![[if kakao 2022] 사례로 보는 모바일 자동화 테스트를 통한 모니터링](/_astro/thumb.Dvo2o5eU_95dIV.webp)
시작하며
🔗 if(kakao) 발표 영상 보러 가기: QA엔지니어가 바라본 모바일 자동화 테스트
안녕하세요, 카카오페이 QA팀에서 자동화 테스트 관련 업무를 하고 있는 엘리입니다. 본 포스팅에서는 저희가 운영하는 모바일 자동화 테스트 환경을 어떻게 구성했는지 알아보고, 해당 환경에서 자동화 테스트 프로세스를 살펴보면서, 특히 테스트 모니터링 프로세스를 어떻게 진행하는지에 대해 실제 사례와 함께 얘기해 보려고 합니다.
해당 내용은 (kakao)dev2022 기술세션에서도 확인할 수 있습니다.
해당 세션에서 못다한 이야기를 추가하여 조금 더 상세하게 살펴보겠습니다 :)
💻카카오페이의 모바일 자동화 테스트 환경
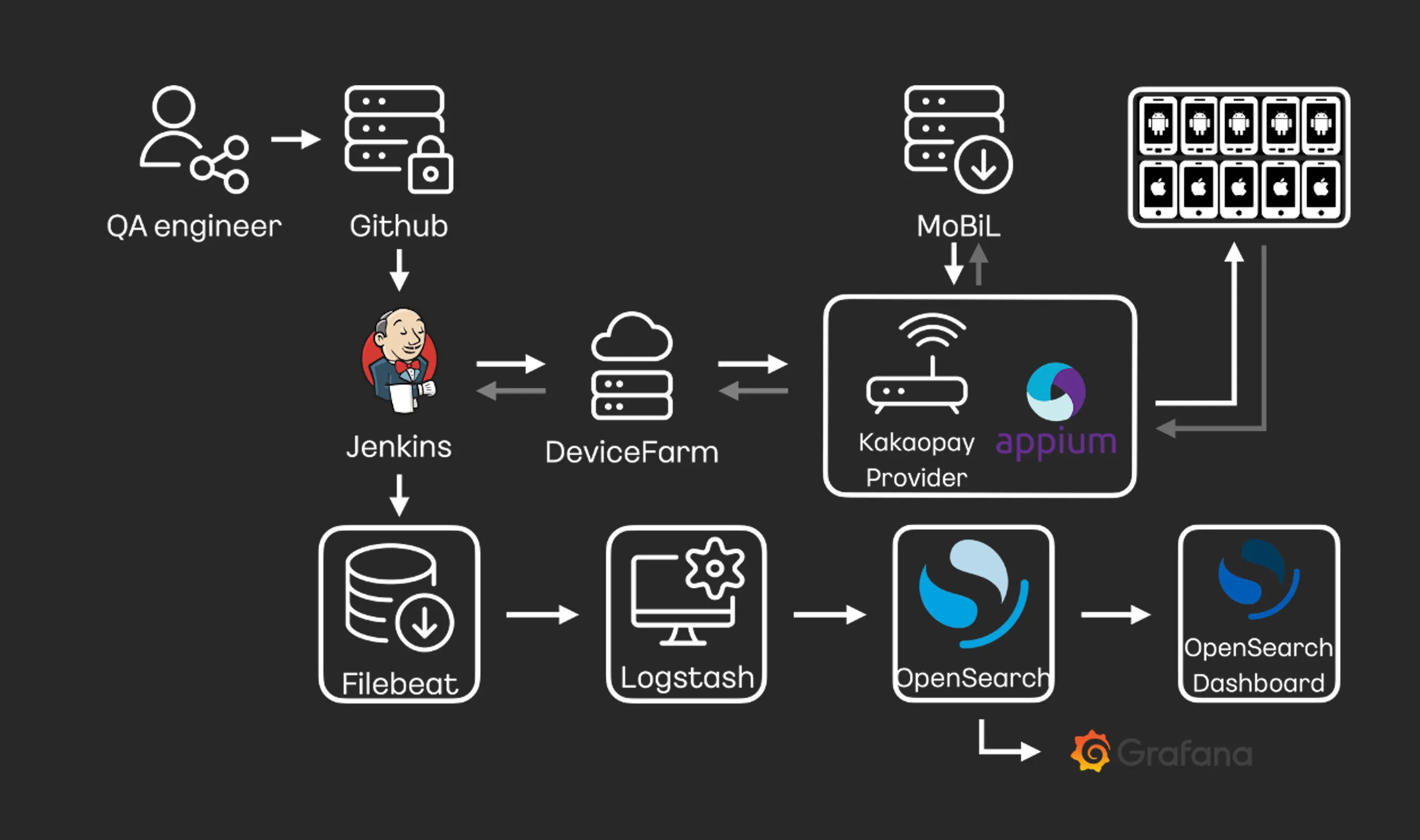
전반적인 자동화 테스트 환경을 살펴보면 아래와 같습니다.
- QA Engineer가 자동화 테스트 코드 작성과 로컬 테스트를 완료하고,
- Pull Request를 통한 코드 리뷰 진행 후 코드를 머지합니다.
- 이후 Trigger 또는 스케줄링에 따라 Jenkins에서 자동화 테스트가 실행되고
- Device Farm으로 원격에서 모니터링할 수 있게 됩니다.
- 실제 단말들은 Device Farm Provider에 연결되어 있으며,
- Appium을 통해 자동화 테스트를 수행합니다.
- 또한 테스트에 사용되는 앱은 테스트가 진행됨에 따라 artifact를 통해 MoBiL로 부터 최신 빌드된 앱을 자동으로 받아와서 설치됩니다.
- 실행에 따른 상세 로그들이 수집되어 OpenSearch와 Grafana Dashboard, Report를 통해 진행 상태 또는 결과 확인이 가능합니다.
📑자동화 테스트 프로세스
앞선 테스트 환경에 대한 내용으로 대략의 업무 프로세스를 유추해볼 수 있을텐데요. 자동화 담당자가 업무를 진행하는 순서로 프로세스를 정리해 보았습니다.
어느 정도 기본적인 자동화 테스트 환경을 구축해두고 나니, 주기적으로 일정하게 진행하는 업무들이 생겼습니다.
일단 기존에 자동화테스트를 구현해둔 기능과 컴포넌트들이 존재할텐데요. 서비스 이터레이션 기간이 반복되면서 UI의 변화도 계속 이뤄지게 되므로 그 기간에 맞춰서 계속 코드를 업데이트하고 QA 테스트 기간 안에는 자동화로도 동일하게 테스트를 진행할 수 있어야 합니다.
여기서 계속 동일한 서비스와 기능들만 검증하는 것은 아니고, 계속해서 신규 서비스나 기능들을 추가해주며 커버리지를 늘려가게 됩니다. 신규 기능에 대한 자동화 테스트를 구현하는 업무는 유지보수와는 달리, 공식적인 이터레이션 일정에 맞춰 진행하지는 않고 별도 과제로 추가적인 일정에 따라 진행합니다.
그리고 마지막으로 테스트 모니터링을 진행합니다.
다음은 전반적인 자동화 업무 프로세스를 간략히 표현한 그림입니다.
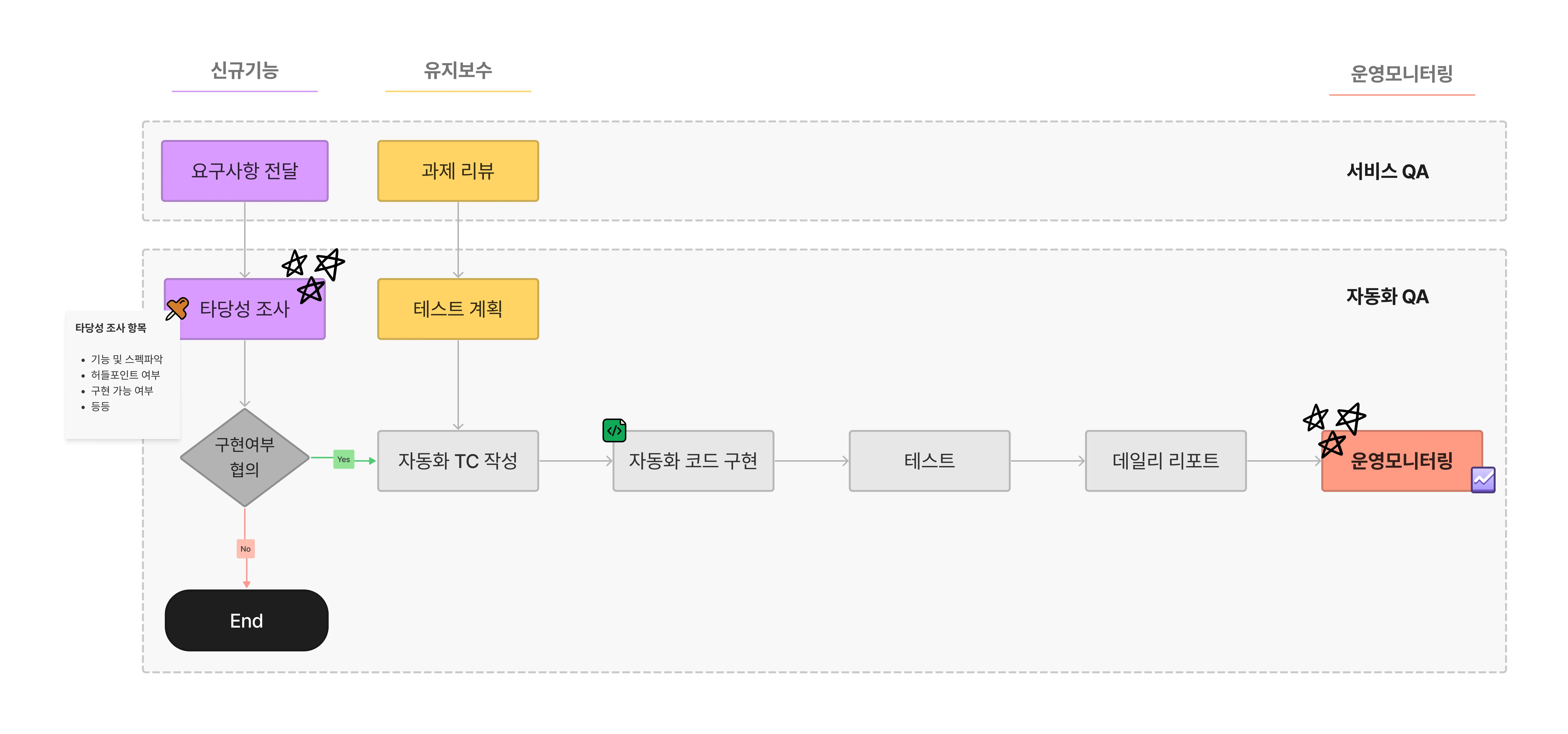
자동화 업무는 앞서 말씀드린 바와 같이 크게 3가지로 나눠서 진행하고 있는데요.
