![[if(kakaoAI)2024] 카카오페이증권의 Kubernetes 지능형 리소스 최적화 (feat. Dr.Pym Project 공유)](/_astro/thumb.CGBHxK2H_ZWFBjN.webp)
시작하며
안녕하세요. 카카오페이증권 DevOps팀의 스티브입니다.
이번 글에서는 if(kakaoAI)2024에서 발표한 “Kubernetes 지능형 리소스 최적화 (feat. Dr.Pym Project 공유)” 세션의 내용과 함께 발표 시간 상 하지 못했던 이야기들까지 함께 공유하려고 합니다.
클라우드 환경에서 Kubernetes를 운영하며 리소스 비용 절감과 서비스 안정성 향상에 고민하는 분들을 위한 글입니다.
프로젝트 탄생 비화
“Kubernetes 클러스터에 구성된 서비스의 리소스들을 어떻게 관리하고 계신가요?”
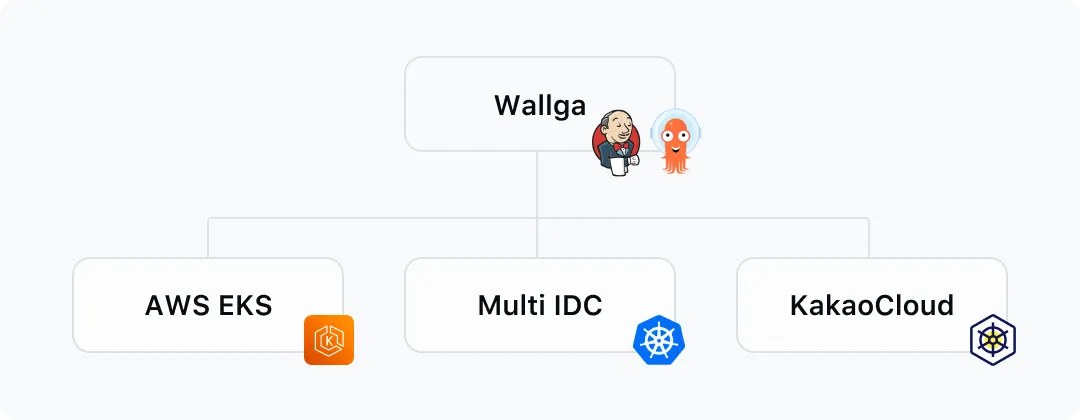
카카오페이증권 DevOps팀에서는 Wallga라는 CI/CD 플랫폼 위에 EKS, 카카오클라우드 같은 매니지드형 Kubernetes 클러스터들과 IDC 온프레미스 환경에 직접 구성한 Kubernetes 클러스터들을 구성하여 운영하고 있습니다.
이처럼 다양한 Kubernetes 클러스터 위의 서비스를 배포하려고 할 때는 DevOps팀에서 제공하고 있는 Wallga 플랫폼을 사용하여 Code push와 CD Job 실행, 단 두 번의 업무수행과정을 통해 원하는 Kubernetes 클러스터로 애플리케이션을 배포할 수 있게 됩니다.
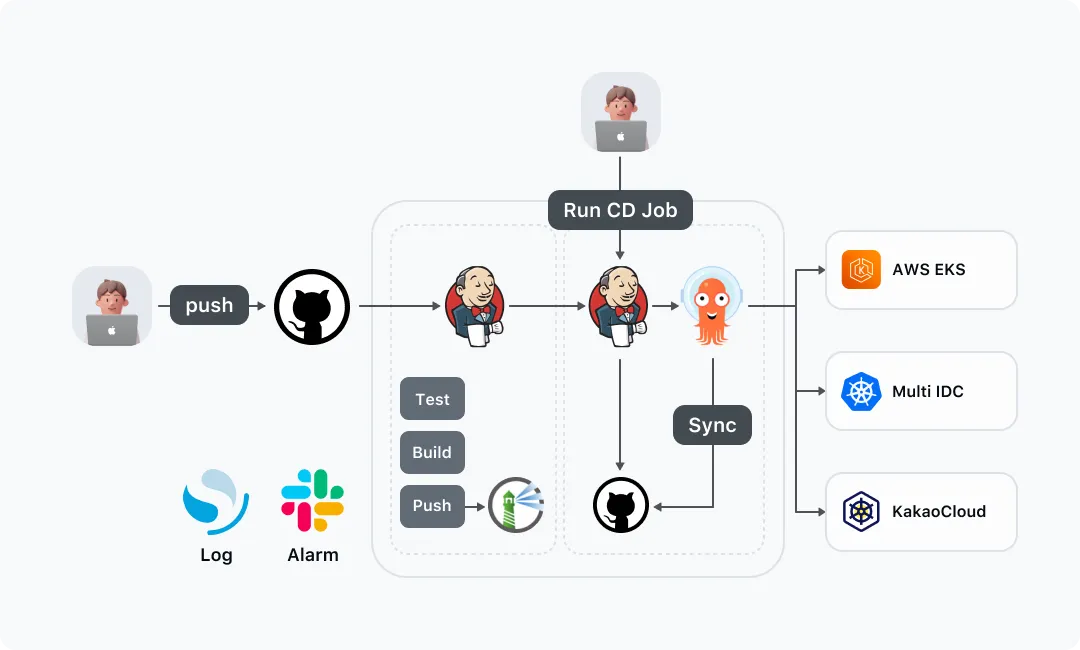
Wallga에 대한 자세한 내용은 지난 포스팅인 카카오페이증권이 생각하는 DevOps문화와 Platform Engineering의 방향성을 참고해 주시면 감사하겠습니다.
또한 CD Job 수행 시 젠킨스에서는 배포에 필요한 여러 파라미터들을 선택할 수가 있는데요. 이 중에는 배포하려는 서비스의 리소스에 대한 스펙을 선택할 수 있습니다.
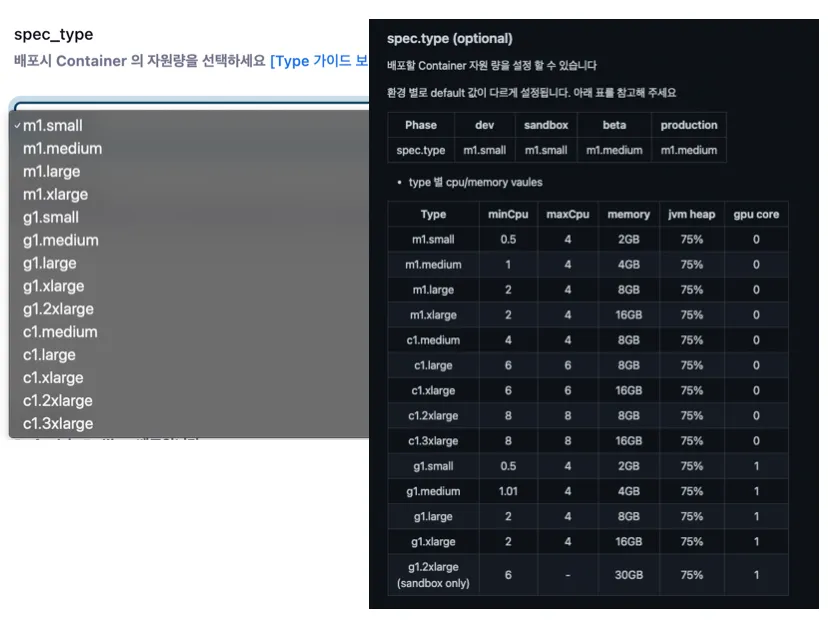
여기서 원하는 리소스를 선택한 후 젠킨스 Job을 실행하게 되면 ArgoCD를 통해 선택된 리소스 스펙으로 배포가 나가게 됩니다.

