요약: 카카오페이의 마이데이터 플랫폼 개발팀은 사용자 금융 데이터의 증가하는 수집 이력을 관리하기 위해 기존 시스템을 재설계했습니다. 주요 문제는 높은 쿼리 처리 속도(QPS), 부족한 데이터 저장 용량, 그리고 통계 배치의 긴 수행 시간이었습니다. 이를 해결하기 위해 데이터 분산 저장, 파일 백업, 그리고 Palsonic을 이용한 효율적인 통계 계산 등의 방법을 도입했습니다. 이러한 개선을 통해 플랫폼의 성능과 처리 능력이 향상되었습니다.
💡 리뷰어 한줄평
david.guetta 대용량의 데이터를 다루는 곳에서 누구나 겪을법한 에피소드라 많은 도움이 될 것 같습니다. 🙂
daisy.dani 카카오페이 마이데이터 플랫폼이 대용량 데이터를 효과적으로 다루기 위해 기존 시스템을 어떻게 개선했는지 잘 정리된 글입니다. 재미있게 읽어주세요!
시작하며
안녕하세요. 카카오페이에서 마이데이터 플랫폼을 개발하고 있는 루피, 류크, 크루스입니다. 저희 팀은 자산관리 서비스를 포함하여 마이데이터를 필요로 하는 모든 서비스에 안정적으로 마이데이터를 제공하기 위한 플랫폼을 개발하기 위해 노력하고 있습니다. 2023년 카카오페이 자산관리 서비스는 급격히 성장했으며, 이에 따라 마이데이터 플랫폼은 기존보다 더 많은 데이터를 처리할 수 있는 아키텍처가 필요했습니다. 본 포스팅에서는 여러 개선 사항 중 “사용자의 금융 데이터 수집 이력 보관과 통계 제공”을 어떻게 개선했는지 공유하고자 합니다.
마이데이터 플랫폼의 대용량 데이터는 어디서 왔을까?
마이데이터 플랫폼은 사용자의 요구에 따라 여러 금융기관에 흩어진 금융 데이터를 마이데이터 표준에 따라 수집 및 관리하고있습니다. 또한, 마이데이터 사업자 및 제공자가 준수해야 할 의무를 수행하고 있습니다. 이러한 의무 중 “신용정보법 제20조”에 따라 “사용자의 금융 데이터 수집 이력”을 3년간 보관하고 있습니다.

자산관리 서비스가 성장함에 따라 “사용자의 금융 데이터 수집 이력” 데이터 규모가 마이데이터 플랫폼 초기 구축 당시 예측치보다 빠르게 증가하였습니다. 데이터 규모 증가로 인해 데이터 관리에 대한 아키텍처 재 설계가 필요하였습니다. 개선된 내용을 공유드리기에 앞서 우선 기존 시스템에서 어떤 문제가 있었는지를 살펴보겠습니다.
기존 시스템이 가진 문제는?
기존 아키텍처에서 크게 3가지 문제점을 식별했습니다. 높은 QPS, 데이터 보관 용량 부족, 그리고 마지막으로 통계 배치 수행 시간 증가입니다.
이슈 1. 높은 QPS
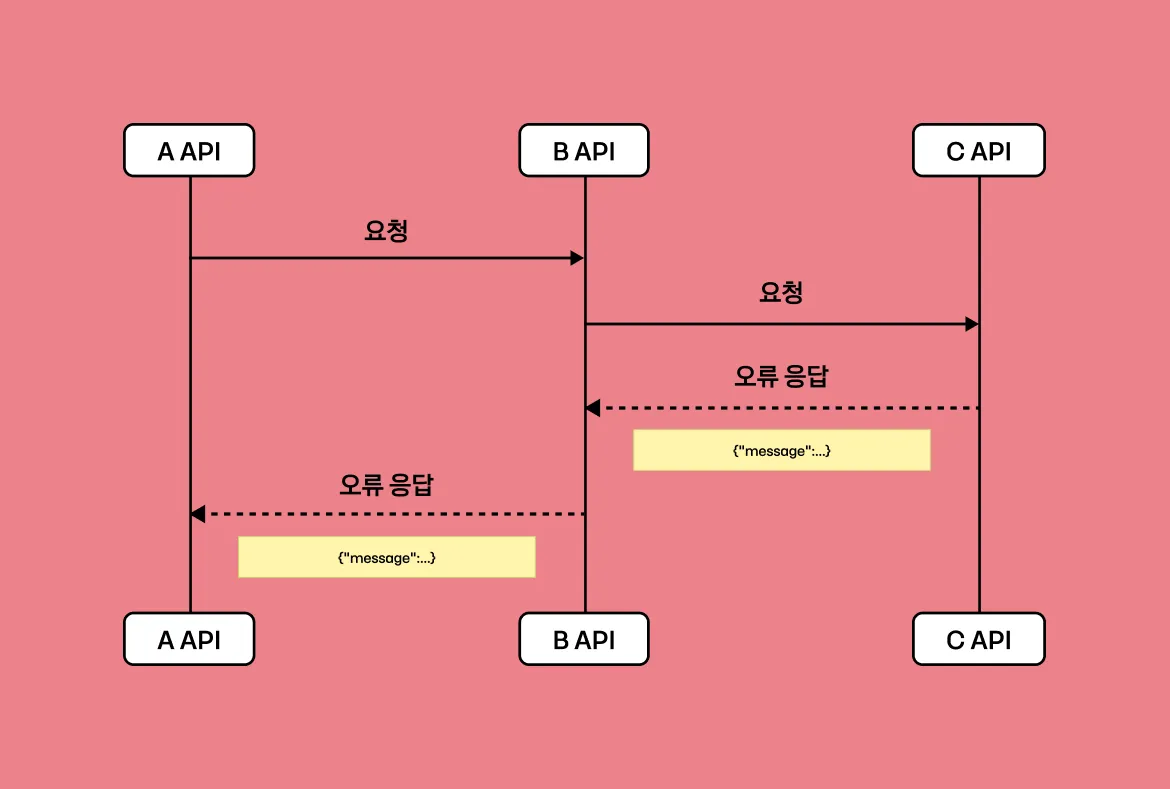
이력성 데이터와 금융 데이터를 같은 데이터소스에 관리하다 보니 해당 데이터소스에 대한 QPS (Queries per second)가 높은 것을 확인하였습니다.