- 신규 기능 구현 프로세스
- 유지보수 대응 프로세스
- 테스트 모니터링 프로세스
첫 번째, 신규 기능 프로세스는 요구사항을 정리하고 타당성 조사를 충분히 진행한 이후 코드를 구현합니다.
두 번째, 유지보수 대응 프로세스는 자동화로 구현된 기능에서 변경되는 부분이 속한 과제를 리뷰한 후에 자동화 테스트 계획을 세우고 코드를 구현합니다.
각 프로세스에서 상황에 맞게 자동화 테스트 코드 작업이 완료된 후에는 동일하게 DeviceFarm을 통해 테스트를 진행하고, 리포트와 Grafana Dashboard를 통해 실시간 지표와 결과를 확인하게 됩니다. 이슈가 발생한 경우 Grafana와 리포트 등으로 이슈를 파악하며, OpenSearch에서 로그를 검색하여 디버깅을 진행합니다.
자동화 코드를 계속적으로 최신화하며 관리하는 것은 앱의 변경에 따른 검증에 사용할 뿐 아니라, 효과적으로 모니터링을 하기 위한 부분이기도 한데요.
그래서 저희는 릴리즈 직후부터 테스트 모니터링을 진행합니다.
그럼, 마지막 단계인 테스트 모니터링 프로세스를 상세하게 살펴보겠습니다.
1. 테스트 모니터링 프로세스 상세
일반적으로 테스트 모니터링은 다음과 같은 프로세스로 진행합니다.
- 테스트 시작
- 테스트 실행 모니터링
- Fail 발생 시 이슈 분석
- 장애일 경우, 장애 공유 및 장애 처리
특히나 테스트 모니터링을 진행하면서 발생하는 이슈들은 유형에 따라 장애로 판단이될 텐데요. 테스트 모니터링이니만큼, 장애를 빠르게 확인하고 처리할 수 있도록 저희만의 명확한 프로세스를 수립해 두어야 했고, 기존에 회사 내부에서 운영하고 있던 장애 처리 프로세스에도 자연스럽게 녹여져야 했습니다.
그래서 다음과 같은 모니터링 프로세스를 수립하게 되었습니다.
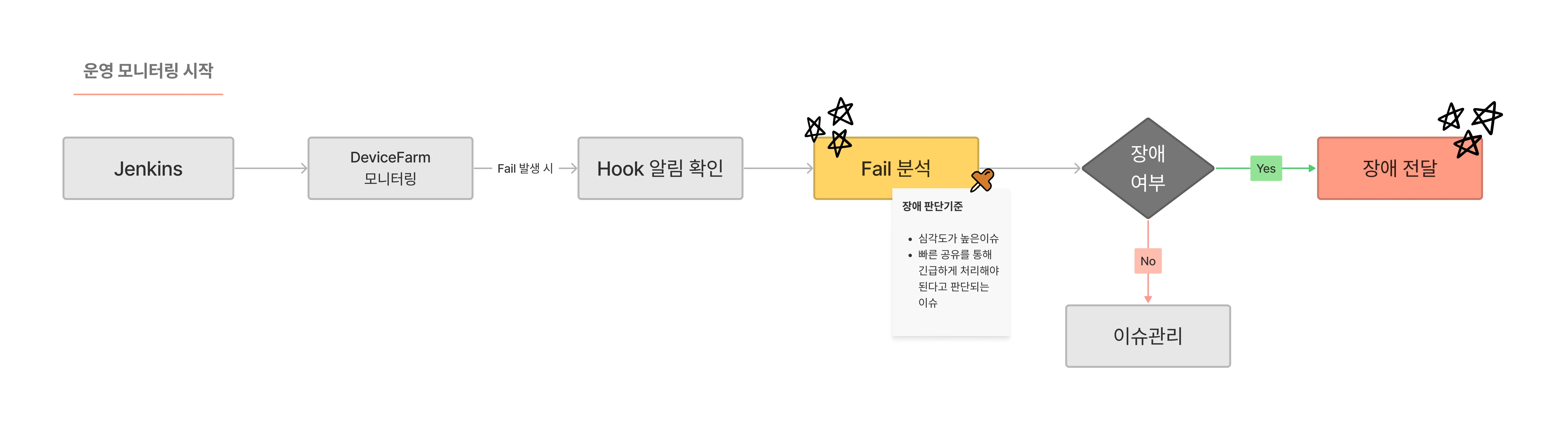
위 프로세스에서 장애전달 이후 프로세스까지 상세하게 살펴보면 다음과 같은데요.
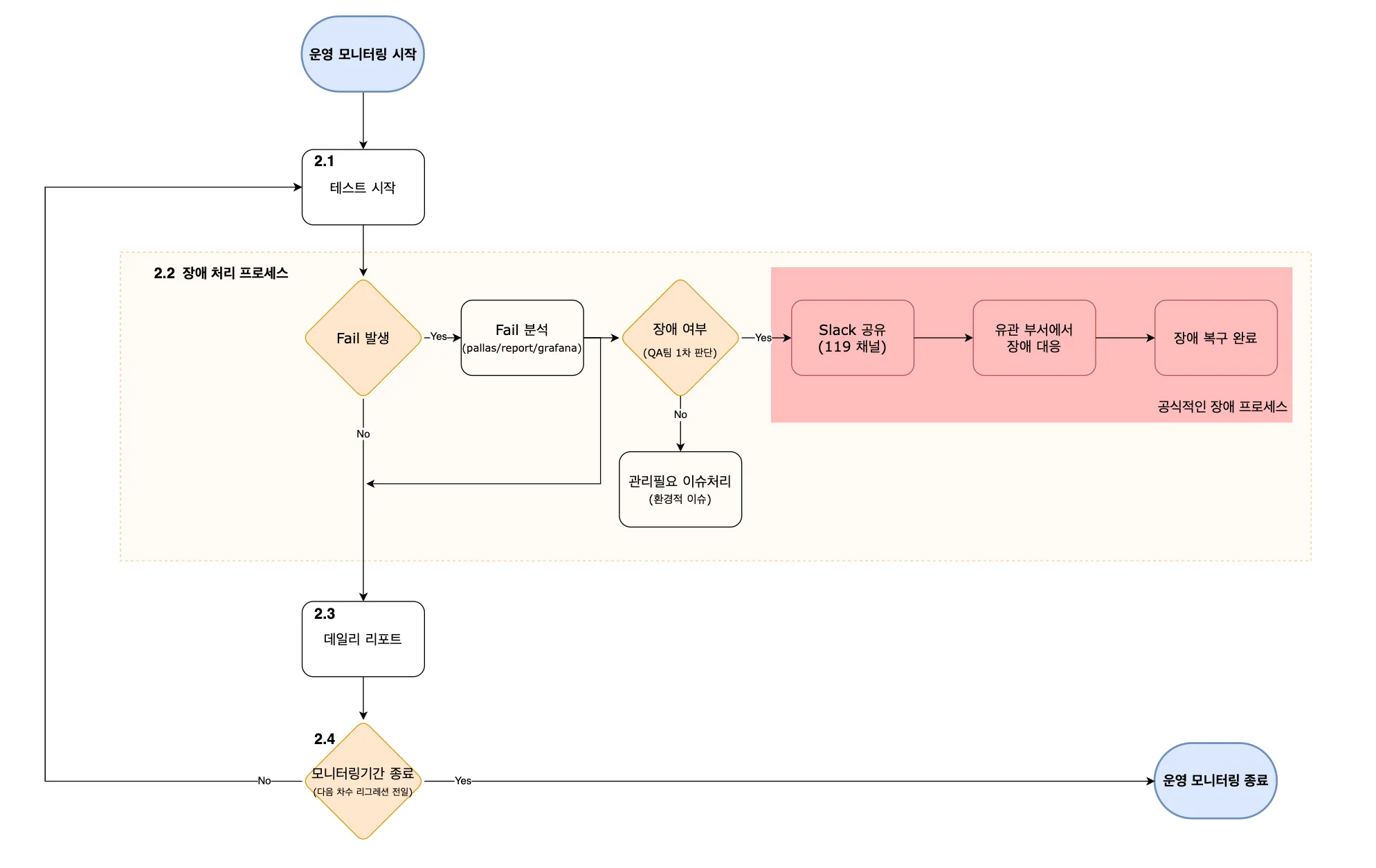
세부적으로 살펴보면, 다음 순서로 진행하게 됩니다.