그런데 이러한 과정 속에서 세 가지 이슈에 직면하게 되었습니다.
- 지속적인 리소스 부족
- 서비스 안정성 부족
- Rightsizing에 대한 고민
첫 번째는 지속적 리소스 부족입니다. IDC 온프레미스의 구성된 Kubernetes 클러스터 같은 경우 운영하다 보면 지속적으로 노드의 리소스가 부족한 현상들이 발생하게 됩니다. 또한 EKS 같은 경우에는 오토스케일링그룹 등을 사용하기는 하지만 이로 인한 비용이 지속적으로 증가할 수밖에 없게 됩니다.
두 번째는 서비스 안정성 부족입니다. 각각의 서비스들은 선택한 리소스 스펙을 변경 없이 계속적으로 사용하게 되는 게 일반적인데요. 그러다 보니 트래픽 증가나 감소에 대한 대응이 수동적일 수밖에 없고 리소스 부족에 따른 OOM이나 스로틀링 현상들도 지속적인 모니터링을 통해야지 비로소 확인이 되는 상황이었습니다.
세 번째는 Rightsizing에 대한 고민입니다. 내 서비스의 현재 리소스가 과연 적절한지 부족하진 않은지 이벤트가 있는데 Pod를 어느 정도 늘려야 할지 이벤트가 끝났을 때 Pod를 어느 정도 줄여야 할지 등 적절한 리소스로 설정하고 선택하는데 어려움이 있었습니다.
그래서 저희는 Kubernetes 플랫폼 상에서 서비스들의 리소스가 효율적으로 사용되는지 확인하고 비용 절감과 서비스 안정성 향상이라는 두 가지 목표를 동시에 달성하기 위해 스스로 학습하고 의사결정을 가이드해 주는 지능형 시스템 개발을 결정했습니다. 이를 통해 서비스들의 리소스를 탄력적으로 상황에 맞게 최적화하고 사람의 개입을 최소화하게끔 자동화하여 생산성을 향상할 수 있는 시스템을 개발하기로 한 것이죠.
이러한 배경에서 시작된 프로젝트가 바로 Dr.Pym 프로젝트입니다.
프로젝트 진행 과정

Dr.Pym은 앤트맨 영화에 핌입자를 발명한 박사입니다. 핌입자는 물건의 크기를 원하는 대로 바꿀 수 있게 하는 기능을 합니다. 저희는 우리가 구축할 이 시스템을 통해 원하는 대로 서비스의 리소스 크기가 바뀌게끔 하고 싶었습니다. 저희는 이 프로젝트를 3개의 Phase로 나눠서 진행을 하였고 각각의 Phase를 거치면서 Dr.Pym 시스템을 고도화하게 됩니다.
Phase 1
Phase 1은 Dr.Pym 시스템을 구축하고 서비스들의 CPU와 메모리에 대한 리소스를 추천하는 기능을 제공하는 것이 목표였습니다. 현재 운영 중인 서비스들의 리소스 사용량을 확인하여 추천값을 계산하고 이를 통해 서비스들의 리소스 최적화를 이루게 하는 것이죠.
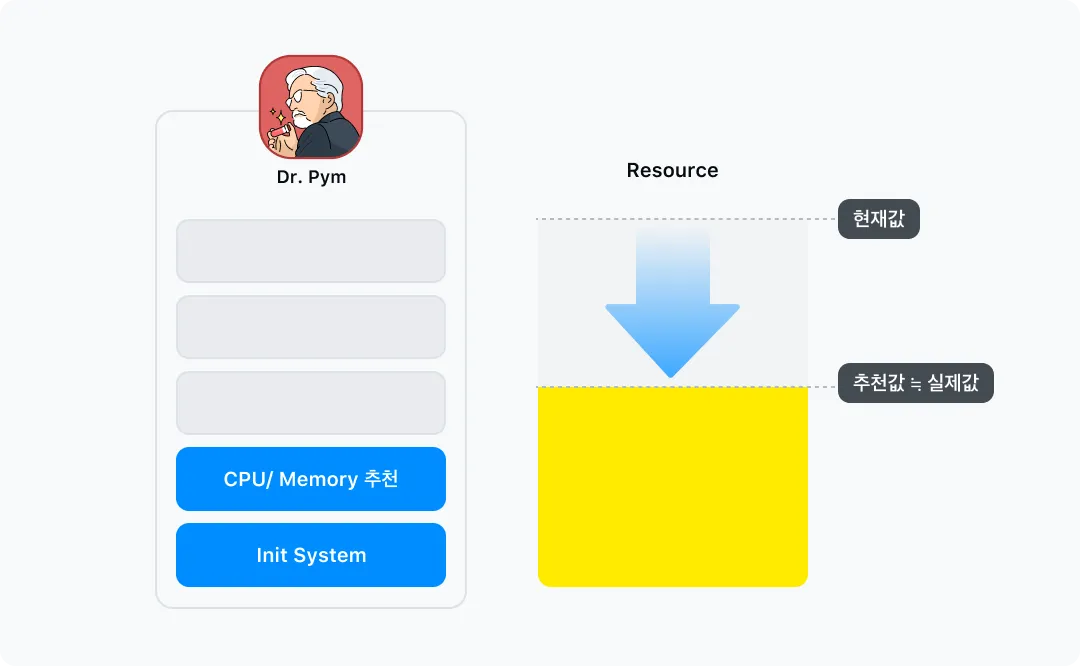
그렇다면 CPU와 Memory 리소스에 대한 추천값을 어떻게 계산했을까요?
Prometheus의 Recording Rule 활용
먼저 서비스들의 리소스 사용량을 확인하기 위해서 프로메테우스의 메트릭을 활용합니다. 그런데 프로메테우스에서 2주 치 이상의 메트릭에 대한 쿼리의 결과를 응답받으려면 너무 많은 시간이 소요됩니다. 또한 해당 쿼리를 처리하느라 프로메테우스의 부하가 발생합니다. 이를 해결하고자 프로메테우스의 recording rule을 활용하여 쿼리 결과를 미리 실행시켜 두는 방식을 사용하였습니다. 그럼으로써 빠르게 쿼리 결과를 수집할 수 있게 되고 프로메테우스의 부하를 방지할 수 있습니다.
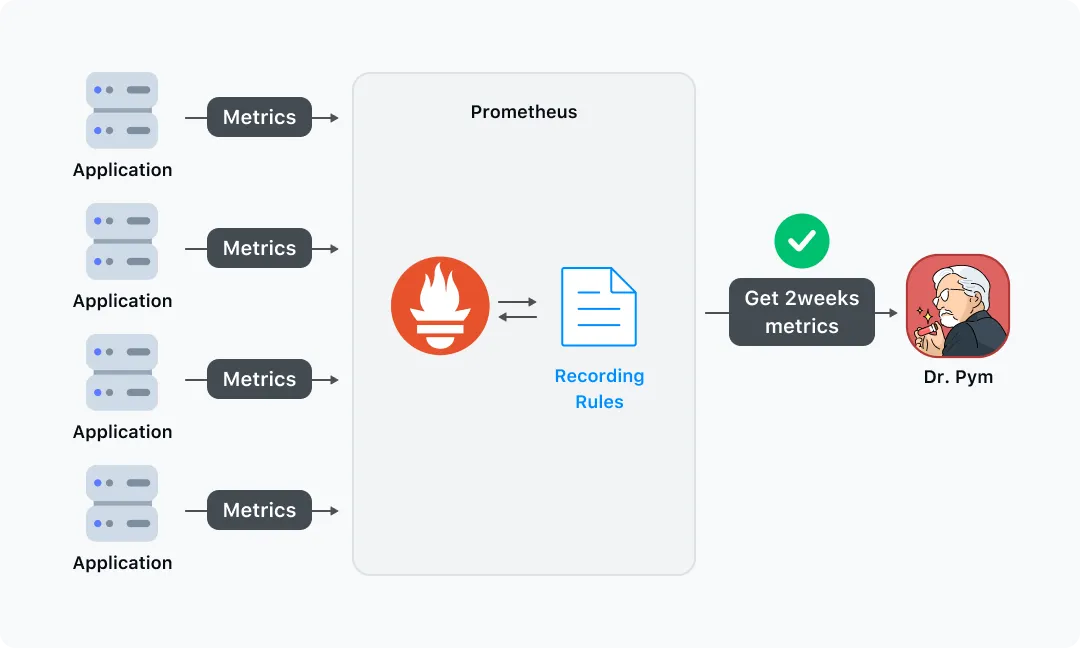
CPU 추천값 계산
CPU는 quantile_over_time이라는 프로메테우스에서 제공하는 함수를 사용해서 구합니다. 주어진 기간 동안의 n분위 값을 구하는 함수인데요. 카카오페이증권의 대부분 서비스들은 배포/기동시 순간적으로 많은 CPU를 사용하고 평시에는 CPU 사용량이 높지 않습니다. 순간적으로 튈 수 있는 1% 정도의 이상치 값들은 CPU의 Limit을 제거함으로써 해결할 수 있다고 판단하고 상위 99%의 값을 선택하였습니다.