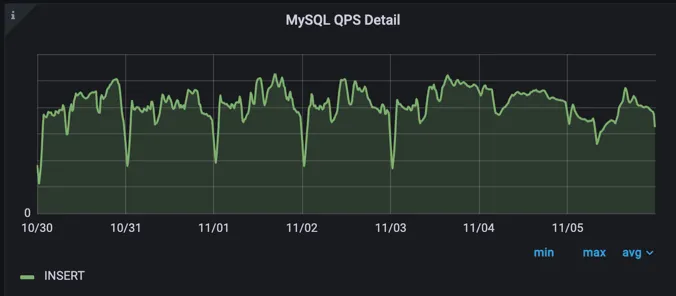
높은 QPS는 Master 데이터소스와 Slave 데이터소스에 대한 복제지연을 야기하였습니다. 복제지연은 Master 데이터소스에 대한 장애 상황에서 Slave 데이터소스로의 failover가 불가능하다는 점이 있어 빠른 해소가 필요했습니다.

이를 해소하기 위한 임시방편으로 카프카를 완충장치로 사용해 처리량을 조절하면서 QPS를 줄여보았는데요. 카프카 처리량을 줄임에 따라 카프카의 Lag 또한 지속적으로 증가하였습니다. 지속적인 사용자 증대로 인한 Produce 양이 Consume 양을 따라가지 못한 이유에서였습니다.

이슈 2. 데이터 보관 용량 부족
위에서 소개드린 것처럼 마이데이터 표준을 따르려면 “사용자의 금융 데이터 수집 이력”을 3년 보관해야 합니다. 시간이 지나면서 누적되는 데이터양이 크게 증가했습니다. 이에 따라 데이터소스 용량이 부족해질걸 예상했기에 사전에 용량 확보 방안을 마련해야 했습니다.
이슈 3. 통계 배치 수행 시간 증가
카카오페이는 마이데이터 사업자로서 마이데이터 API 사용에 대한 통계 데이터를 신용정보원 종합포털에 1주일 단위로 전송을 해야 하는 의무가 있습니다. 저희 플랫폼에서는 응답시간, 합계, 표준편차, 성공실패 횟수 등의 통계 데이터를 전송하기 위해 매일 통계 데이터를 저장하는 배치를 수행합니다.
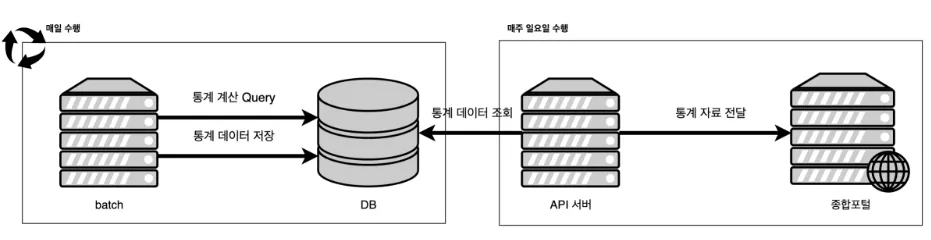
통계 데이터를 저장하는 배치에서는 통계 데이터인 평균, 합계, 표준편차를 구하기 위해 AVG, STDDEV, SUM 등의 쿼리 함수를 사용합니다.
SELECT
DATE_FORMAT(request_at, '%Y%m%d') AS 'stat_date',
org_code,
api_code,
AVG(duration) AS 'rsp_avg',
STDDEV(duration) AS 'rsp_std_dev',
SUM(duration) AS 'rsp_total',
GROUP BY DATE_FORMAT(request_at, '%Y%m%d'),
org_code,
api_code,마이데이터 가입자수 및 연결자수가 늘어나게 되면서 로그성 데이터의 테이블의 크기는 가파르게 상승하기 시작했고, 쿼리의 수행 속도는 점점 느려지고 있었습니다.
또한, 위에서 언급한 kafka Lag이 점점 쌓이면서 실제 API 요청 시간과 데이터의 created_at 시간이 다른 문제가 발생했습니다. 이전까지는 쿼리의 조회 기간을 통계 날짜의 00:00 ~ 23:59로 했습니다. 그런데 kafka Lag으로 인해 데이터가 늦게 저장되면서, 통계 날짜 00:00 ~ 통계 날짜 +1일 23:59까지 조회 기간을 늘리게 되었습니다. 이에 따라 많은 양의 데이터를 조회하는 상황이 되었습니다.