- Trigger 또는 스케줄링에 의해 Jenkins로 운영테스트 시작. (테스트가 시작되었음을 Slack으로 알림)
- DeviceFarm을 통해 실행 모니터링
- Fail 발생 시 Grafana hook을 통해 Slack으로 알림
- Fail Alert을 확인하여 Grafana, OpenSearch, Report를 통한 이슈 분석
- QA 1차 판단 하에 장애일 경우, 장애 신고 채널로 공유 및 공식적인 장애 처리 프로세스 진행
- 운영테스트가 완료되면 최종 성공률과 성공/실패 건 수 등을 요약해서 Slack으로 알림
- 다시 새로운 테스트를 진행… (반복)
📌테스트 모니터링 장애 발생 사례
그럼 이번에는 장애 발생 시의 사례를 통해, 위에 설명한 테스트 모니터링 프로세스를 살펴보겠습니다.
1. Jenkins로 테스트 시작
자동화 테스트는 스케줄링 또는 원격 Trigger를 통해 실행하고 있습니다.
Slack앱으로 원격 실행하는 예시를 살펴보겠습니다.
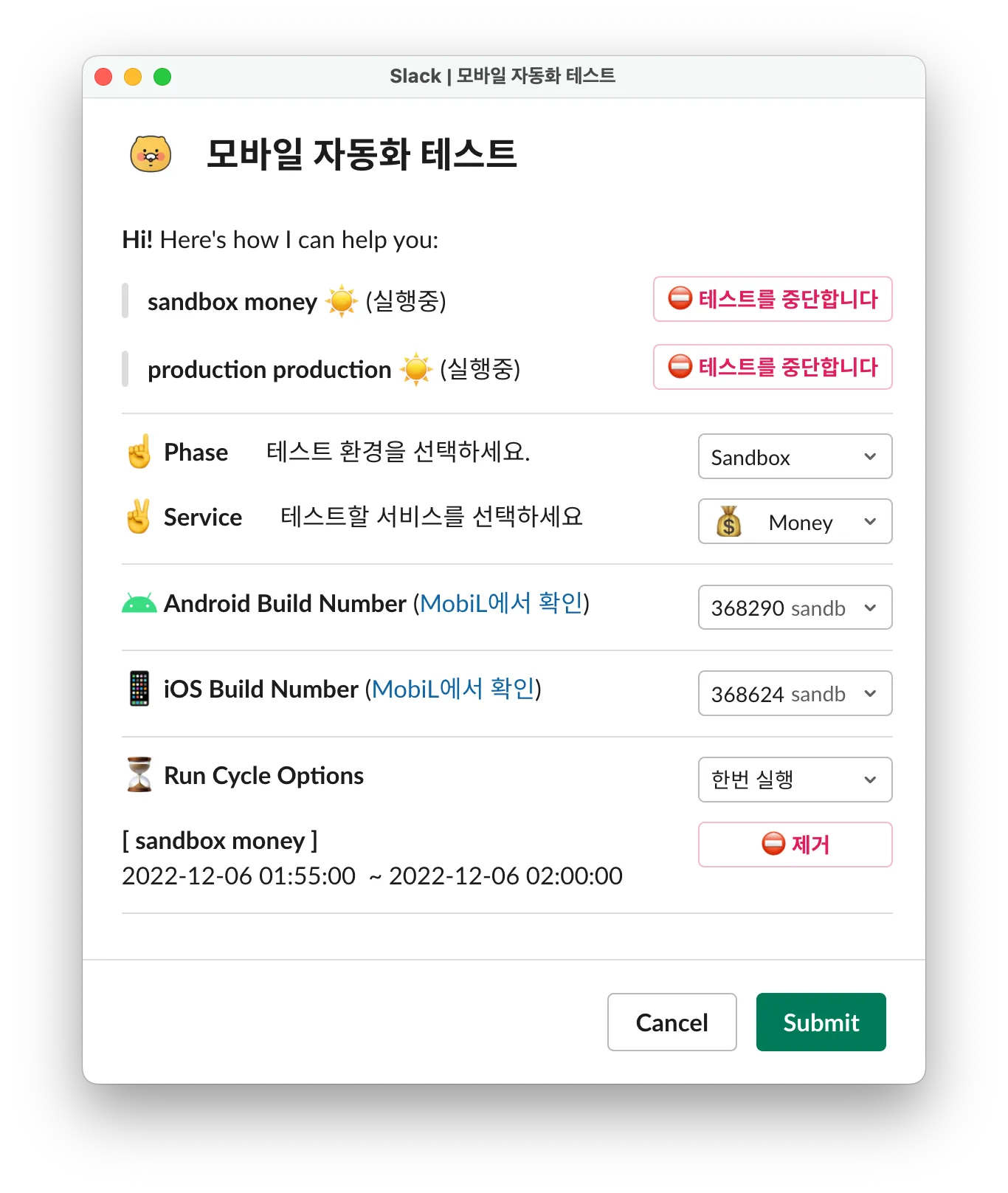
1.1 Slack에서 원격 빌드 Triggering
다음과 같이 Slack 앱을 통해 Phase와 Service, Build number, 실행 주기 옵션 등을 설정하여 실행합니다.
1.2 Jenkins에서 Slack으로 테스트 시작 알림
Jenkins가 정상적으로 실행되면, 아래와 같이 Slack으로 알림이 도착하게 됩니다.

2. DeviceFarm을 통해 실행 모니터링
카카오페이는 카카오에서 개발한 DeviceFarm을 사용하고 있습니다.
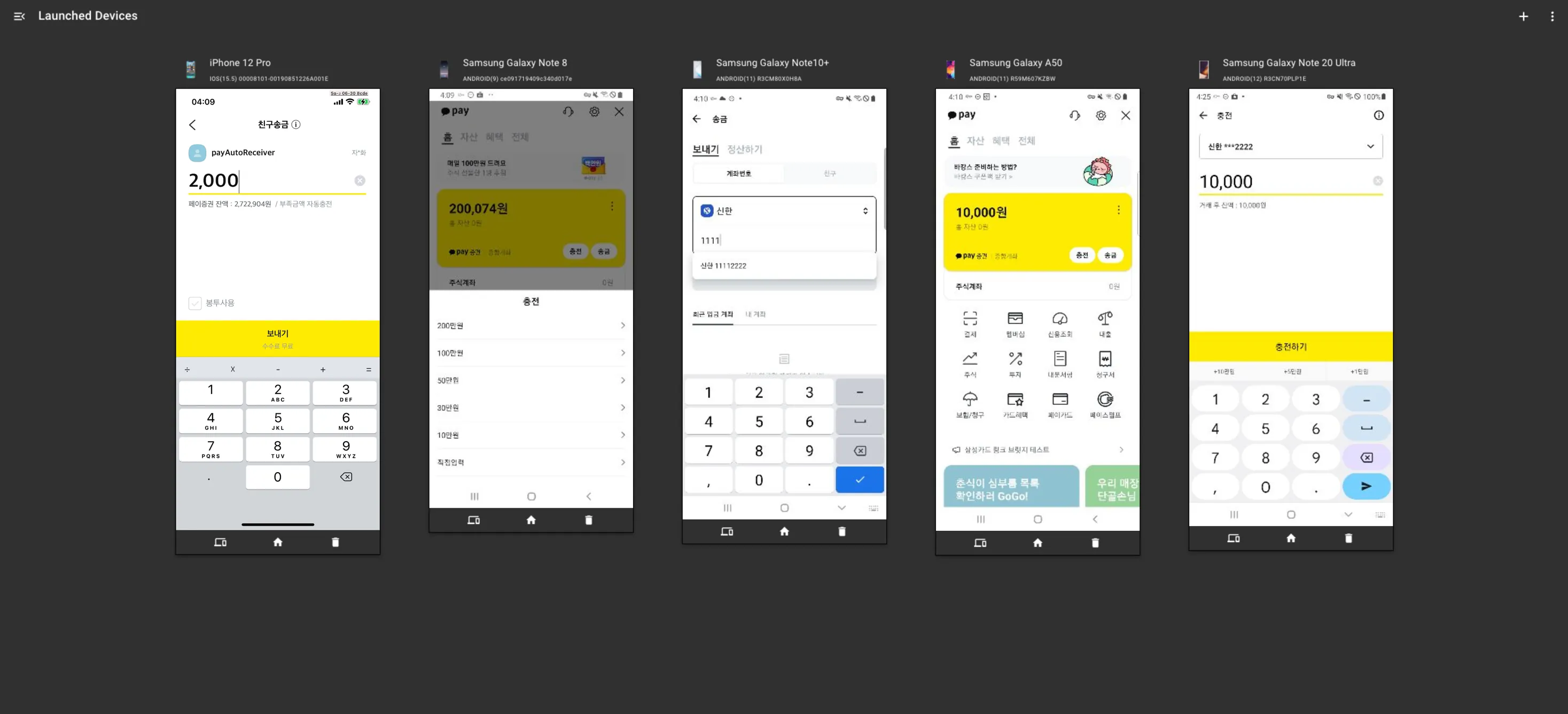
DeviceFarm으로 실행 상태를 모니터링하면서 Device Log 및 Appium server log도 확인합니다.
