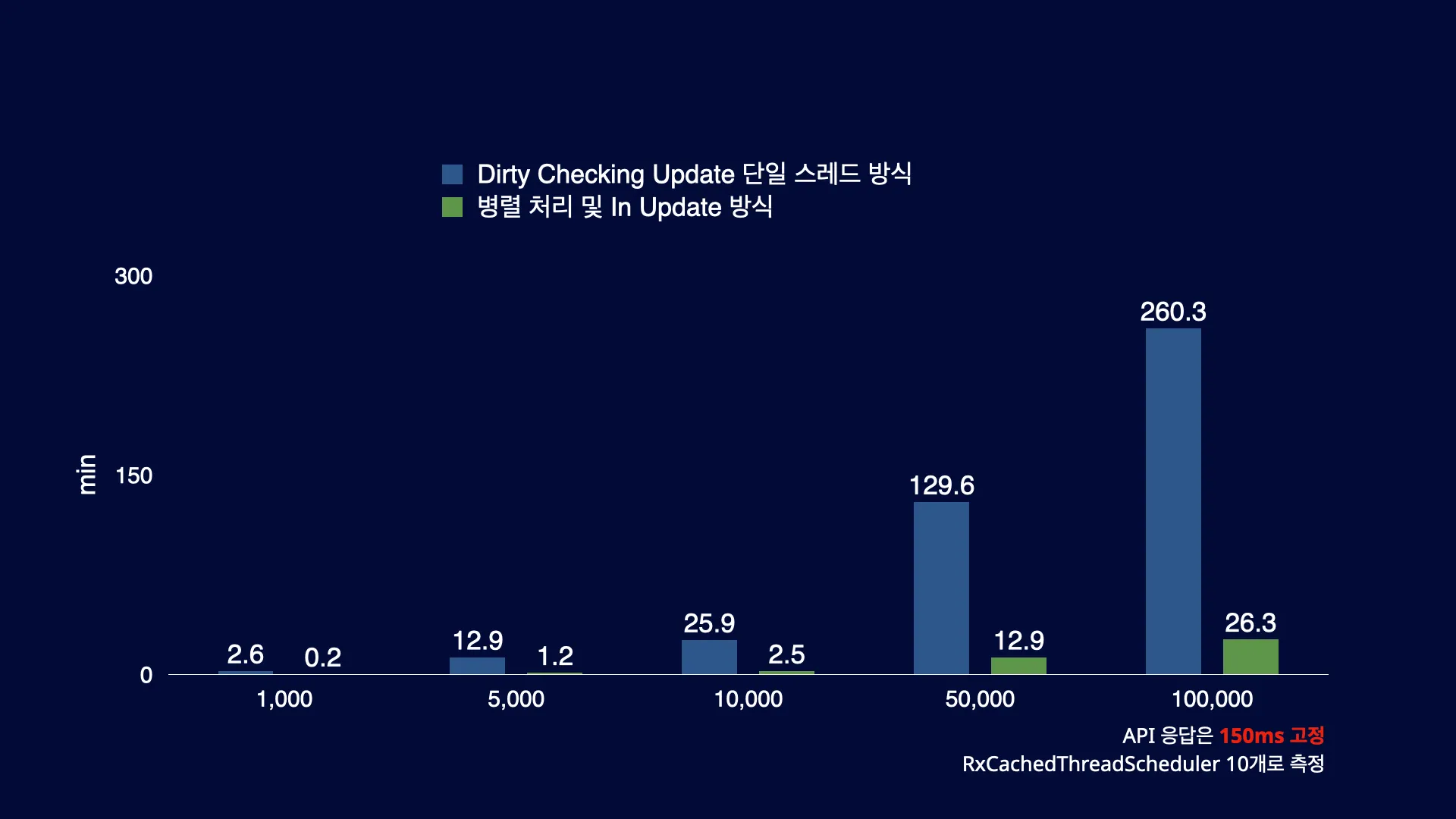
10개의 레일로 병렬처리하여 성능이 10배 가까이 향상되었습니다. Dirty Checking Update의 단일 스레드 방식에서는 1개의 레코드당 150ms를 기다려야 하지만, Rx Writer 방식에서는 10개의 레코드에서 동시에 150ms를 기다리므로 이러한 차이가 발생하게 됩니다. 물론 레일의 수를 무작정 늘리는 것만으로 성능이 비례적으로 향상되지 않습니다. 레일 수를 늘리면 스레드를 분할하고 다시 병합하는 과정에서 추가 리소스 소비와 Database Connection Pool 관리에 관한 고려가 필요합니다. 따라서 시스템에서 할당 가능한 적절한 스레드 수를 사용하는 방법, 예를 들어 Schedulers.io()와 같은 방법을 권장합니다.