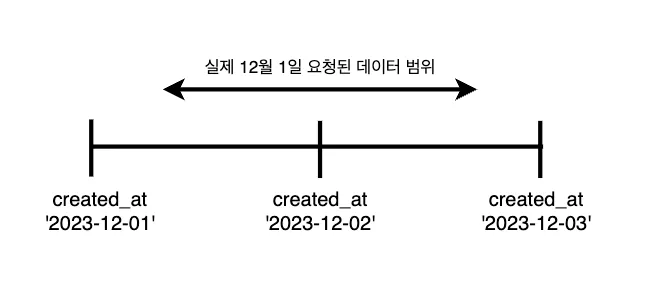
이렇게 많은 양의 데이터를 조회하여 계산하는 쿼리를 수행하다 보니 쿼리는 슬로우 쿼리로 수행되고, DB의 부하는 계속해서 증가했습니다. 또한, 데이터의 양이 계속해서 늘어나 개선을 하지 않으면 24시간이 넘게 수행되는 문제가 발생할 수밖에 없었습니다.
기존 시스템이 가진 문제 중 위와 같은 이슈들을 식별하였고, DB 부하 경감을 목표로 “사용자의 금융 데이터에 대한 수집 이력”에 대한 처리 및 관리 방식을 다시 설계하게 되었습니다. 먼저, 단일 DB에 대한 부하를 낮추기 위해 샤딩을 통해 히스토리 데이터를 여러 곳에 나눠서 적재하는 방안을 도입하였습니다. 다음으로 누적되는 데이터 양에 따른 DB 용량 부족 문제를 해결하고자 DB에 데이터를 보관하는 기간을 줄이고 이후에는 파일로 옮겨서 보관하도록 설계하였습니다. 마지막으로 RDB로 구성된 DB에서 직접 통계를 내지 않고 하둡 기반의 내부시스템인 Palsonic을 사용하여 통계를 내도록 변경하였습니다.
그럼 지금부터 각 이슈에 대해서 어떻게 개선하게 되었는지 설명드리겠습니다.
솔루션 1, 데이터 분산 저장하기
앞서 소개드린 “이슈 1. 높은 QPS”에 대한 해결책으로 데이터 분산 저장을 택하였습니다. 높은 데이터 유입량과 많은 데이터로 인한 부하를 분산하기 위해 1차적으로 데이터 유형에 따른 데이터소스를 분리하고, 2차적으로는 데이터소스에 대한 샤딩을 도입했습니다.
먼저, 데이터 유형에 따른 분리로 서비스에 활용되는 데이터와 이력성 데이터소스를 분리하였습니다. 기존 시스템에서 이력성 데이터의 유입이 INSERT 쿼리의 상당 부분을 차지하고 있었는데요. 이력성 데이터를 서비스성 데이터와 분리함에 따라 서비스 성 데이터에 대한 부하를 1차적으로 낮출 수 있었습니다.
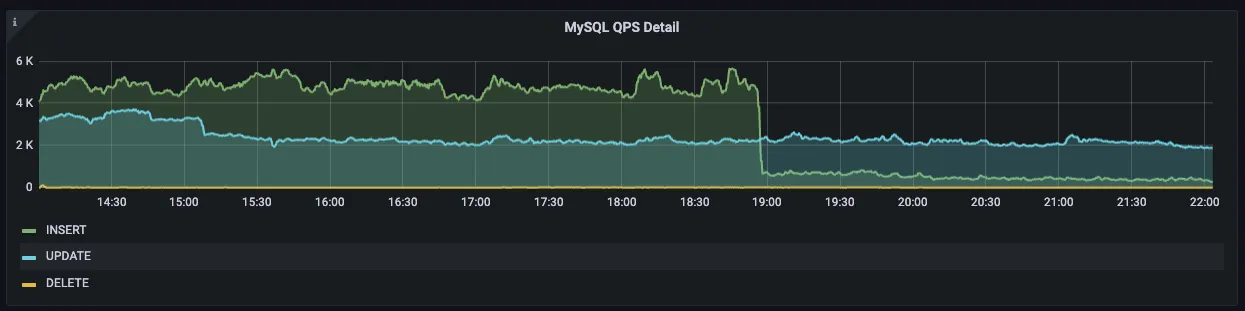
그다음으로 이력성 데이터에 대한 샤딩 적용입니다. 이력성 데이터의 경우에는 많은 유입뿐만 아니라 누적된 데이터로 인한 DB 용량 이슈도 있었는데요. 부하 분산 및 용량 분산을 위해 샤딩을 도입하였습니다.
여러 샤딩 방식 중 저희가 도입한 방식은 모듈러 샤딩입니다. 샤딩 방식은 크게 모듈러 샤딩과 레인지 샤딩으로 나뉘는데요. 각 방식에 대한 장/단점은 아래와 같습니다.
| 모듈러 샤딩 | 레인지 샤딩 | |
|---|---|---|
| 장점 | 레인지 샤딩에 비하여 균등 분배가 가능 | 구현 및 서버 증설이 용이 |
| 단점 | DB가 추가되는 경우 리밸런싱에 대한 비용 발생 | 일반적인 방식에서 부하 분산이 되지 않음 |
이번 개선에서 중점을 둔 포인트는 부하 분산이었고, 저희 서비스 환경을 고려하였을 때는 모듈러 샤딩이 적합하다고 판단하여 결정하게 되었습니다. 샤딩은 애플리케이션 레벨에서의 샤딩을 적용하였는데요. 적용한 방법은 다음과 같습니다.