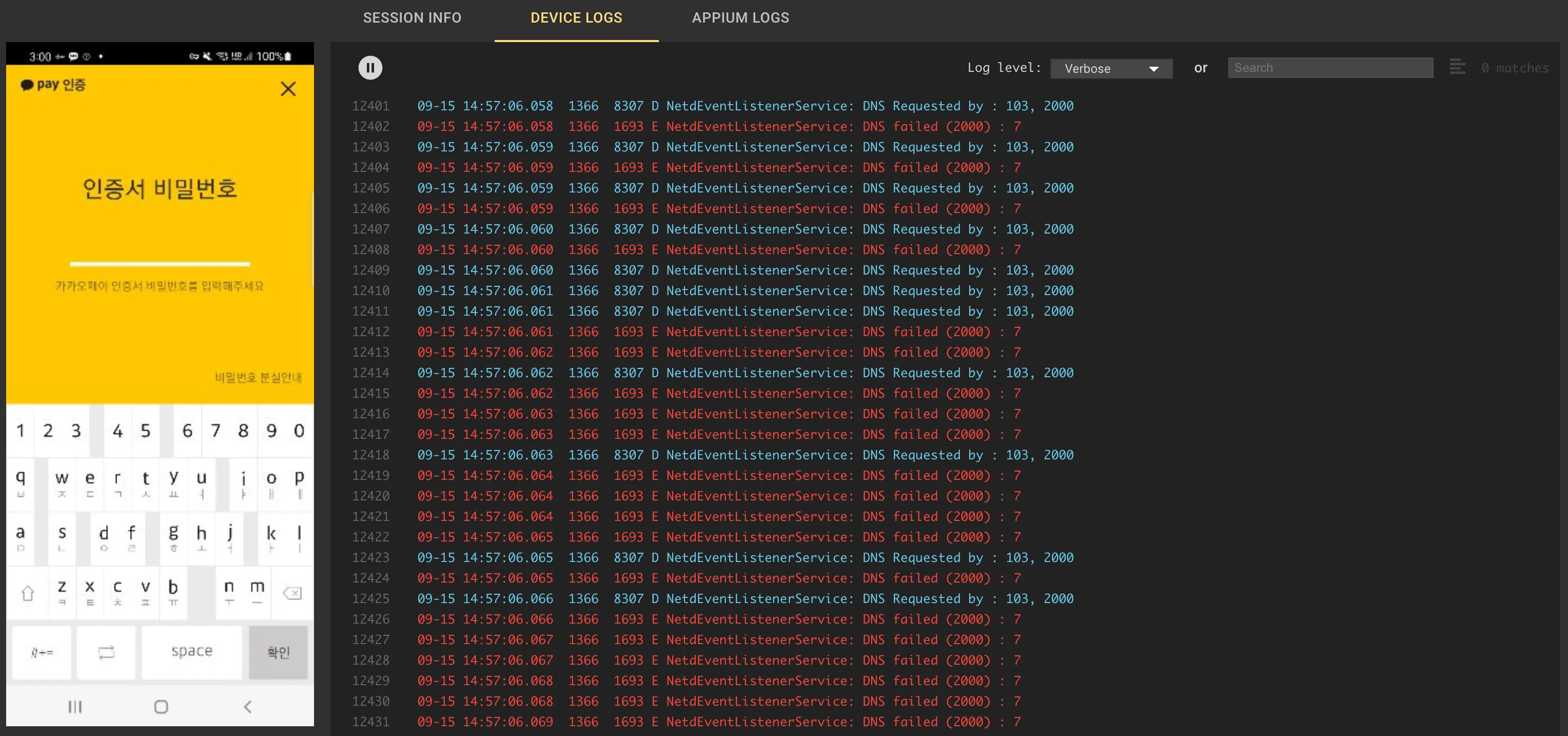
2.1 Device Log 모니터링
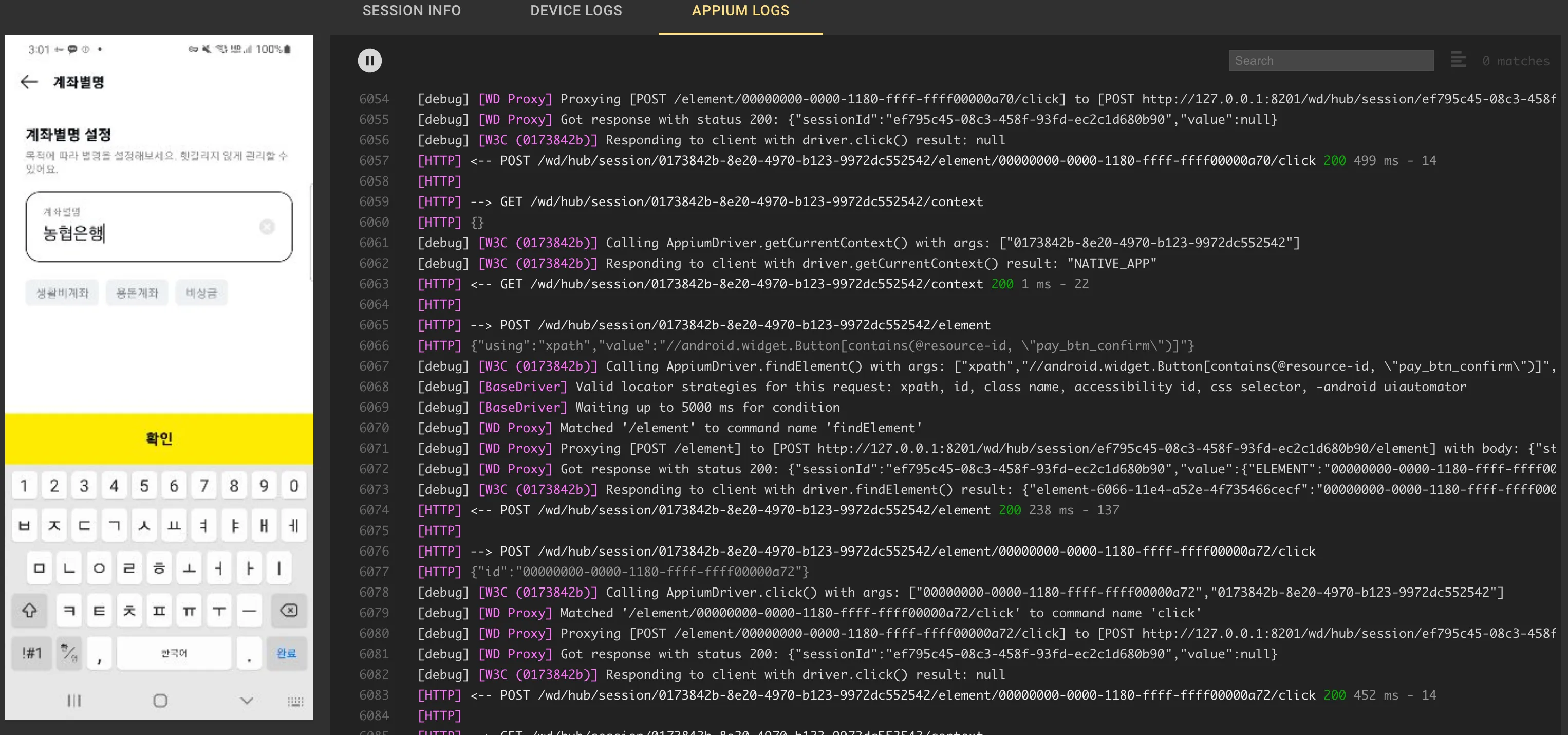
2.2 Appium server log 모니터링
3. Fail 발생 시 알림 발생
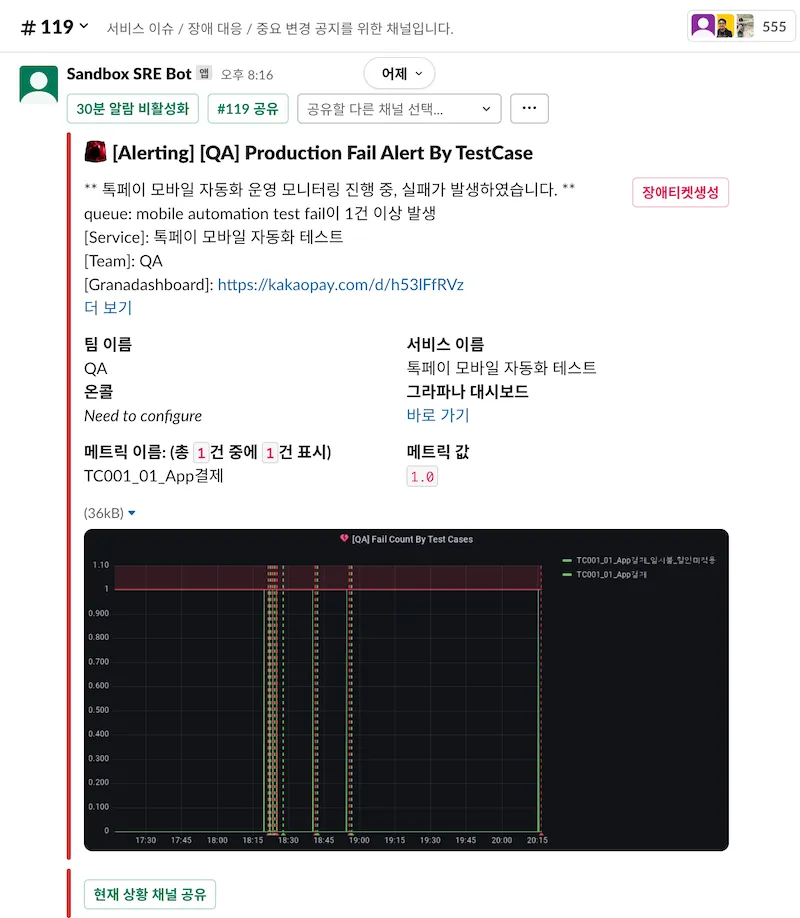
테스트 도중 실패가 발생한 경우, Grafana Hook을 통해 Slack으로 Fail Alert을 받게 됩니다.