In Update 성능 측정
In Update 성능 측정을 위해서 API 응답 대기 없이 Database 업데이트 속도 만을 측정했습니다. 균등한 속도 측정을 위해서 단일 Update는 모든 레코드가 BASIC에서 VIP으로 업데이트를 진행하도록 했고, In Update는 BASIC에서 VIP으로 업데이트하는 그룹과 BASIC에서 PREMIUM으로 업데이트하는 그룹으로만 성능 측정을 진행했습니다. 간단히 말해 Chunk 단위로 볼 때, 단일 Update는 전체 레코드의 수만큼 Database I/O가 진행되고, In Update는 레코드의 수와 상관없이 Database I/O가 2번 발생하는 것을 의미합니다.
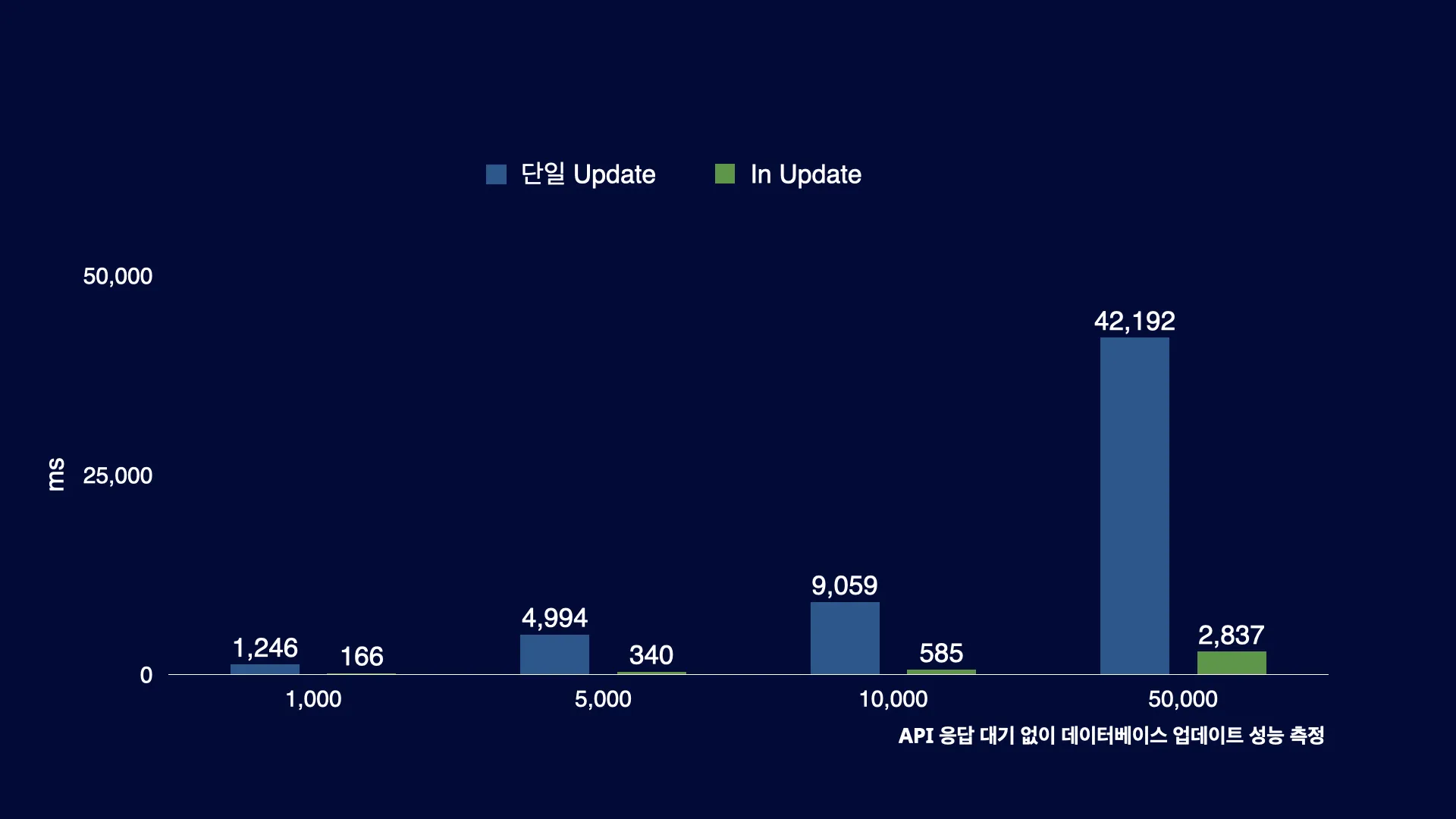
성능 측정 결과, Database 업데이트 작업에서는 5,000개 이상의 레코드부터는 성능이 이전 대비 90% 이상 향상되었습니다. 이러한 결과는 반복적인 I/O 작업을 한 번에 모아서 처리하는 것만으로도 큰 성능 향상을 이룰 수 있음을 보여줍니다.
유저 등급 및 등급 포인트 Batch

유저의 등급뿐만 아니라 등급 포인트도 함께 변경해야 하는 새로운 요구사항이 추가되었습니다. 이를 위해 주문 API는 등급 포인트 정보를 응답에 포함하여 반환합니다. 그러나 이 요구사항은 성능적인 이슈가 발생할 수 있습니다. 어떤 문제가 있는지 살펴보겠습니다.
등급 포인트 업데이트의 문제점

유저의 등급 포인트는 각각 다르기 때문에 in 절을 사용하여 업데이트할 수 없습니다. 이에 따라, 개별 ID를 기반으로 한 개별 업데이트 쿼리를 수행해야 합니다. 그러나 이 방식은 Chunk Size 만큼 Database I/O가 발생하므로 성능상의 문제가 발생할 수 있습니다. 결국, Chunk Size에 비례하여 I/O 작업이 증가하면 성능이 저하되는 문제를 해결하기 위해 Database I/O를 최소화해야 합니다.