(1) 라우팅 정책 만들기
먼저, 샤딩을 적용하기 위해 물리적으로 분산된 데이터소스에 대해 동적으로 타깃 데이터소스를 변경하기 위한 방법으로 JDK에서 기본으로 제공하는 AbstractRoutingDataSource를 사용하였습니다. AbstractRoutingDataSource에서 제공하는 determineTargetDataSource 함수를 사용하면 커넥션을 획득하는 시점에 어떤 데이터소스에 대한 커넥션을 반환할 것인지에 대해 정책을 세울 수 있습니다. 이를 활용하여 샤딩을 위한 정보를 담고 있는 콘텍스트를 만들고 해당 콘텍스트의 정보에 기반하여 정책에 맞는 데이터소스의 커넥션을 반환하도록 하였습니다.
class RoutingDataSourceForSharding : AbstractRoutingDataSource() {
// ... (생략)
override fun determineCurrentLookupKey(): Any? {
/**
* 콘텍스트 내 샤딩 번호를 사용하여 Datasource Lookup 하도록 처리
*/
return ShardingContextHolder.getContext()?.shardNo ?: defaultTargetDataSource
}
// ... (생략)
}이렇게 샤딩에 대한 정책을 세운 후에는 물리적으로 분산된 각 데이터소스를 위에서 정의한 데이터소스에 지정하였습니다. 이렇게 생성된 데이터소스를 LazyConnectionDataSourceProxy 타입의 DataSource 빈(Bean) 객체로 생성하여 데이터소스에 대한 반환을 커넥션 획득시점에 동적으로 가능하게 하였습니다.
@Bean(name = ["dataSourceForSharding"])
fun dataSourceForSharding(
@Qualifier("dataSources") dataSources: List<DataSource>
): DataSource {
// ... (생략)
shardedDataSource.setTargetDataSources(dataSources)
// ... (생략)
return LazyConnectionDataSourceProxy(shardedDataSource)
}(2) 사용하기
먼저, 샤딩 정책을 만드는 부분에서 샤딩을 위한 콘텍스트를 사용한다고 말씀드렸습니다. 그렇기 때문에 Repository 함수가 호출되기 전 해당 함수가 실행될 데이터소스에 대한 정보를 콘텍스트에 설정해주어야 합니다. 이를 위해 “Trailing Lambdas” 문법을 사용하여 Repository 실행 전/후에 Context를 설정하고 해지하도록 구현하였습니다.
// ... (생략)
fun <R : Any> sharding(
shardKey: Int,
shardCount: Int,
block: () -> R,
): R {
ShardingContextHolder.setContext(key.mod(shardCount))
val result = block.invoke()
ShardingContextHolder.clear()
return result
}
// ... (생략)이렇게 생성한 함수를 Repository 함수를 사용하는 부분에 적용하여 샤딩 처리가 되도록 구현하였습니다.
@Repository
class ProviderHistoryPersistenceAdapter(
private val sampleMessageRepository: SampleMessageRepository,
) {
// ... (생략)
fun save(sampleMessage: SampleMessageDto) = sharding(sampleMessageDto.key, SHARD_COUNT) {
sampleMessageRepository.save(toEntity(sampleMessageDto))
}
// ... (생략)
}간단하게 예제 코드를 사용해서 애플리케이션 레벨에서의 샤딩을 구현한 방식을 소개드렸는데요. 이렇게 샤딩에 대한 정책을 설정하고, 콘텍스트에 있는 정보를 바탕으로 데이터소스를 획득 시점에 결정될 수 있도록 함으로써 최종적으로 데이터 분산을 적용할 수 있었습니다.
솔루션 2, 파일로 백업하기
앞서 말씀드린 것처럼 관련법령 신용정보법에 의해 마이데이터 정보송수신 이력에 관한 데이터를 3년간 기록 보관해야 하는데요. 일반적인 DB의 용량 이슈로 대량으로 발생하는 이력성 데이터를 장기간 보관할 수 없는 문제를 해결하기 위해 별도 스토리지에 백업하는 방법을 도입하였습니다. 별도 스토리지는 세 종류 중 고민했습니다.
- MongoDB
- Elasticsearch
- File
| MongoDB | Elasticsearch | File | |
|---|---|---|---|
| 장점 | 수평적 확장이 용이하고, 관련 부서의 지원으로 비교적으로 구성과 구현이 간단할 것으로 예상 | 기존에 로그 데이터를 대용량으로 저장하는 사용 케이스가 있고, MongoDB와 마찬가지로 관련 부서의 지원을 받기 용이 | 스토리지를 구성하는데 비용이 합리적이고, 적재 대상 데이터의 특성에 적합 |
| 단점 | 라이선스 비용 발생 | 라이선스 비용 발생 | 운영 지원이 어려운 환경 |
MongoDB, Elasticsearch의 경우 사내 여러 사용 케이스가 있고, 관련 부서의 지원을 받기 용이하다는 장점이 있었습니다. File의 경우 사내에서 제공하는 파일 적재 서비스는 없었지만, 스토리지를 구성하는데 비용이 합리적이고, 적재 대상 데이터의 특성에 알맞다는 장점이 있었습니다. 기존 구성되어 있는 인프라와 구현 편의성을 고려하였을 때, MongoDB나 Elasticsearch를 사용하는 것이 사내 지원을 받는 데 유리하다는 큰 장점이 있었습니다. 하지만 단순히 이력성 데이터를 저장하기 위한 목적으로 사용하기에는 두 저장소 모두 적합하지 않았습니다. 여러 장점을 상쇄시킬 만큼의 큰 라이선스 비용이 발생하고, 데이터 특성상 당장 조회가 필요하지 않았기 때문입니다. 그래서 이력성 데이터는 파일로 저장하는 것이 가장 적합하다고 판단했습니다.