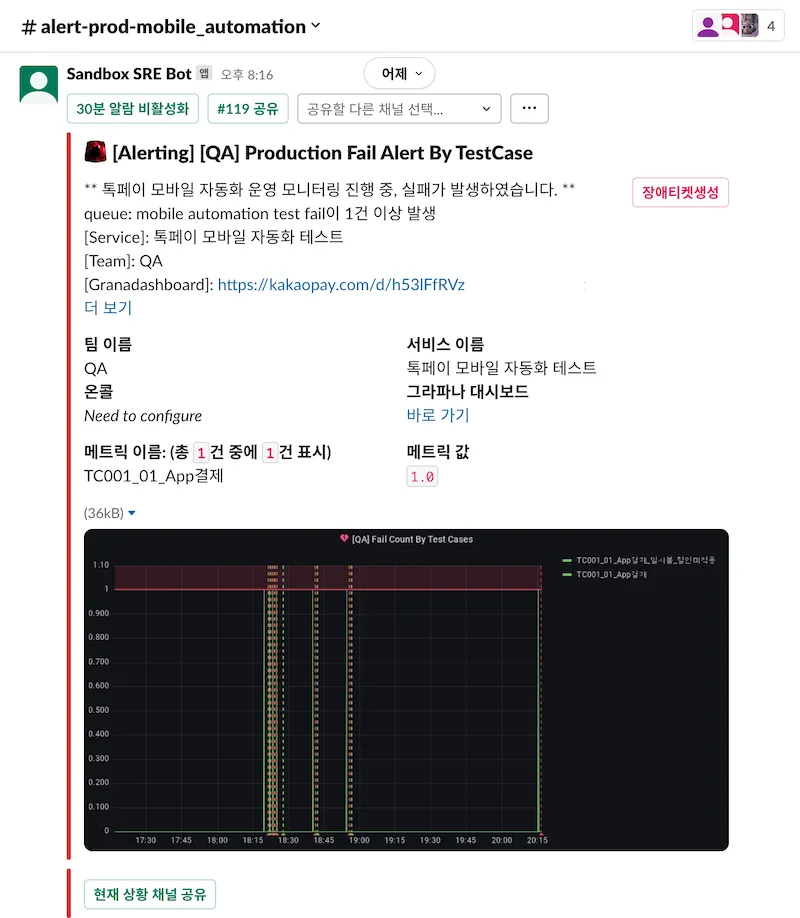
Fail Alert 상단의 버튼과 드롭다운 메뉴는 이슈 분석 이후에 공식적인 장애 신고 채널로 공유할지, 스킵할지 등 상황에 따라 사용합니다.
Fail Alert 상세 내용에서 ‘더 보기’를 클릭하면 Grafana Dashboard 링크 외에도 OpenSearch, Report의 링크를 확인할 수 있고, ‘메트릭 이름’으로는 어떤 테스트 케이스에서 실패가 되었는지 확인할 수 있습니다.
4. Fail Alert을 확인하여 이슈 분석
Fail Alert에서 실패 난 케이스명을 확인한 후 Grafana 링크를 통해 상세 이슈 분석을 시작합니다.
아래의 예시에서는 Grafana -> OpenSearch -> Report 순으로 확인할 예정입니다.
4.1 Grafana 확인
-
앞서 보여드린 Fail Alert의 Grafana Dashboard 링크를 클릭하여 Grafana Dashboard로 이동합니다.
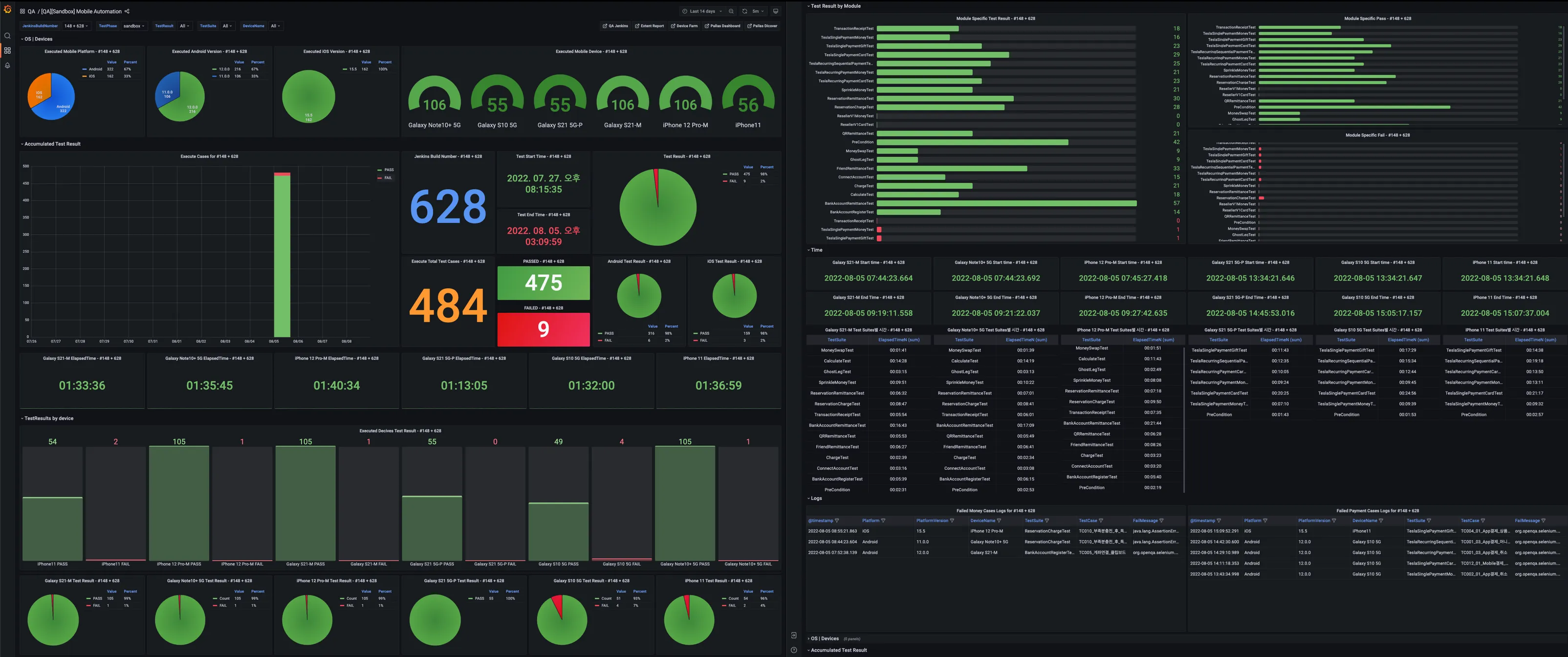
Grafana Dashboard
Grafana에서는 다양한 지표를 실시간으로 확인할 수 있는데요.
단말별 실시간 실행상태, 단말별 소요시간, 실패/성공률 등을 커스터마이징하여 확인 가능합니다. -
모니터링 그래프에서 실패 그래프를 확인합니다.