등급 포인트 개선 방법
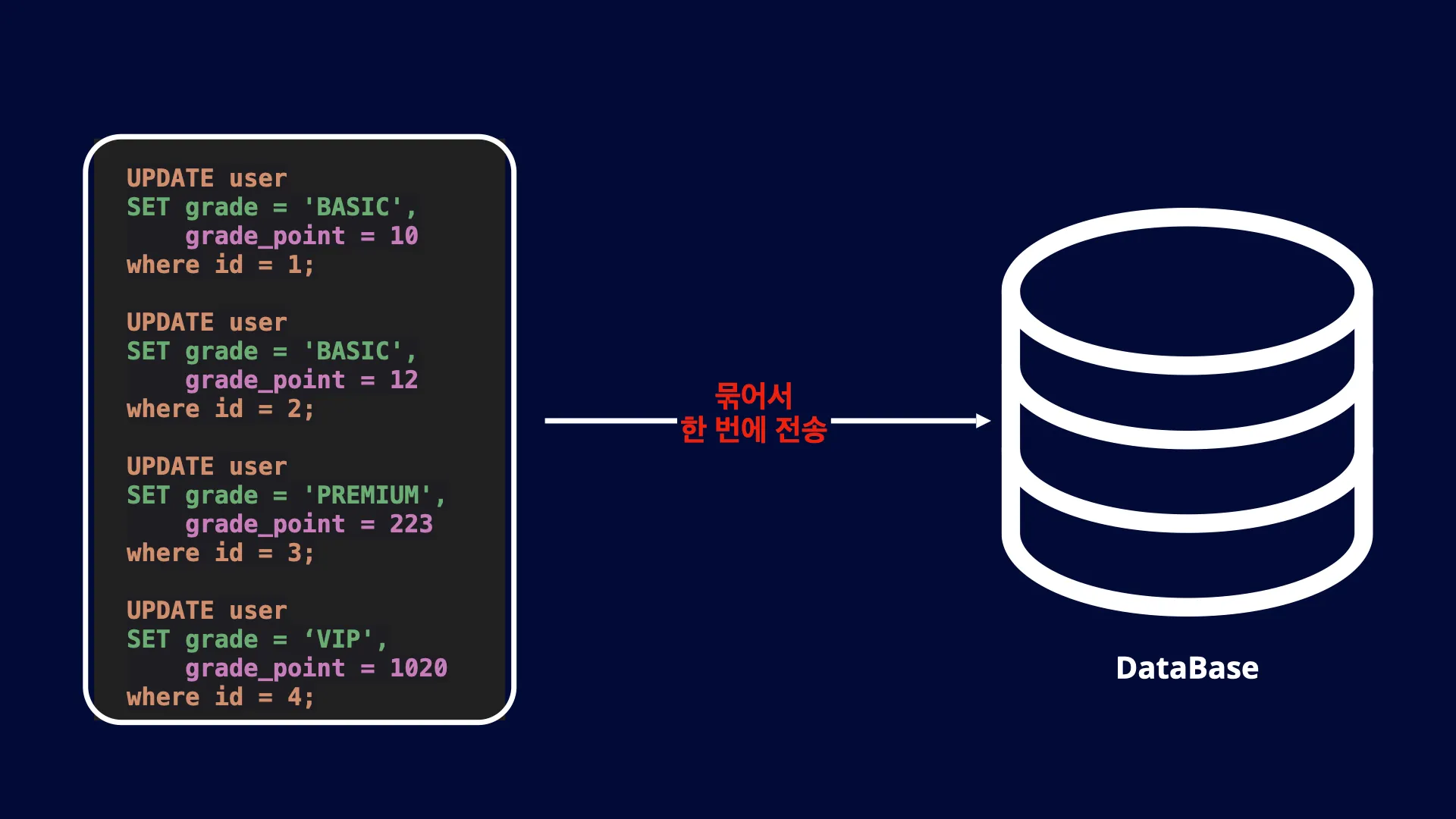
문제를 해결하는 다른 방법으로 JDBC Execute Batch를 활용할 수 있습니다. JDBC Execute Batch를 사용하면 여러 개의 쿼리를 한 번에 묶어서 Database로 전송할 수 있습니다. 이 방식을 활용하면 Database I/O 작업을 한 번으로 최소화할 수 있습니다. 이제 JDBC Execute Batch 코드를 자세히 살펴보겠습니다.
fun addBatch(users: List<UserProjection>) {
val connection = dataSource.connection
val statement = connection.prepareStatement(
"""
UPDATE user
SET grade = ?,
grade_point = ?
where id = ?
""".trimIndent()
)!!
try {
for (user in users) {
statement.setString(1, user.grade.name)
statement.setInt(2, user.gradePoint)
statement.setLong(3, user.id)
statement.addBatch()
}
statement.executeBatch()
} catch (e: Exception) {
throw e
} finally {
if (statement.isClosed.not()) {
statement.close()
}
if (connection.isClosed.not()) {
connection.close()
}
}
}먼저, 하나의 Database의 Connection을 가져옵니다. 그런 다음, prepareStatement를 사용하여 SQL 쿼리를 작성하고 이를 실행하기 위해 addBatch를 통해 누적된 레코드를 Chunk Size 만큼 모읍니다. 마지막으로, 누적된 레코드를 executeBatch를 통해 한 번에 Database에 전송합니다.