(1) 파일로 저장하기
정보송수신 이력 데이터의 경우 이미 메시지 브로커(카프카)와 RDB에 적재가 되고 있었기 때문에 기존에 존재하는 데이터 소스를 선택하여 파일로 저장하면 되는 상황이었습니다. RDB는 [솔루션 1, 데이터 분산 저장하기]에서 샤딩이 예정되어 있었습니다. 추가 확장 가능성을 고려하면 하나의 엔드 포인트에서 데이터를 가져오기 용이한 메시지 브로커가 적합하다고 판단하였습니다. 직접 메시지를 컨슘하는 서버 애플리케이션을 개발하는 방법도 고려해 봤습니다. 하지만 다양한 input/output 플러그인을 제공하여 데이터 파이프라인 구성에 적합한 오픈소스 로그스태시를 통해 파일로 저장하는 방법을 선택하였습니다.
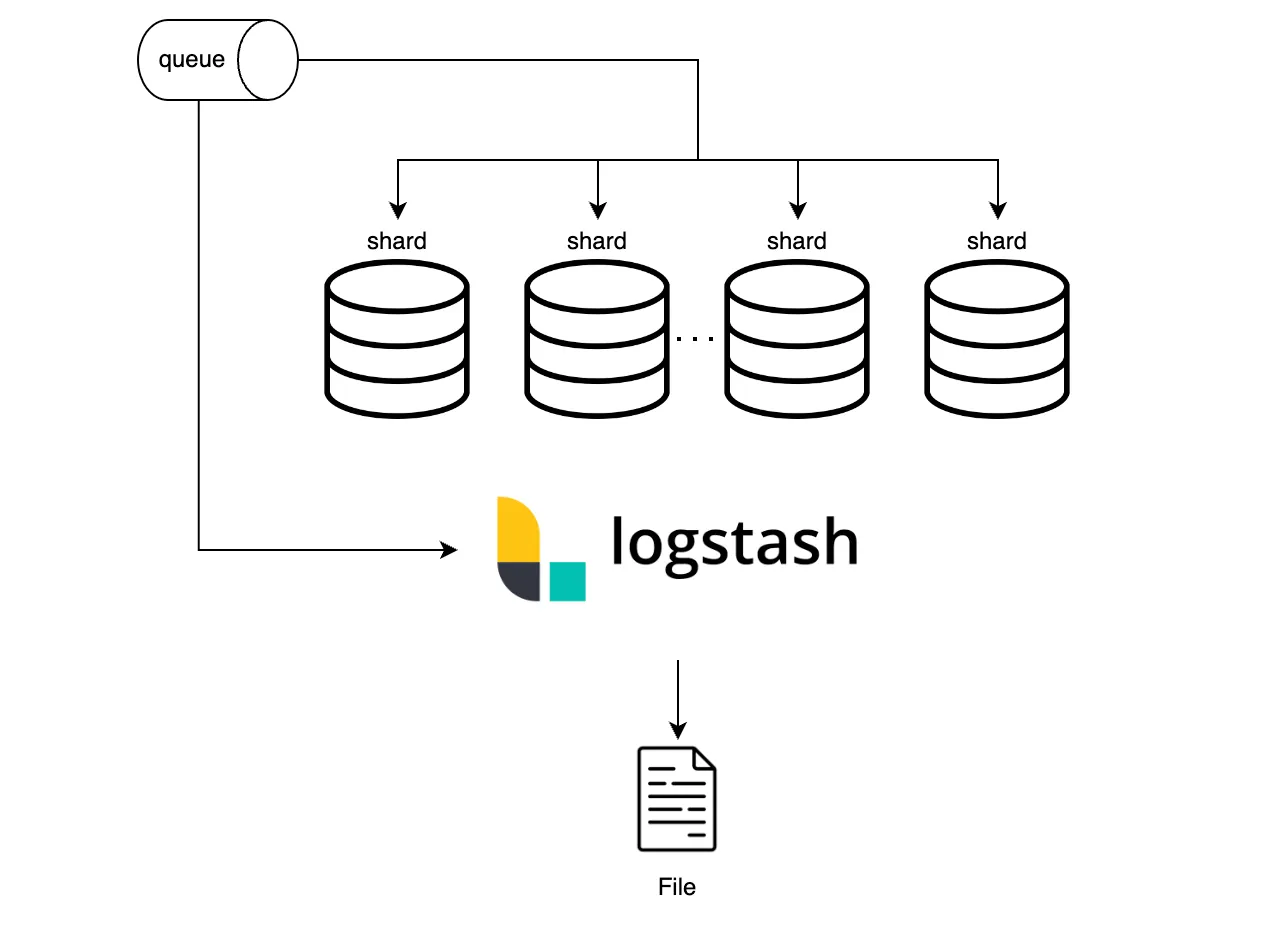
추가로 파일 스토리지에 보관하는 아키텍처로 구성하였지만, 추후 데이터 로드가 필요하게 될 가능성을 대비하여 하둡과 같은 플랫폼에 로드하기 용이한 파일 포맷과 구조로 저장하였습니다.
(2) 고가용성 확보
(1) 파일로 저장하기 에서 선택한 방법으로 단일 구성한 아키텍처에서는 고가용성을 확보하기 어렵습니다. 이를 해결하기 위해 위 아키텍처를 컨테이너 오케스트레이션이 가능한 쿠버네티스 클러스터에 컨테이너 환경으로 운영할 수 있도록 구성하여 고가용성을 확보하였습니다.