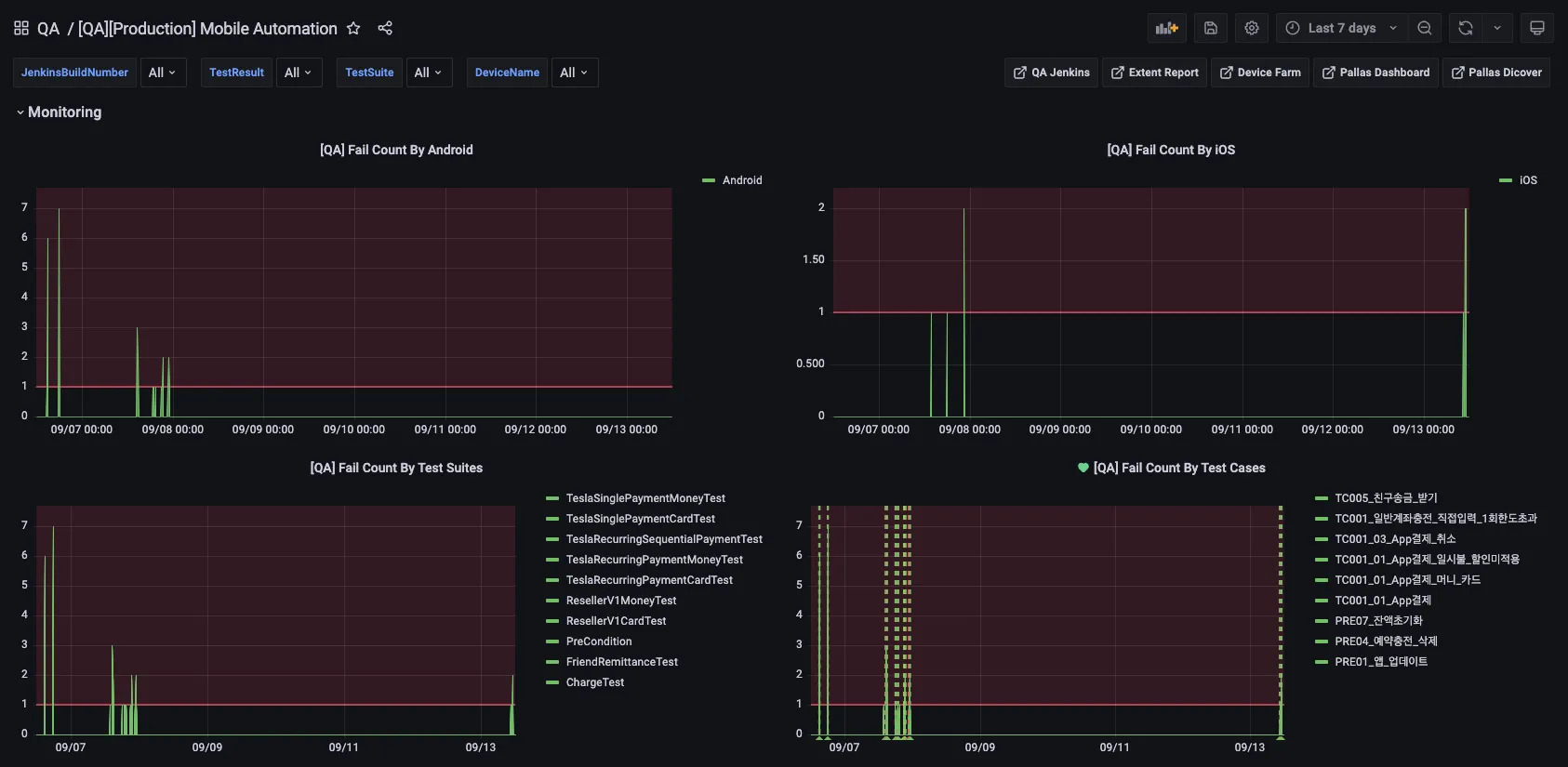
Grafana 상세 그래프 -
상세 분석단계를 진행합니다.
그라파나에는 drill down을 위한 여러가지 기능을 제공해 주고 있습니다. 메트릭에서 특이사항을 발견하게 되면, 이슈발생에 대한 타임스탬프를 기준으로 이슈의 유형이나 상태 등을 추적할 수 있습니다.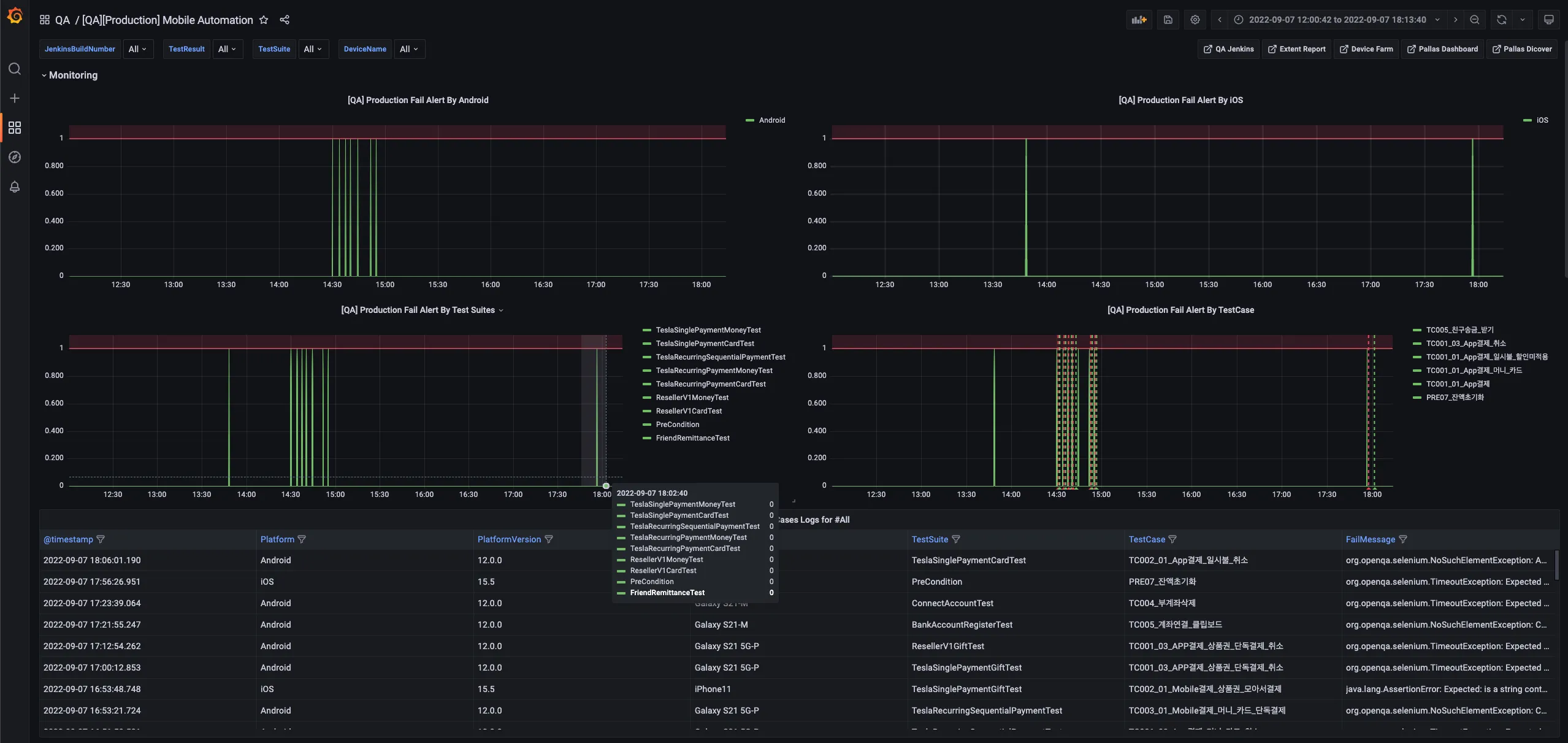
Grafana 그래프 상세분석 -
이슈의 각 정보를 확인합니다.
상세 로그를 통해 Platform, TestSuite, TestCase, 로그 정보 등 디버깅에 필요한 정보를 수집합니다.
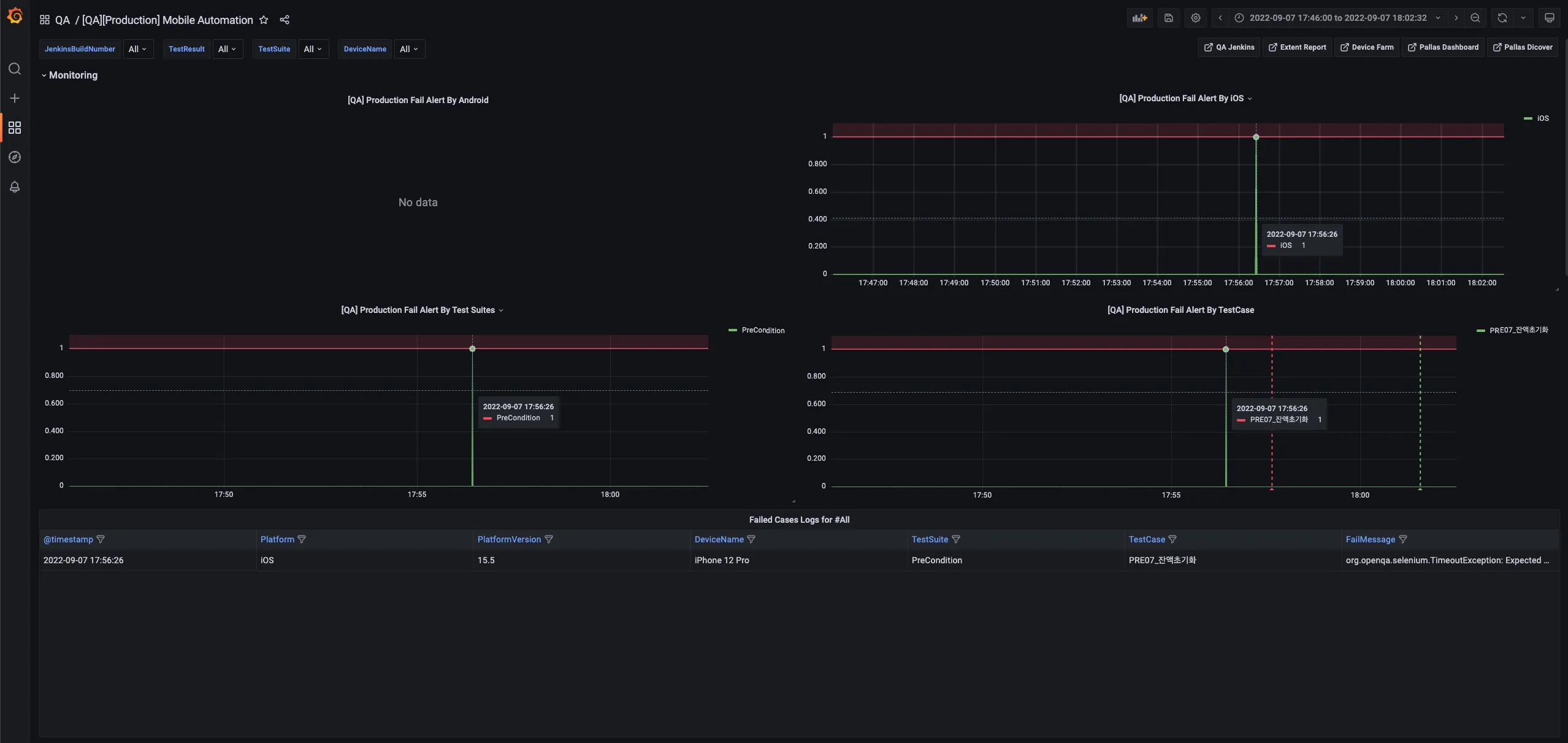
Grafana 정보확인
4.2 OpenSearch 확인
테스트의 실시간 로그는 File beat를 통해 수집되며, OpenSearch에서도 확인할 수 있는데요
-
Grafana에서의 Timestamp 값을 이용해서 OpenSearch로 이동할 수 있습니다.