Exposed를 통한 안전하고 쉽게 JDBC Execute 처리
문자열 기반으로 SQL을 관리하고, 자원을 final로 해제하는 반복적인 코드 작성은 효율적이지 않아 Exposed를 도입하였습니다. Exposed는 JetBrains에서 Kotlin 기반으로 개발한 ORM 프레임워크로, JPA와 함께 사용하면서 대량 데이터 처리와 관련된 여러 문제를 해결하고 있습니다. 또한, JPA와 혼합해서 사용 가능하며 다양한 기능적인 장점을 제공합니다. Exposed를 통해서 Execute Batch 코드를 살펴보겠습니다.
object Users : LongIdTable("user") {
val grade = enumerationByName("status", 10, GradeStatus::class)
val gradePoint = integer("grade_point")
}
fun batchUpdate(users: List<UserProjection>) {
BatchUpdateStatement(Users).apply {
users.forEach {
addBatch(EntityID(it, Users))
this[Users.grade] = it.grade
this[Users.gradePoint] = it.gradePoint
}
}.execute(TransactionManager.current())
}BatchUpdateStatement를 사용하여 Execute Batch를 실행합니다. addBatch를 통해 Chunk Size 만큼 모아, 누적된 레코드를 execute를 통해 한 번에 Database에 전송합니다. Exposed의 BatchUpdateStatement 통해서 안전하고 쉽게 JDBC Execute 처리할 수 있습니다.
패킷을 한 번에 모아서 보낼 때 주의점
JDBC Execute는 패킷을 한 번에 모아서 전달하는 구조이기 때문에 문제가 발생할 수 있습니다. Database Connection을 오래 유지하기 때문에 Connection Timeout이 발생할 가능성이 높아지며 트랜잭션을 오래 유지하기 때문에 Database 성능에 지장을 주게 됩니다. 이런 문제를 해결하려면 작업을 Chunk 크기로 나누어 처리하는 것이 유용합니다.
이 작업은 코틀린의 chunked() 함수를 활용하면 간편하게 Chunk 처리할 수 있습니다.
fun batchUpdate(users: List<UserProjection>) {
BatchUpdateStatement(Users).apply {
users.chunked(1_000).forEach { userChunks ->
userChunks.forEach {
addBatch(EntityID(it, Users))
this[Users.grade] = it.grade
this[Users.gradePoint] = it.gradePoint
}
}
}.execute(TransactionManager.current())
}1,000개를 기준으로 Chunk 단위로 패킷을 전달하면 Database I/O는 늘어날 수 있지만, 한 번에 전송하는 패킷 크기가 작아져서 Connection을 빠르게 반환할 수 있습니다. 또한, 한 번에 전송 가능한 패킷 크기는 MySQL의 경우에는 max_allowed_packet과 같은 임계치 값을 고려해야 합니다. 따라서 이 설정값을 확인하고 적절한 Chunk 단위로 작업을 분할하여 처리하는 것이 효율적입니다.