- record: record:container_cpu_usage_seconds_total:rate_1m
expr: |
rate(container_cpu_usage_seconds_total{container!~'hc|POD|', image!=''}[1m]) * on (namespace, pod) group_left(label_wallga_app) kube_pod_labels {label_wallga_app !=''}
- record: record:container_cpu_usage_seconds_total:max_rate_1m
expr: |
max by (namespace, label_wallga_app) (record:container_cpu_usage_seconds_total:rate_1m)
- record: record:container_cpu_usage_seconds_total:max_by_app_2w
expr: |
quantile_over_time(0.99, record:container_cpu_usage_seconds_total:max_rate_1m{label_wallga_app!=""}[2w])Memory 추천값 계산
메모리는 메모리라는 리소스 특성을 고려하여 최댓값을 추출한 다음 마진(개발은 15%, 운영은 20%)을 더해서 추천값을 만듭니다.
- record: record:container_memory_working_set_bytes:rate
expr: |
container_memory_working_set_bytes{job="kubelet", metrics_path="/metrics/cadvisor", image!="", container!~"hc|POD|" } * on (namespace, pod) group_left(label_wallga_app) kube_pod_labels{label_wallga_app !=''}
- record: record:container_memory_working_set_bytes:max_over_2w
expr: |
max_over_time(record:container_memory_working_set_bytes:rate{label_wallga_app!=""}[2w])
- record: record:container_memory_working_set_bytes:max_by_app_2w
expr: |
max by (namespace, label_wallga_app)( record:container_memory_working_set_bytes:max_over_2w)추천값 적용 방법
-
CPU는 추천값으로 Request에만 적용하고 Memory는 추천값으로 Request와 Limit을 동일하게 적용합니다.
resources: limits: memory: 4Gi requests: cpu: '500m' memory: 4Gi -
너무 잦은 추천을 방지하기 위해 0.25 단위의 올림을 하여 추천을 합니다.
그렇다면 여기서 왜 CPU Limit만 제거했는지에 대해 궁금해하실 것 같습니다.
이와 관련된 내용은 다음 포스팅인 “CPU Limit 제거를 통한 Kubernetes 성능 개선기(feat. Kubernetes 리소스 특성의 차이)“에서 별도로 설명하는 시간을 갖도록 하겠습니다.
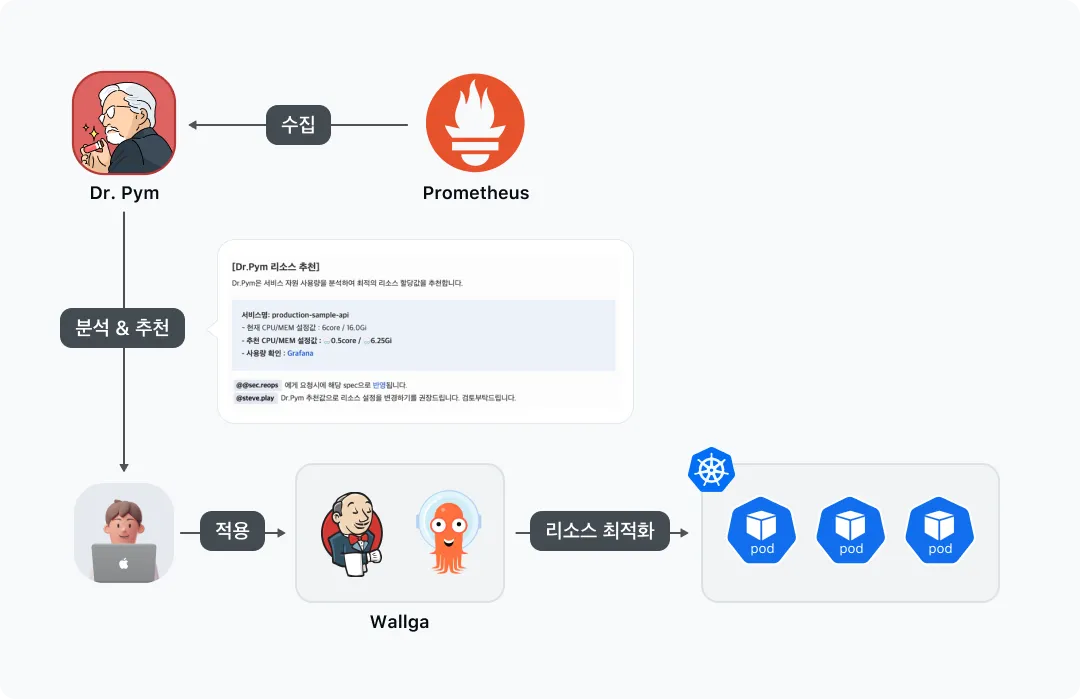
결과
이렇게 Phase 1을 통해 Dr.Pym 시스템 구축이 완료되었습니다. Phase 1의 아키텍처는 아래와 같은 모습이 됩니다.