(저희는 OpenSearch를 내부적으로 Pallas라는 이름으로 부르고있어 캡쳐 이미지에는 Pallas Discover로 되어있습니다.)
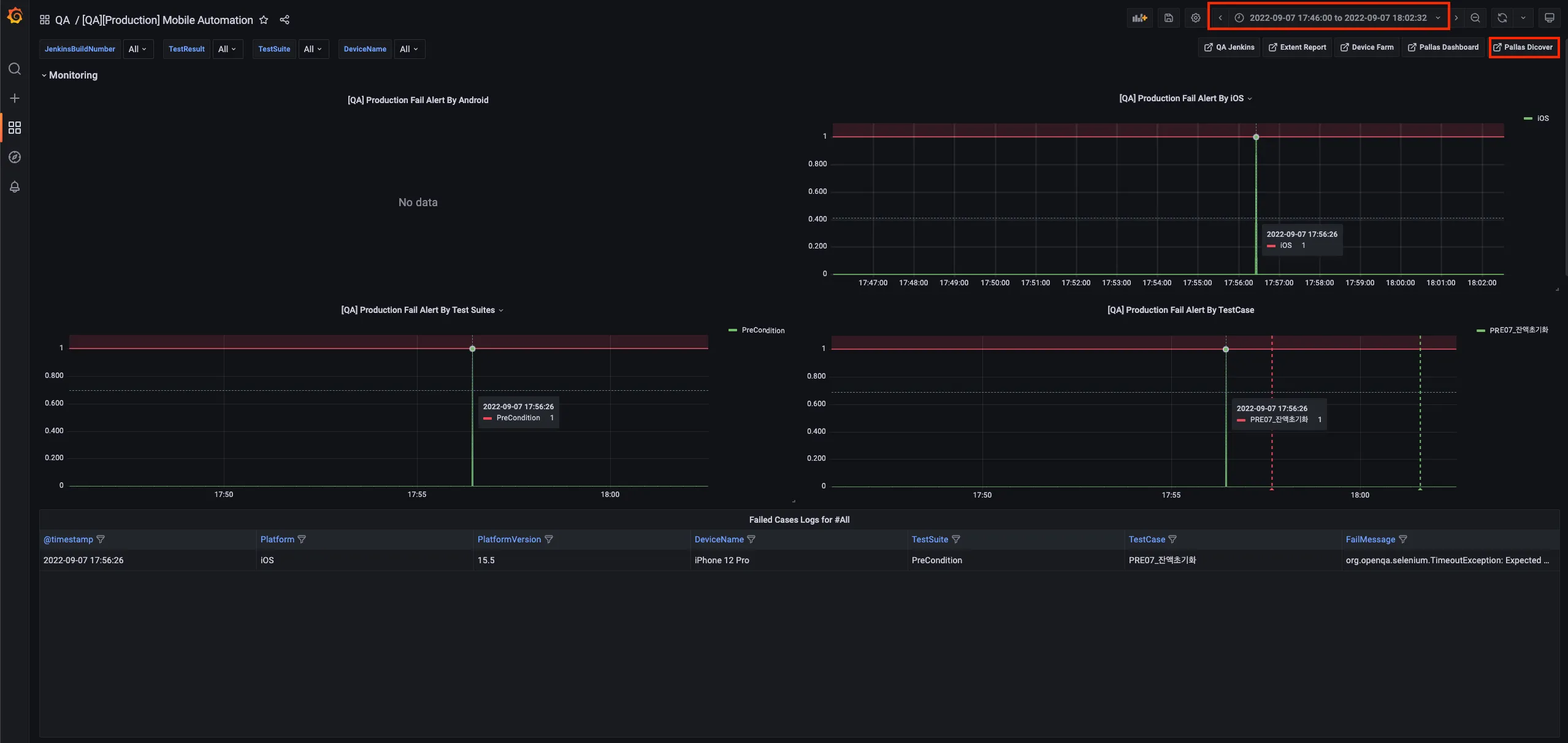
Grafana를 통한 OpenSearch 링크 -
OpenSearch에서 해당 이슈의 상세 로그를 확인합니다.
OpenSearch에서 쿼리를 통해 실패 로그를 확인할 수 있으며, 특정 기간 동안 동일한 실패가 있었는지 통합 검색할 수도 있습니다.
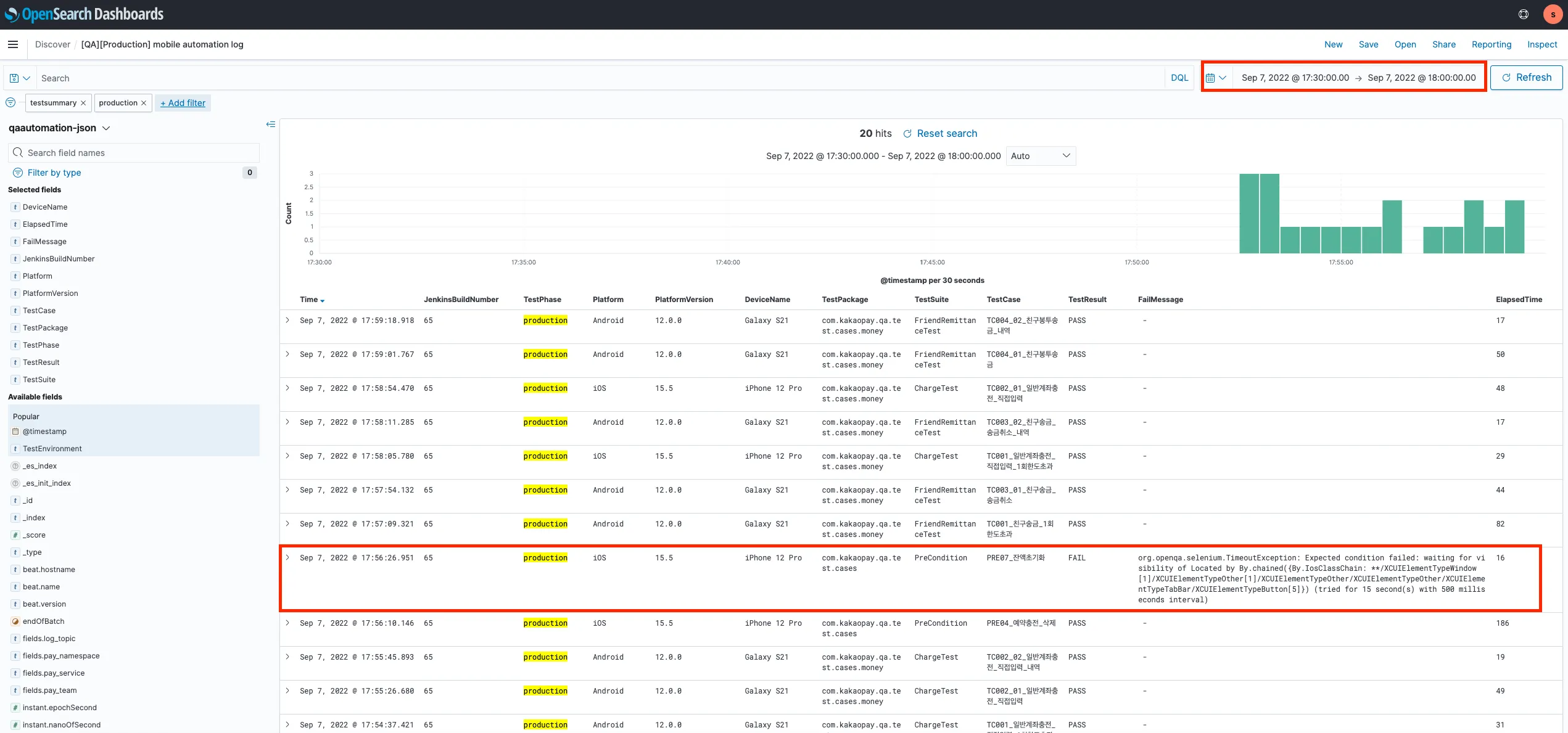
openSearch Discover
4.3 Report 확인
-
앞서 확인한 TestSuite, TestCase, Platform 정보를 통해 리포트를 확인합니다.