Update 성능 측정
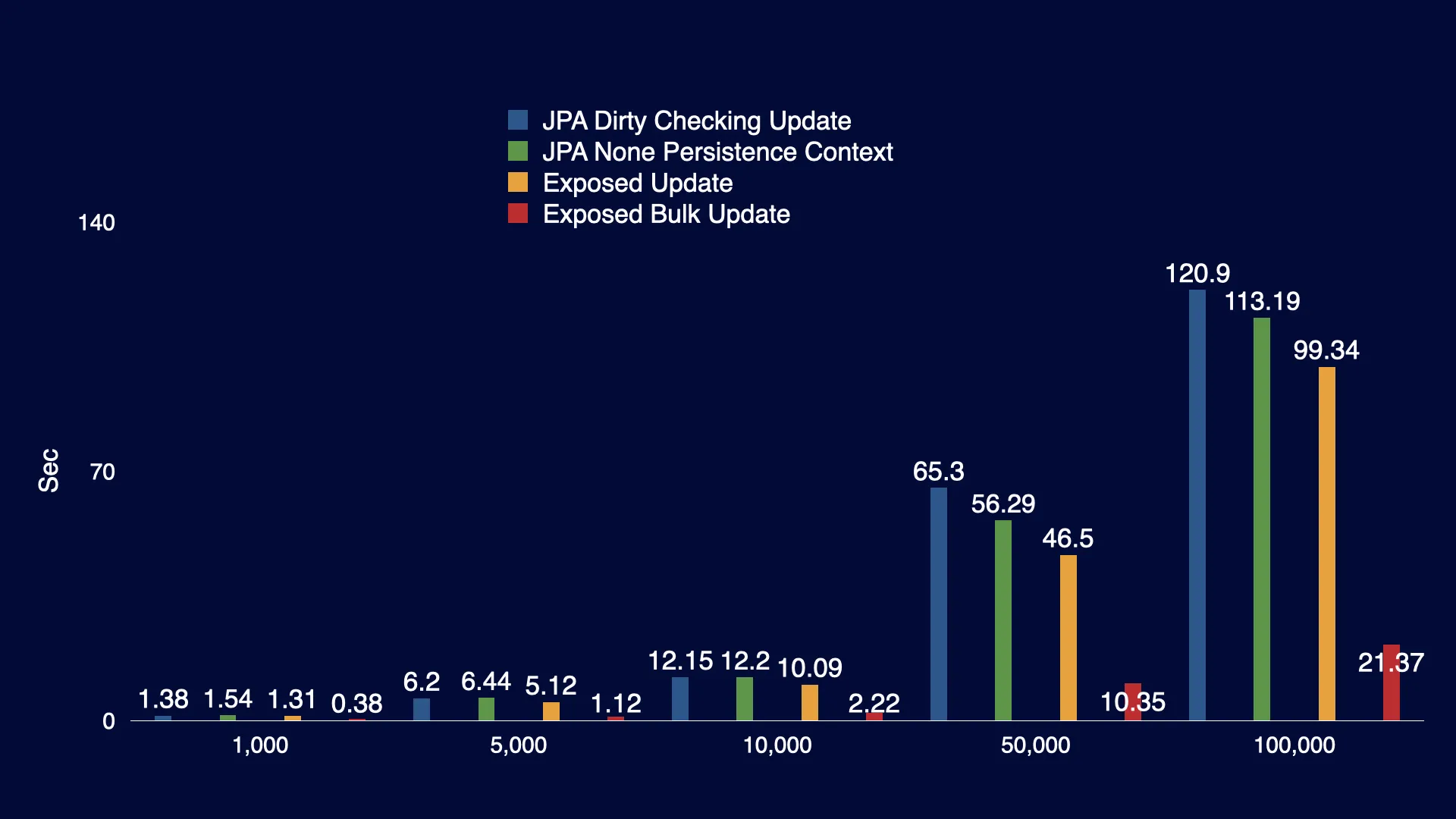
개선 방법들 간의 성능을 비교하기 위해, Exposed Batch Update 성능 외에도 JPA Dirty Checking Update, JPA None Persist Context, Exposed Update 성능을 측정했습니다. Exposed Batch Update의 성능이 압도적으로 뛰어나며, 단일 Update의 경우 JPA와 Exposed의 성능 차이가 크게 나타나지 않았습니다.