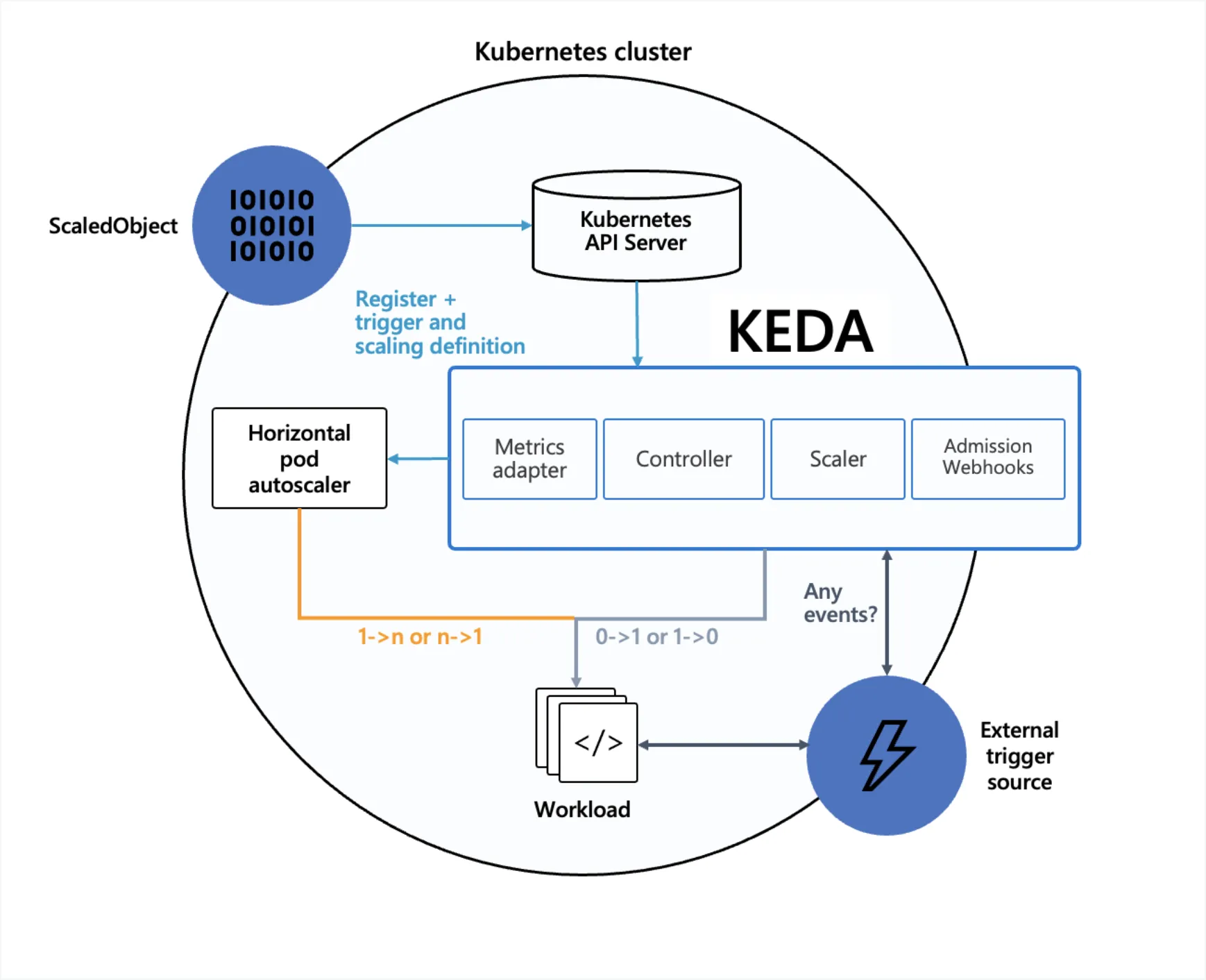
Phase 2
Phase 2에서는 KEDA(Kubernetes Event-driven Autoscaling)를 Add on 하여 플랫폼에 안착시키는 것이 목표입니다. KEDA는 CPU 및 메모리와 같은 시스템 지표를 기반으로 확장하는 HPA(Horizontal Pod Autoscaling)와 달리 이벤트를 기반으로 애플리케이션을 확장하도록 설계되어 있는 오픈소스 플랫폼입니다. 모든 Kubernetes 클러스터에 설치가 가능한 단일목적의 경량화된 컴포넌트이며 2023년 8월에 CNCF(Cloud Native Computing Foundation) 졸업 Project가 되었습니다.
저희는 이미 HPA 기능을 플랫폼에서 제공하고 있었지만 아래 표와 같이 KEDA는 HPA의 상위 도구라고 판단하였고 도입을 결정하였습니다.
| HPA | KEDA | |
|---|---|---|
| 기본 원리 | CPU/Memory 기반 | 다양한 이벤트 기반 |
| 설정 복잡도 | 간단 | 상대적으로 복잡 |
| 스케일링 시나리오 | 제한적 | 유연 |
| 확장성 | 제한적 | 높음 |
| HPA와의 관계 | - | 내부적으로 HPA를 사용함 |
KEDA를 도입하면서 얻게 되는 효과
-
안정성
Phase 1의 적용으로 의도치 않게 비대했던 서비스들이 슬림해졌습니다. 이로 인해서 갑작스러운 트래픽의 증가로 부하가 발생한다면 서비스들이 이를 감당할 수 없을 확률은 오히려 더 커질 수 있습니다. 이를 보완하기 위한 안전장치 역할을 합니다.
-
확장성
Kubernetes에서 기본적으로 제공하는 HPA는 심플한 메트릭 기반의 스케일만을 제공합니다. 저희는 Phase 3을 위해서라도 HPA보다 더 다양한 방식의 스케일을 지원하는 KEDA를 도입해야 했습니다.
KEDA 도입과정에서 고민했던 부분
-
Jenkins CD Job Parameter의 Replicas
저희는 배포 시 CD Job을 통해 replicas를 입력해서 나가게 됩니다. 그리고 CD 수행 시 입력값들을 재차 CD Parameter의 Default값으로 저장하기 때문에 항상 최신의 값을 유지하게 됩니다. 그러나 KEDA를 도입하게 되면서 Replicas의 수가 가변적으로 계속 변할 수 있게 되었습니다. 그러다 보니 CD Job을 통한 배포 시에 Parameter의 replicas 값으로 인해 의도치 않은 scale-in이 발생하고 이로 인해 이슈가 발생할 수 있습니다.
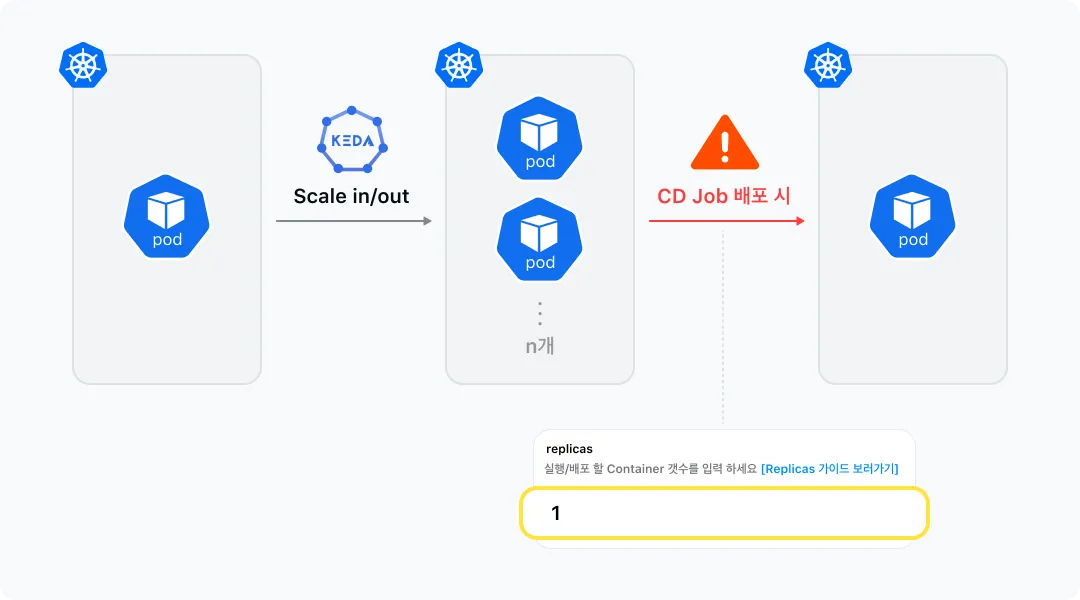
그래서 저희는 default 값을 latest 값으로 설정하게 하여 현재 배포시점에 replicas 개수로 배포가 되게 파이프라인을 개선하였습니다.
-
KEDA ScaledObject의 Default 값
KEDA의 ScaledObject default 값은 wallga platform에서 제공하는 기준값을 의미합니다. KEDA의 ScaledObject란 KEDA에서 사용되는 커스텀 리소스로 스케일링 규칙을 정의할 수 있습니다.