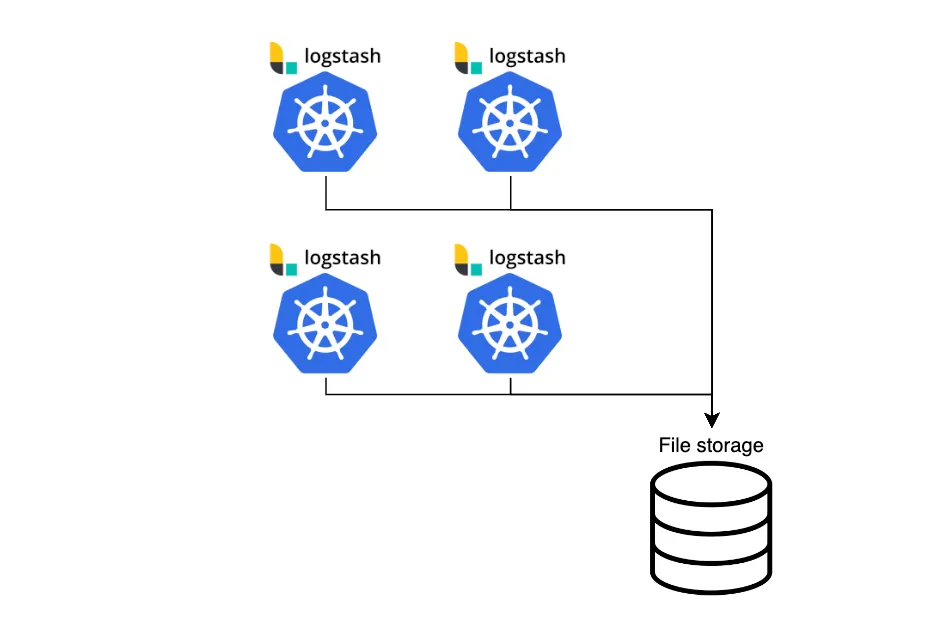
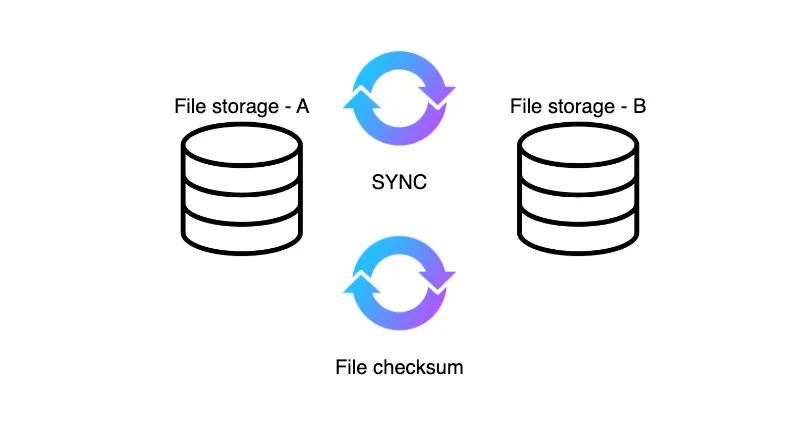
관련법령으로 관리되는 이력 데이터인 만큼 파일 자체의 소실 가능성 또한 고려하여 파일 스토리지에 대한 백업을 구성하였습니다. 저장된 파일은 물리적으로 분리된 별도 스토리지에 싱크 작업을 수행하고, 주기적으로 파일 체크섬을 검사하여 동일한 상태의 파일로 백업할 수 있도록 구성하였습니다.
솔루션 3, Palsonic으로 통계내기
먼저 통계 배치 수행 시간이 오래 걸리는 문제를 개선하기 위해 가장 문제가 되는 쿼리를 개선해보고자 했습니다. 통계 데이터 계산 쿼리의 가장 큰 문제는 많은 양의 데이터를 조회하여 연산하는 것이었습니다. 조회 데이터 양을 줄이기 위해 created_at이 아닌, requested_at을 사용하여 쿼리를 개선하려 했습니다. 그러나, 로그성 데이터 테이블은 created_at 기준으로 파티셔닝을 하고 있었기 때문에, created_at을 사용한 range scan이 그나마 최대의 성능을 낼 수 있는 방법이었습니다. created_at을 필수 조회 조건으로 하면서, 조회되는 데이터 양을 줄이기 위해 아래와 같은 방법을 고민했습니다.
- 정보제공기관자코드(org_code)를 순회하면서 배치를 수행하여 group by 제거
- created_at을 나눠서 조회
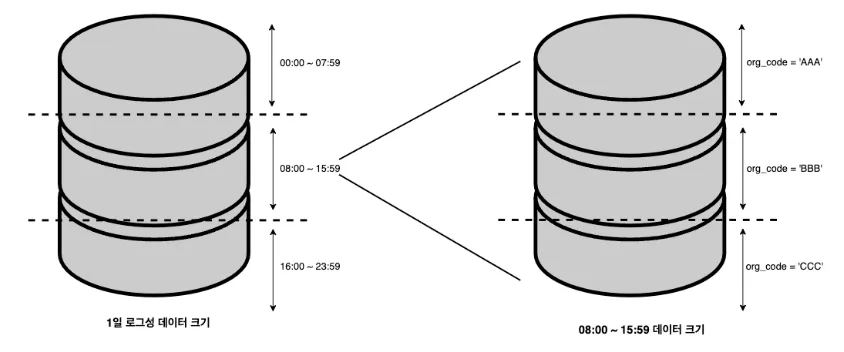
이러한 방법으로 쿼리를 개선하면 조회되는 데이터의 크기가 줄어, 배치의 성능도 향상될 것이라 예상했습니다. 하지만 문제는 표준편차였습니다. 표준편차는 전체 데이터를 메모리에 가져와 계산을 해야 하는데, created_at을 나눠서 계산을 하면 구할 수 없었습니다. 더욱이, 위의 솔루션인 데이터 분산 저장을 하게 되면서 쿼리를 통해 통계 데이터를 얻는데 어려워졌습니다.