JPA Dirty Checking Update와 JPA None Persist Context의 성능 차이는 데이터 레코드 수가 5천 개 이상인 경우에 작게나마 나타납니다. 이는 영속성 컨텍스트의 기능이 많은 리소스를 사용하기 때문으로 보입니다. 또한, 성능 측정 결과에서는 필드가 총 3개밖에 없으며, 실제로 업데이트되는 필드도 2개뿐인 간단한 업데이트 작업이기 때문에 복잡한 Dirty Checking 및 다수의 필드 변경 감지가 있는 상황에서 더 큰 성능 차이가 나타날 것으로 예상됩니다. 대량 처리를 진행할 경우, 가능하면 Projection을 사용하는 것이 권장됩니다.
업데이트에 사용한 코드는 다음과 같습니다.
// JPA Dirty Checking Update
@Transactional
fun update(writers: List<Writer>) {
for (writer in writers) {
writer.name = "update"
}
}
// JPA None Persistence Context
@Transactional
fun update(ids: List<Long>) {
for (id in ids) {
update(qWriter)
.set(qWriter.name, "update")
.where(qWriter.id.eq(id))
.execute()
}
}
// Exposed Update
fun update(ids: List<Long>) {
transaction {
for (id in ids) {
Writers.update({ Writers.id eq id })
{
it[email] = "update"
}
}
}
}
// Exposed Batch Update
fun batchUpdate2(ids: List<Long>) {
transaction {
BatchUpdateStatement(Writers).apply {
ids.forEach {
addBatch(EntityID(it, Writers))
this[Writers.email] = "update"
}
}.execute(this)
}
}성능 개선 방법 정리
| 개선 이전 방법 | 개선 방법 |
|---|---|
| Processor 기반 단일 I/O 처리 시 | Processor 제거 이후 Writer에서 병렬 처리 |
| Dirty Checking 기반 단일 Update | 데이터 그룹화 및 In Update 활용으로 Database I/O 최소화 |
| In Update 불가능한 경우 | Execute Batch를 사용하여 여러 작업을 묶어서 Database I/O를 최소화 |
단일 I/O 처리 시 응답 속도가 빠르더라도 데이터 모수가 많을 경우 대기 시간이 오래 걸릴 수 있으므로 I/O 처리를 벌크 방식으로 수행하는 것이 효율적입니다. 또한, I/O 처리를 벌크로 수행하기 어려운 상황에서는 데이터를 병렬 처리하여 성능을 향상시킬 수 있습니다. 더불어 데이터를 그룹화하고 In Update를 사용하거나 Execute Batch를 통해 여러 작업을 묶어서 전송하는 방법도 I/O 횟수를 최소화하며 성능을 향상시키는 데 도움이 됩니다.
마치며
기존 구조에서는 반복적인 I/O 작업이 개별적으로 처리되고 있습니다. 이를 그룹화하여 처리하는 방식으로 구조를 변경하지 않고도 성능을 개선할 수 있습니다. 이런 성능 최적화는 Spring Batch 외에도 일반적으로 적용 가능하며, 구조를 변경하지 않고도 성능을 향상시킬 수 있는 점을 강조 드리고 싶습니다.
성능을 개선하기 위해서는 다른 측면에서 어떤 것들이 희생되는지 고려해야 합니다. 병렬처리를 사용하는 경우 테스트, 디버깅 및 트러블 슈팅과 같은 어려움이 발생할 수 있습니다. 따라서 이미 충분히 만족스러운 성능을 갖고 있을 경우 섣부른 최적화를 피하는 것을 권장합니다. 결국 모든 결정은 트레이드오프이며, 성능을 개선하기 위해서는 다른 측면에서 희생되는 부분이 반드시 발생하게 됩니다.























![[Project Loom] Virtual Thread에 봄(Spring)은 왔는가](/_astro/thumb.I22_MPmz_1XD63p.webp)

















![[if kakao 2022] Batch Performance를 고려한 최선의 Aggregation](/_astro/thumb.MGIp4JrG_2cerCK.webp)
![[if kakao 2022] Batch Performance를 고려한 최선의 Reader](/_astro/thumb.CZPDDx8q_221xKf.webp)