Phase 1을 통해 CPU는 Limit이 없어졌기 때문에 순간적으로 100%를 넘더라도 이슈가 없습니다. 오히려 너무 잦은 scale을 막기 위해서 저희는 평균 100% 이상이 되어야 Scale이 가능하게 구성하였습니다. ifkakao 발표 당시에는 150%로 설명하였으나 안정성 측면에서 보다 보수적인 100%로 변경하여 현재는 사용하고 있습니다.
반면 메모리는 request와 limit을 같게 두고 마진을 20% 추가했기 때문에 80% 이상이 된다면 임계치를 넘었다고 판단하여 scale이 되게 하였습니다. 물론 이 값들은 default 값이기 때문에 서비스별로 언제든 변경 적용이 가능합니다.
triggers: - type: cpu metricType: Utilization metadata: value: '100' - type: memory metricType: Utilization metadata: value: '80'
결과
Phase 2까지 거친 Dr.Pym시스템은 아래와 같은 구성이 됩니다. 기존 Phase 1 구성 위에 KEDA를 통한 Scale in/out 기능이 추가되었습니다.
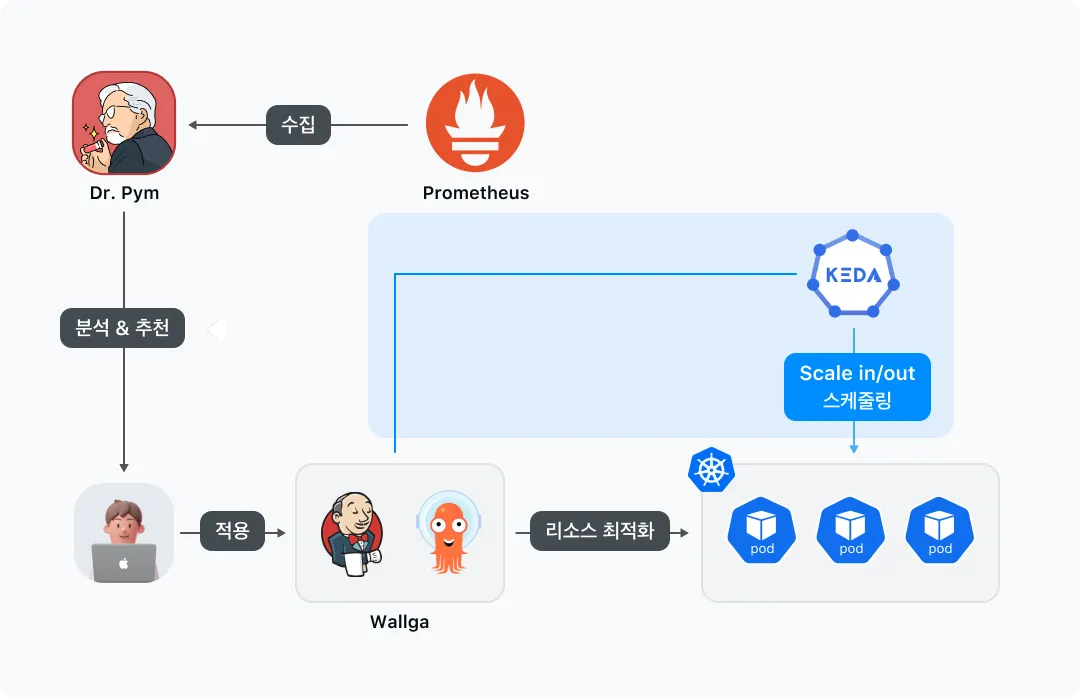
Phase 3
마지막 Phase 3입니다. Phase 3는 Phase 1에서 구성된 Dr.Pym 시스템에 기능확장이 목표이며 이 프로젝트의 핵심이라고 볼 수 있습니다.
요구사항
Phase 3의 요구사항은 크게 3가지였습니다.
- 현재 서비스의 Replicas가 적절한 값인 건가?
- 부하가 적은 시간대의 Pod를 사전에 줄이고 부하가 많은 시간대에 사전에 Pod를 늘리고 싶다.
- 서비스의 트래픽 추이를 지속적으로 확인하고 싶다.
위 3개의 요구사항을 충족시키기 위해 Dr.Pym 시스템의 요구사항별로 function들을 개발하여 시스템에 추가하였습니다.
또한 3개의 function을 구현하기 위해서 우리는 아래와 같이 추가적인 Metric도 수집을 하였습니다.
- 시간별 요청건수
- 시간별 평균응답시간
- 시간별 Replicas
그럼 이제 좀 더 상세히 각각의 function들에 대해 알아보겠습니다.
Function 소개
-
Check Enough Pod
먼저 첫 번째 기능은 최고 요청건수 시간대의 평균응답시간과 그 외 시간대의 평균응답시간을 비교합니다. 만약 최고 요청건수 시간대의 평균응답시간이 그 외 시간대의 평균응답시간과의 차이가 크다면 현재 Replicas의 수가 부족하다고 판단하고 Replicas를 늘릴 것을 추천합니다.
예를 들면 일정한 Pod 수가 유지되었다고 가정할 때 평시에 평균응답시간이 50밀리 초인 서비스가 트래픽이 많은 시간대에 100밀리 초의 평균응답시간을 내고 있다면 해당 서비스는 트래픽이 많은 시간대에 리소스가 부족하다는 것이고 Pod를 늘릴 필요가 있다는 것입니다.
평시 트래픽이 많은 시간대 평균 응답시간 50ms 100ms -
Scheduled Scaling
두 번째 기능은 적절한 최고 요청건수 시간대, 즉 정상적인 평균응답시간을 한 최고 요청건수 시간대를 구하고 이를 기준하여 Pod당 허용가능요청건수를 얻습니다. 이를 활용하여 평일, 주말의 Replicas를 줄일 수 있는 시간대를 찾고 이를 추천합니다.
예를 들어보겠습니다. Replicas 설정이 20개인 서비스가 있습니다. 이 서비스는 순간 최대 요청건수를 충분히 처리하기 위해 20개로 설정한 서비스입니다. 그러나 트래픽이 적은 시간대는 20개만큼 있을 필요가 없겠죠.
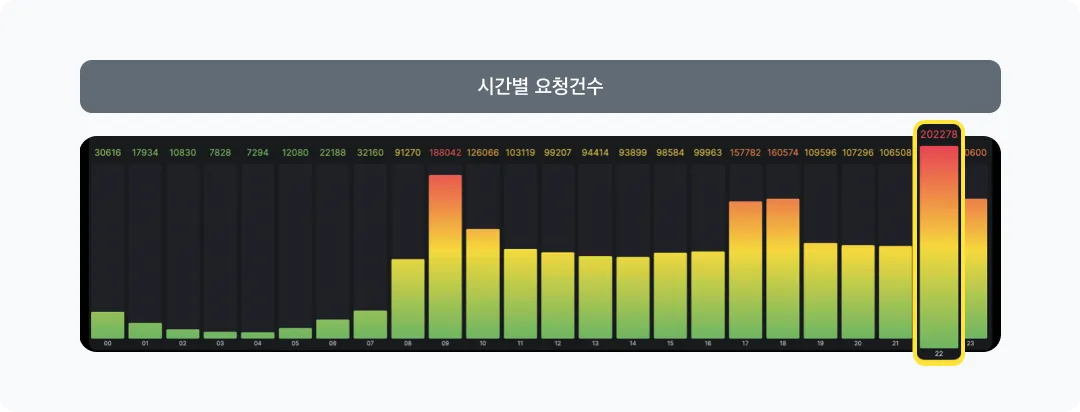
시간별 최대요청건수를 확인해 보니 이 서비스의 최대 요청건수가 20만 건이었다고 한다면 이 서비스는 replicas가 20개이므로 Pod당 1만 건이 허용가능건수가 됩니다.