앞/뒤 케이스와 해당 케이스의 상세 스텝 등을 확인하며 테스트 진행상 이슈가 없었는지 확인합니다.
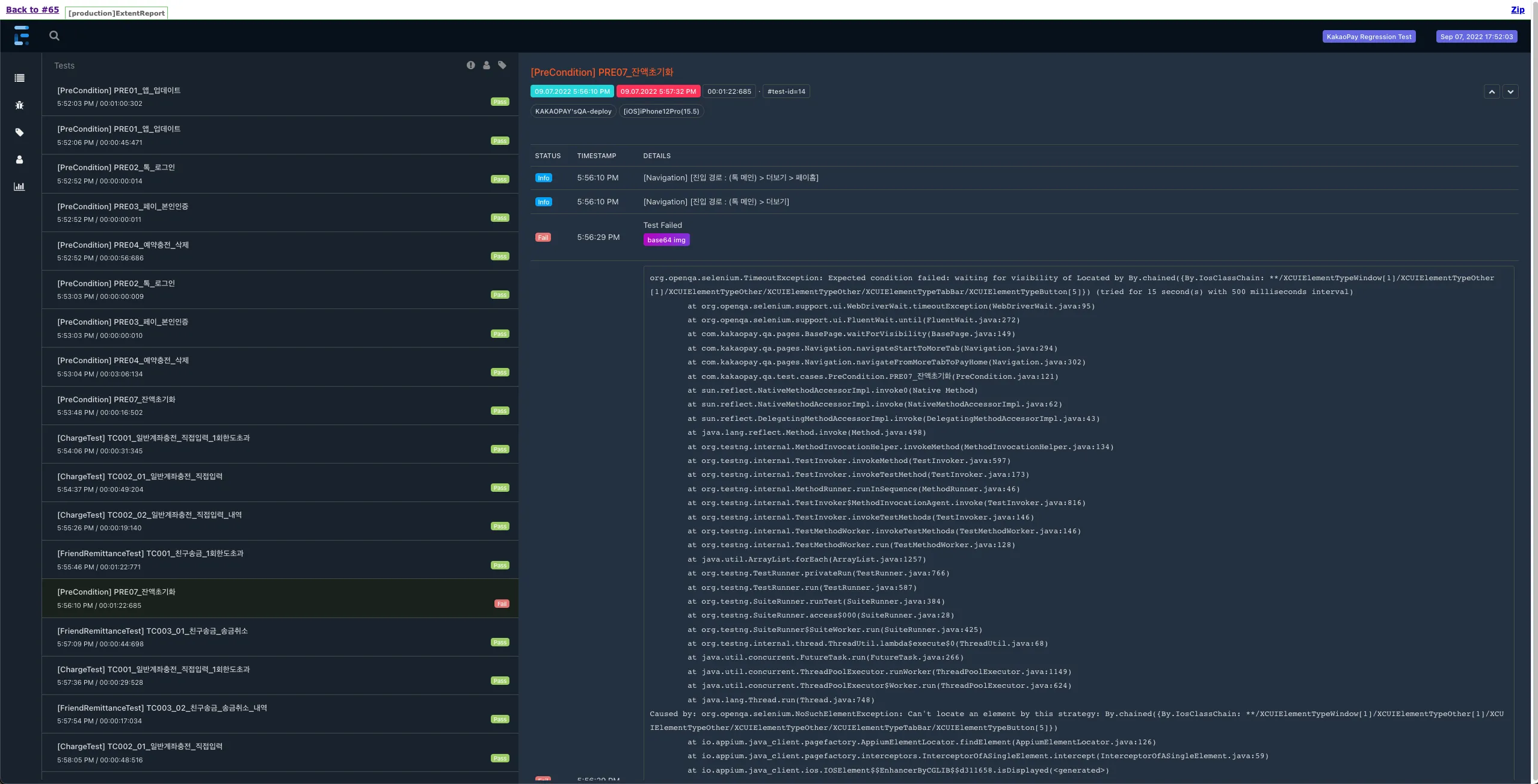
Report 확인 -
캡처 화면과 로그를 비교 확인하며 디버깅합니다.
Report 실패 캡처 이미지
5. 이슈 분석 후 장애로 판단된 경우, 장애 신고 채널로 공유 및 장애 처리 프로세스 진행
5.1 장애 판단
위에서 상세히 분석한 이슈 내용을 바탕으로, 장애 여부를 1차적으로 판단하게 됩니다.
자동화 테스트를 통해서 지속적으로 동일하게 발견되는 이슈나 긴급하다고 판단되는 이슈에 대해서는 QA팀 자체적으로 문제 상황으로 인식하고 장애를 신고하게 됩니다.
장애 판단 기준
심각도가 높거나 빠른 공유로 긴급하게 처리가 필요하다고 판단되는 이슈
- 지속적이고 동일하게 발생되는 문제 상황 (결제, 송금, 충전 등 주요 기능이 동작하지 않는 상황)
- 애플리케이션의 비정상 종료
- 화면 진입불가
5.2 장애 신고 채널에 공유
다음 단계로 장애 신고 채널에 공유합니다.
- #alert-prod-mobile_automation 채널에서 alert sharing 기능을 통해, 장애 신고 채널로 공유
- (1) 장애 신고 채널 쓰레드에 장애 상황 공유
(2) 이때는 Slack의 공유된 쓰레드에 장애 상세 내용을 작성하여 전달
다음은 공식적인 장애 신고 채널에 공유된 Fail Alert 입니다.
그리고 공유된 Fail Alert에 댓글로 작성한 장애 상세 내용입니다.

5.3 Firebase 등 참고 로그 수집
장애를 공유할 때에는 장애 상황, 정보 등을 상세하게 작성하는데요.
crash 등 크리티컬한 장애 발생 시에는 Firebase 로그를 확인하여 링크를 기입해주기도 합니다.
6. 테스트 완료
테스트가 완료되면 시작과 동일하게 Slack으로 종료 알림을 보내게 됩니다. 이때는 실패/성공 건수 및 성공률 등의 요약정보를 확인할 수 있습니다.

마치며
지금까지 모바일 자동화 테스트 및 모니터링 프로세스에 대해 공유해 드렸습니다. 저희가 모바일 자동화 테스트를 통한 모니터링 환경 및 프로세스를 정립하면서, 여러 가지 기술적인 내용을 검토하고 적용하기보다는 “어떻게 하면 안정적이고 효율적으로 모니터링하며 빠르게 이슈를 파악할 수 있을까?”를 고민했고, 이슈 파악 과정에서 “유관 부서와 효율적인 협업 프로세스를 수립하면서 기존 프로세스에 자연스럽게 참여할 수 있을까?”라는 부분을 더 많이 논의했던 것 같습니다.
현재는 위에서 말씀드린 원격 빌드 Trigger나 스케줄링을 통한 주기적인 운영 모니터링을 실행하고 있지만, 추가적으로 24시간 지속적인 모니터링을 진행하기 위한 환경을 준비하고 있고, 현재는 모니터링 부분뿐 아니라 유지보수나 커버리지 확장 등 안정적인 운영 측면에서의 많은 과제들을 진행 중에 있습니다.
본 포스팅을 준비하면서 카카오페이의 모바일 자동화 테스트가 어떻게 변화해오게 되었는지 다시 한번 돌아볼 수 있는 시간이 되기도 했습니다. 저희도 초기부터 지금까지 여러 가지 어려움들도 있었고, 다양한 고민들도 많이 있었는데요. if(kakao) 발표와 기술 블로그뿐 아니라 다양한 기회를 통해 카카오페이의 고민과 사례를 공유하며, 모바일 자동화 테스트 도입과 테스트 모니터링을 위해 무엇을 해야 할지 고민하는 분들에게 조금이나마 도움이 될 수 있기를 바랍니다. 앞으로도 모바일 자동화 테스트뿐만 아니라 다양한 유형의 자동화 테스트를 도입하고 운영하며 좋은 콘텐츠들을 공유드릴 수 있도록 노력하겠습니다.
저희와 함께 고민하고 좋은 경험을 나누고 싶은 분들이 계시다면, 현재 진행하고 있는 QA 엔지니어 채용에도 많은 관심 부탁드립니다 :)
감사합니다.




![[if kakao 2022] Batch Performance를 고려한 최선의 Aggregation](/_astro/thumb.MGIp4JrG_2cerCK.webp)
![[if kakao 2022] Batch Performance를 고려한 최선의 Reader](/_astro/thumb.CZPDDx8q_221xKf.webp)
![[if kakao 2022] 카카오페이 iOS 웹뷰 소개, 그리고 세션에서 못다한 이야기](/_astro/thumb.DTsQI1Wt_Z1kMSMB.webp)
![[if kakao 2022] ML 모델 학습 파이프라인 설계 (feat. MLOps 플랫폼)](/_astro/thumb.Dc_4_pap_ACvPj.webp)