- DB부하
- 쿼리의 속도
- 분산 저장된 데이터에 대한 통계 계산
위의 문제를 해결하기 위해, 분산 저장된 데이터에 대한 통계 계산을 수행하면서, 쿼리의 속도 향상과 DB 부하를 감소할 수 있는 솔루션 또는 서비스를 찾던 중 데이터팀에서 개발한 Palsonic을 추천받았습니다.
Palsonic이란?
카카오페이 데이터팀에서 만든 서비스로 여러 데이터소스에 연결하여 쿼리를 요청하고 하나의 뷰 형태로 결과를 볼 수 있는 쿼리 서비스입니다. Hive, Kudu, Mysql, Mongo, Redis, Kafka, ElasticSearch 등 다양한 저장소를 연결을 제공합니다. 서로 다른 스토리지의 데이터 SQL join이 가능하며, JDBC 인터페이스를 제공합니다. trino 엔진을 사용하여 분산(병렬) 쿼리를 사용해 방대한 데이터를 효율적으로 처리할 수 있습니다.
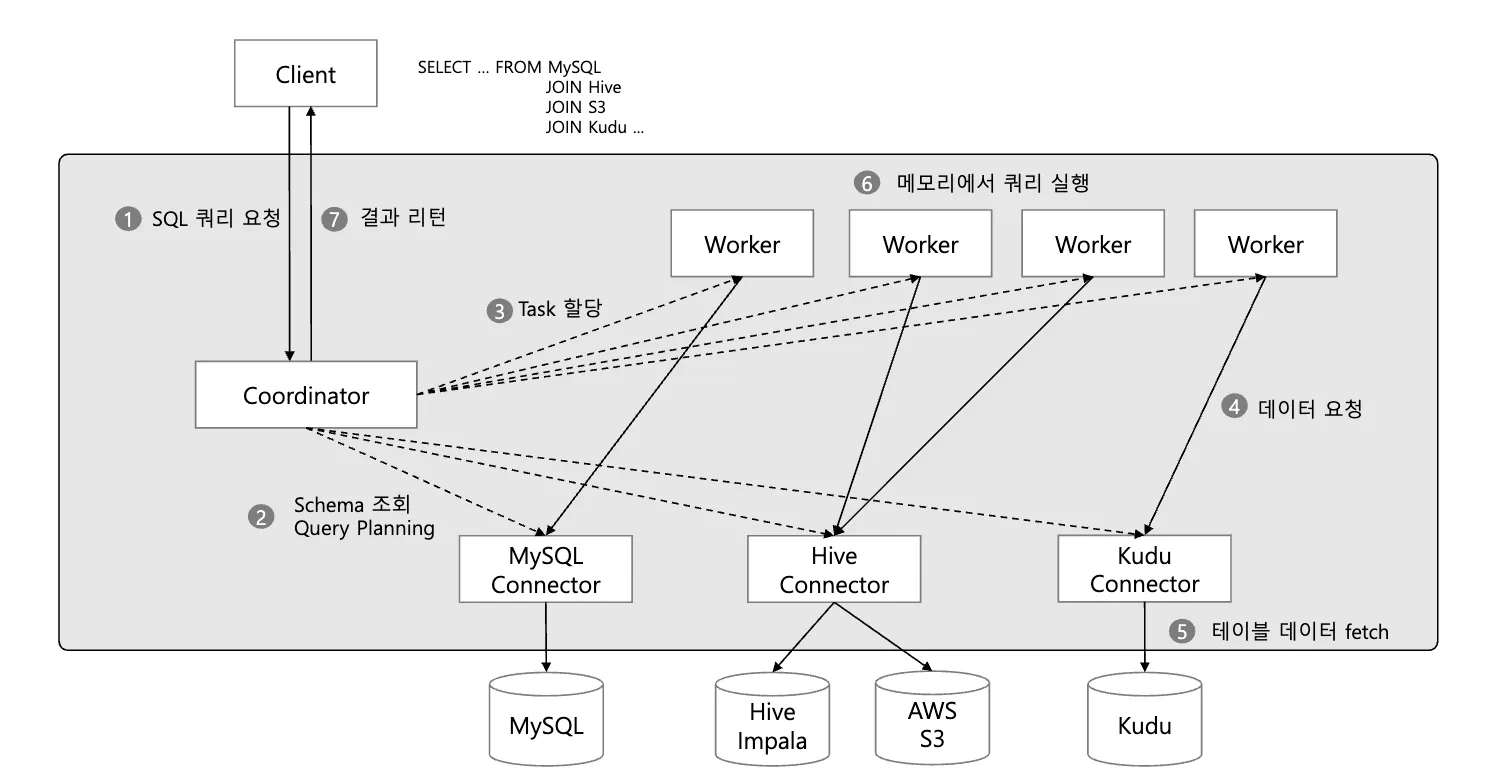
Palsonic은 분산된 데이터에 대한 통계계산 쿼리를 수행할 수 있어, 위에 언급한 저희가 겪고 있는 문제를 해결할 수 있다고 생각했습니다. 또한 Spring Batch에서 JDBC Driver를 사용한 데이터 소스의 연결 대신 Palsonic 연결로 변경하면 되어, 기존의 코드를 수정하는 것이 거의 없었습니다. 그러나 기존 쿼리가 너무 무거웠고, 이를 DB를 연결하여 수행하다 보니, 쿼리 속도와 DB 부하를 드라마틱하게 개선하기는 어려웠습니다.