Pod당 허용가능 요청건수 = 20만 건(Max건수) / 20(Pod 수) = 1만 건그럼 트래픽이 적은 시간대는 지금의 절반정도인 10개만 Pod를 유지하고 싶습니다.
Pod 10개 = 10 * 1만 건(Pod당 허용가능 요청건수) = 10만 건그렇다면 10만 건 이하로 유지되는 시간대를 찾는 겁니다.
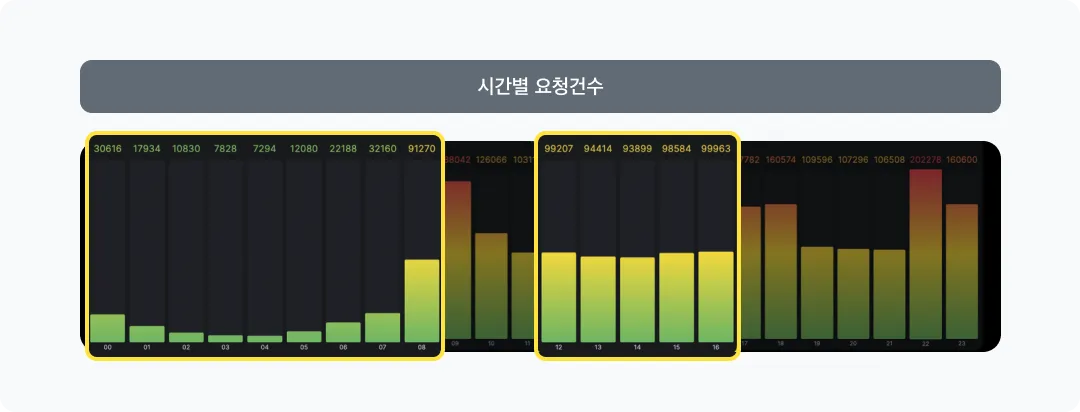
위 그래프에서는 0-8시, 12-16시가 되겠습니다. 그렇다면 해당 시간 동안에는 Pod를 10개로 줄이라고 추천을 할 수 있게 되는 것입니다.
-
Check RPS Volatility
세 번째 기능은 주별 최대 요청건수와 주별 총합요청건수를 얻고 이를 비교하여 변동성이 발생하였다면 알려줍니다.
지난주 이번주 결과 총합 1억 건 1.5억 건 50%↑ 순간 최대 20만 건 24만 건 20%↑ 예를 들면 지난주 요청건수의 총합이 1억 건이었는데 이번주 1.5억 건이었다면 지난주 대비 이번주 총합이 50% 상승하였다는 것을 알려주고 지난주 순간 최대 요청건수가 20만 건이었는데 이번주에는 24만 건이라면 지난주 대비 이번주 순간최대가 20% 상승하였다는 것을 알려줍니다.
결과
Phase 3을 거친 Dr.Pym은 더욱더 많은 분석정보를 알려주게 되었습니다.

- 첫 번째 기능을 통해 해당 서비스의 Replicas가 부족하다고 판단하면 Replicas 변경하기를 추천합니다.
- 두 번째 기능을 통해 트래픽 기준 스케일 변경이 가능한 시간대도 추천합니다.
- 세 번째 기능을 통해 최근 2주간의 트래픽 차이를 확인하고 변동성이 발생하면 알려줍니다. 이를 통해 서비스 담당자는 트래픽 추이를 확인하고 대응할 수 있습니다.
Dr.Pym = 지능형 시스템
Dr.Pym 시스템은 스스로 수집하고 분석하며 추천해 주는 지능형이면서 자동화된 시스템입니다. 하나의 통합된 대시보드를 통해 관련된 리소스 지표들을 확인할 수 있게 제공하고 한 번의 클릭만으로 추천값을 적용할 수 있게 합니다.
-
서비스 담당자는 자신의 서비스 리소스 관리를 하기 위해서 모니터링 및 분석을 지속적으로 챙겨야 합니다. 그런데 Dr.Pym은 수집된 Metric을 토대로 매주 분석하여 분석결과를 알려주기 때문에 이에 대한 수고를 덜어줄 수 있습니다. CPU와 메모리를 어떤 기준에서 추천했는지 Grafana를 통해 간편하게 사용량 확인을 할 수 있으며 Phase 3의 추가 분석에 사용된 Metric도 그라파나에서 서비스의 시간별 CPU/Memory/요청건수/평균응답시간/replicas를 확인할 수 있죠.
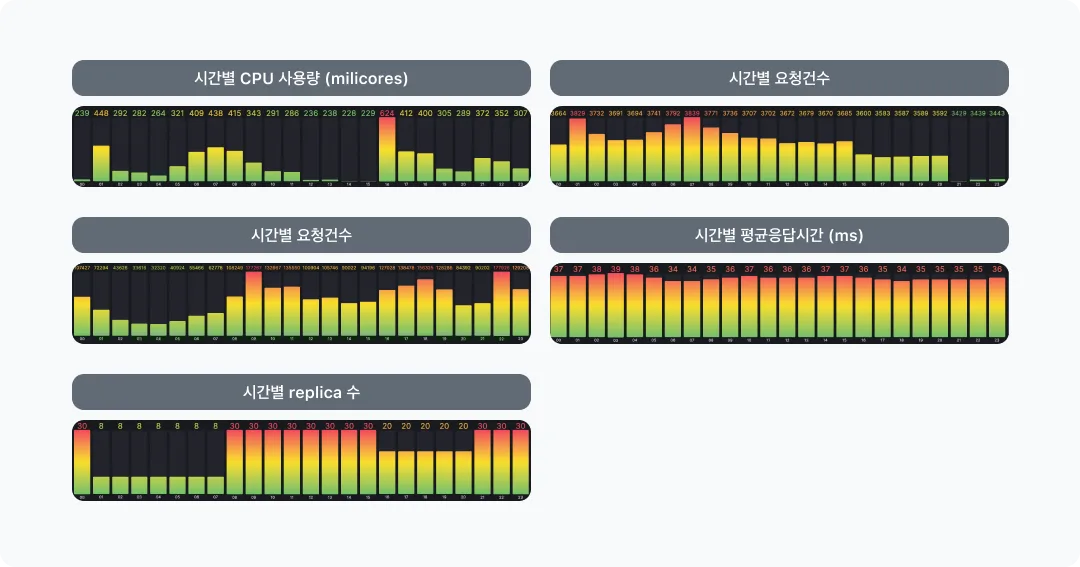
-
서비스 담당자는 운영 서비스 배포 요청 시 카카오페이증권의 릴리즈 플랫폼인 “로켓단” UI를 통해 배포신청을 하게 됩니다. 이때 Dr.Pym 시스템과의 연동을 통해 해당 서비스의 현재값과 추천값들을 보여줍니다. 그럼으로써 서비스 담당자 입장에서는 이를 확인하고 적용 요청할 수 있게 되며 RE(Release Engineer) 담당자는 이를 통해 Dr.Pym이 추천한 Rightsizing된 리소스 값으로 손쉽게 배포를 진행할 수 있습니다.