1차 개선 속도 지표
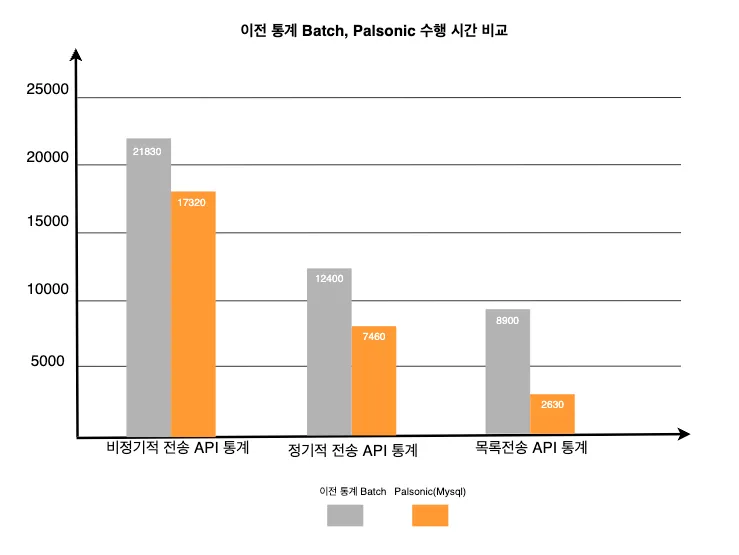
다음으로, Palsonic에서 Hadoop에 연결하여 통계 데이터를 구하는 방법을 선택했습니다. Hadoop 사용은 DB를 연결하지 않아 DB부하를 없앨 수 있었고, 쿼리 속도를 크게 줄일 수 있었습니다. 또한, Hadoop에서는 Mydata의 데이터를 매일 ETL (Extract, Transform, Load)하고 있어, 분산 저장된 데이터에 대한 계산도 문제가 되지 않았습니다. Spring Batch 코드도 Palsonic에서의 Hadoop 테이블명만 바꿔주면 되었기 때문에 수정할 필요가 거의 없었습니다.
2차 개선 속도 지표
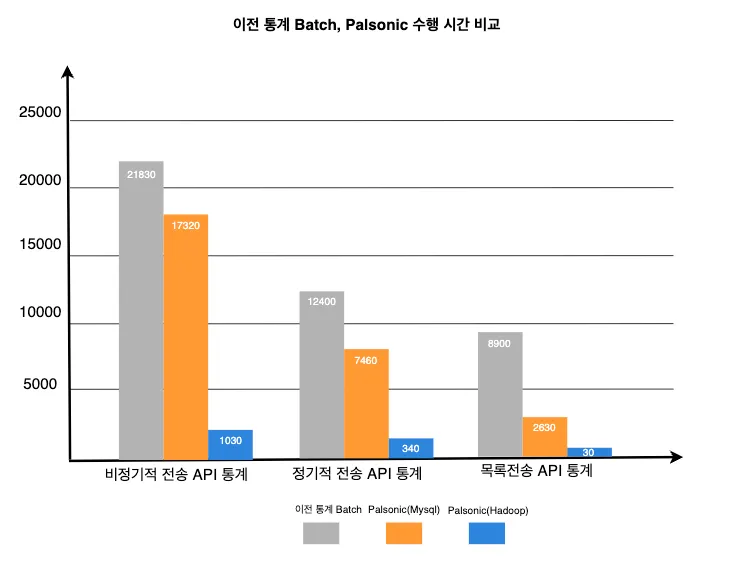
도입 결과, 위와 같은 드라마틱한 속도개선을 할 수 있었고, DB부하도 없앨 수 있었습니다.
마치며
ryuke.e
배치 개선 과정을 글에 다 적지는 못했지만, 쿼리 분석 및 배치 성능 개선을 시도하며 많은 경험을 할 수 있었습니다. 또한 기존 서비스가 아닌 다른 서비스를 사용하며 새로운 경험을 할 수 있었고, 문제를 해결할 때 레거시 내부에서만 해결해야 한다는 생각에서 벗어날 수 있었습니다.
luffy.dmonkey
데이터 보관 이슈를 처리하면서 기술적인 부분 이외에도 금융 관련 도메인 특성상 법적 요건 충족을 위한 여러 제약이 있는 상황에서 현재 선택 가능한 방법을 고민하고, 그중에서도 가장 적합한 방법을 선택하는 것이 중요하다는 것을 배울 수 있는 기회였습니다.
kroos.k
이번 개선 작업을 통해 기존 시스템 문제를 바탕으로 해결책들을 나열하고 장/단점을 비교하면서 현 상황에 적합한 방안을 도입하기 위해 고민하고 적용까지 해 볼 수 있는 기회였던 것 같습니다. 문제에 대한 접근 방식과 의사 결정 과정을 경험해 볼 수 있어 좋은 기회였다고 생각합니다.

























![[Project Loom] Virtual Thread에 봄(Spring)은 왔는가](/_astro/thumb.I22_MPmz_1XD63p.webp)

















![[if kakao 2022] Batch Performance를 고려한 최선의 Aggregation](/_astro/thumb.MGIp4JrG_2cerCK.webp)
![[if kakao 2022] Batch Performance를 고려한 최선의 Reader](/_astro/thumb.CZPDDx8q_221xKf.webp)