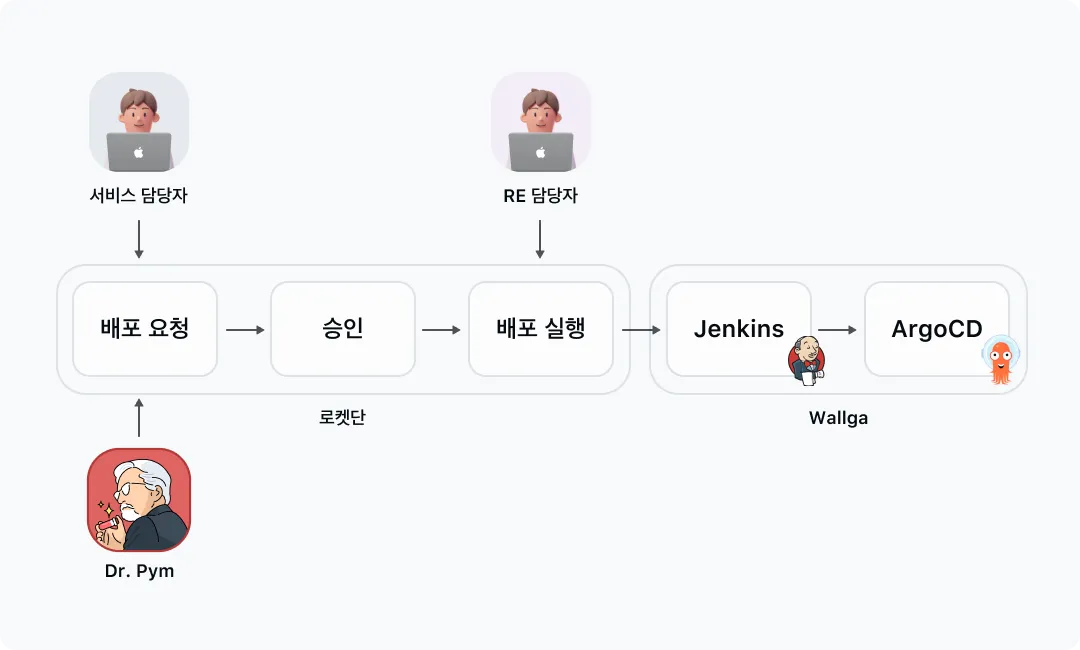
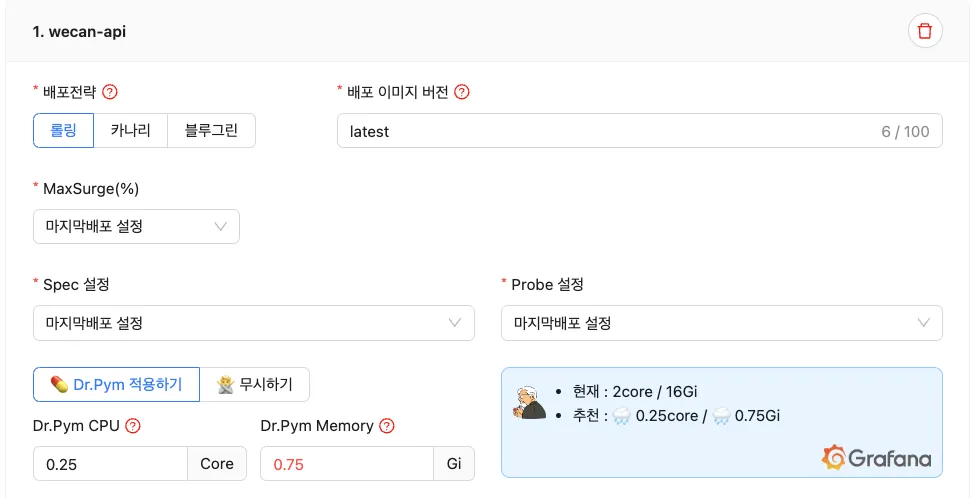
-
플랫폼 담당자의 입장에서는 여러 Kubernetes 클러스터의 서비스들에 대한 리소스 현황을 확인하고 follow-up 하려면 서비스들이 많다 보니 쉽지 않았는데요. Dr.Pym이 이를 대신해 주면서 담당자는 Grafana에서 서비스들의 Rightsizing 현황을 간편하게 확인할 수 있습니다. Grafana에서 클러스터별/네임스페이스별/애플리케이션별로 Dr.Pym 리소스 적용현황과 추천값, 그리고 각종 Metric 정보를 확인할 수 있는 것이죠.
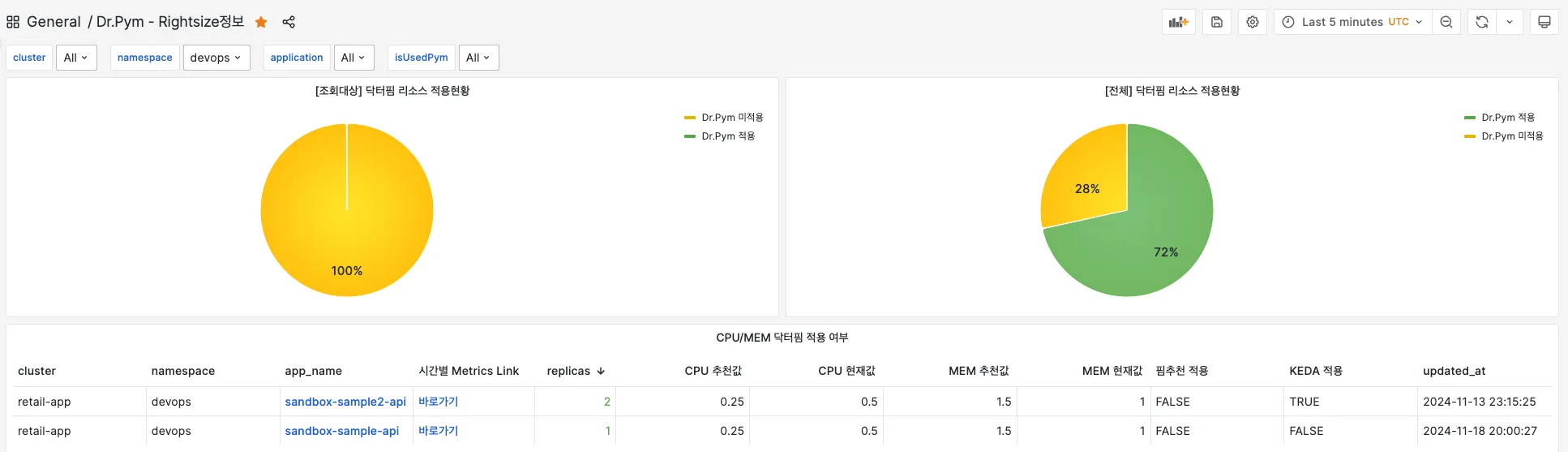
성과
Dr.Pym 시스템 도입으로 인한 성과는 크게 두 가지입니다.
- 리소스 최적화로 인한 비용 절감
- CPU Limit 제거에 따른 성능향상입니다.
먼저 리소스 최적화 부분을 보면
| CPU | Memory | |
|---|---|---|
| 개발 환경 | 46%↓ | 17%↓ |
| 운영 환경 | 54%↓ | 32%↓ |
CPU보다 메모리를 많이 사용하는 서비스들이 많다 보니 CPU에 대한 절감효과가 컸습니다. 개발환경의 경우 CPU 46%, Memory 17% 절감하였으며 운영환경의 경우에는 CPU는 54%, Memory는 32% 절감하였습니다.
그럼 비용은 얼마나 절약되었을까요?
- EKS의 경우는 리소스를 절약하게 되면 바로 비용으로 나타납니다. 약
21%절감이 되었습니다.- IDC 같은 경우는 실질 비용이 감소하진 않겠지만 리소스 절약으로 인한 여유공간이 확보가 됩니다. 그래서 IDC는 클러스터들의 노드 기준 약
18%, 100대라고 가정한다면 18대 정도 워커노드의 여유가 생겼습니다.
다음으로 성능 또한 개선되었는데요. Phase 1을 통해서 CPU의 Limit을 제거함으로써 나타난 성과입니다. 이 서비스는 기존에 CPU Limit이 4였던 서비스입니다.
## As-Is
resources:
limits:
cpu: '4'
memory: 8Gi
requests:
cpu: '2'
memory: 8Gi
## To-Be
resources:
limits:
memory: 8Gi
requests:
cpu: '2'
memory: 8Gi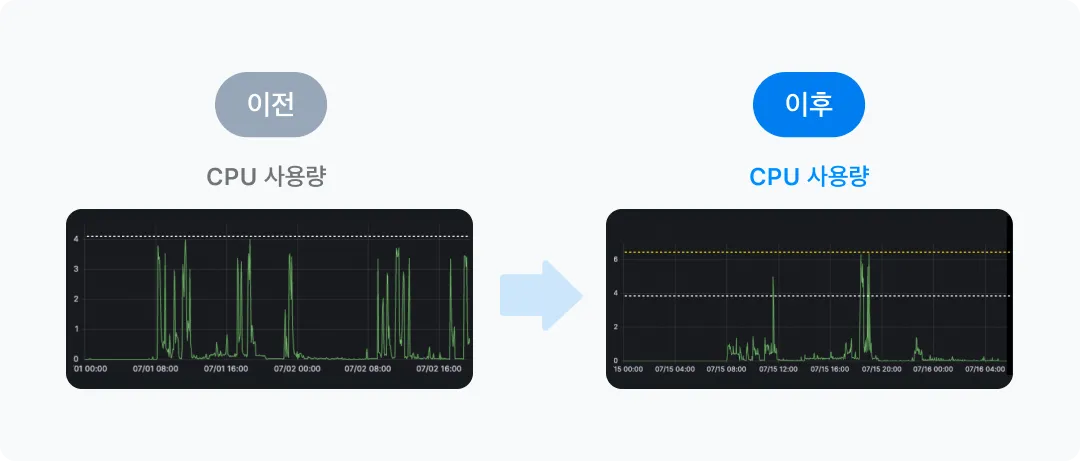
CPU Limit 제거 이후 순간적으로 6 이상까지도 사용하는 모습을 보이지만 변동성은 오히려 이전보다 이후가 더 안정화된 모습을 보이고 있습니다.
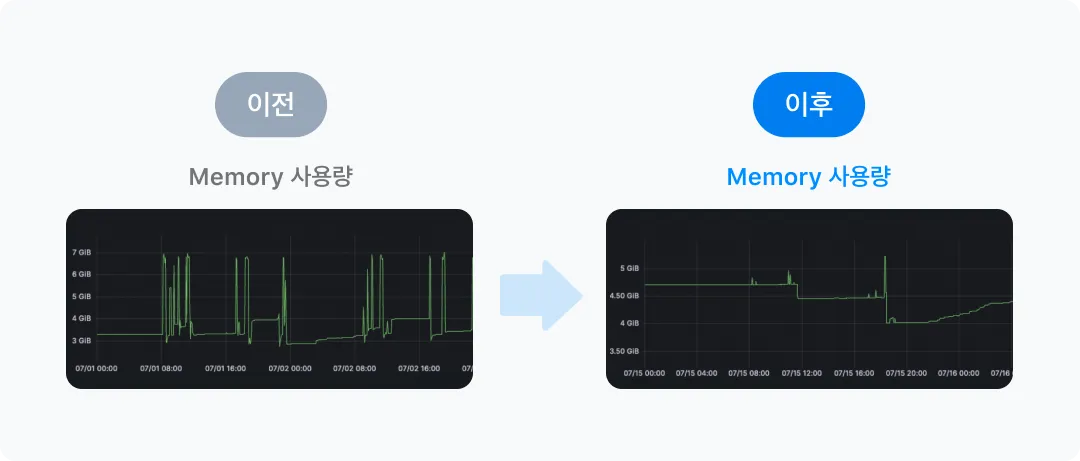
메모리 그래프 또한 변동성이 줄어든 것을 확인할 수 있습니다. CPU가 가용할 수 있는 자원이 늘어남으로써 야기된 결과로 볼 수 있습니다.
예상치 못했던 일들
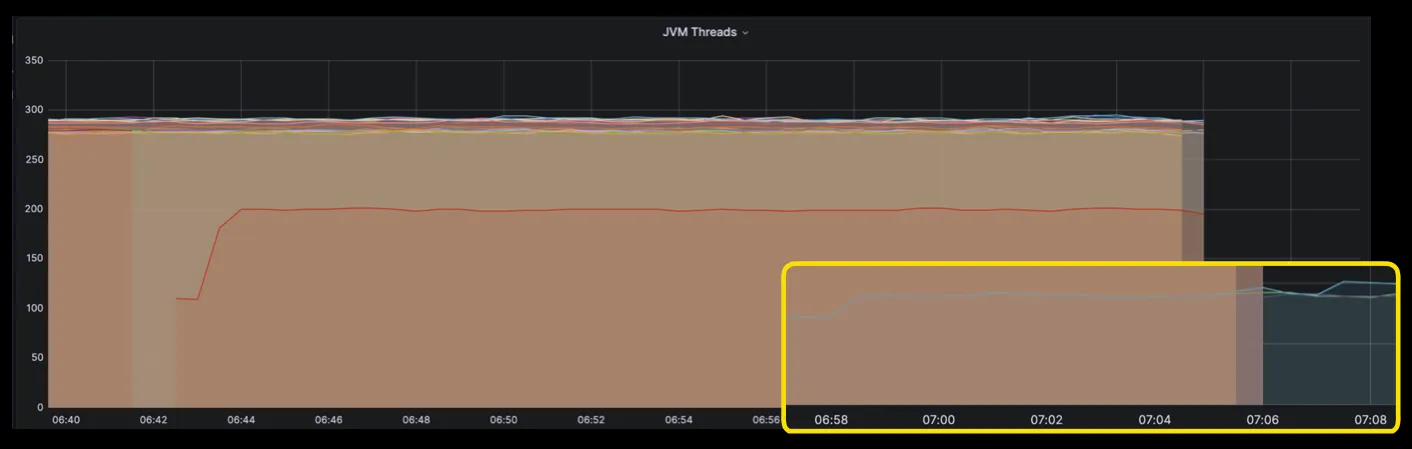
CPU Limit 제거로 인해 발생된 이슈
WebFlux를 사용하는 서비스들 중 CPU Request를 1로 설정하여 배포가 나간 서비스들에게서 JVM 스레드를 평상시보다 많이 사용하게 되고 부하가 발생할 경우 Pod들이 OOM이 발생해서 죽는 현상이 나타났습니다. 그래서 이슈를 확인하는 과정에서 WebFlux의 스레드 개수를 계산하는 코드에서 CPU Request가 1일 때 availableProcessors가 Node의 cpu 개수를 반환한다는 사실을 확인하게 되었습니다.
int DEFAULT_IO_WORKER_COUNT = Integer.parseInt(System.getProperty(ReactorNetty.IO_WORKER_COUNT,"" + Math.max(Runtime.getRuntime().availableProcessors(), 4)));
...
int CgroupV1Subsystem::cpu_shares() {
GET_CONTAINER_INFO(int, _cpu->controller(), "/cpu.shares", "CPU Shares is: %d", "%d", shares);
// Convert 1024 to no shares setup
if (shares == 1024) return -1;
return shares;
}그래서 저희는 이를 해결하고자 Wallga 파이프라인을 통해 CPU의 Request 값이 1일 경우 1.01로 변경하여 나가게끔 수정하였습니다. 또한 파이프라인에서 JVM 옵션을 통해 ActiveProcessorCount를 지정해서도 나갈 수 있게끔 개선하였습니다. 그 결과 JVM 스레드는 정상화되었습니다.
최초 계획과 달랐던 부분
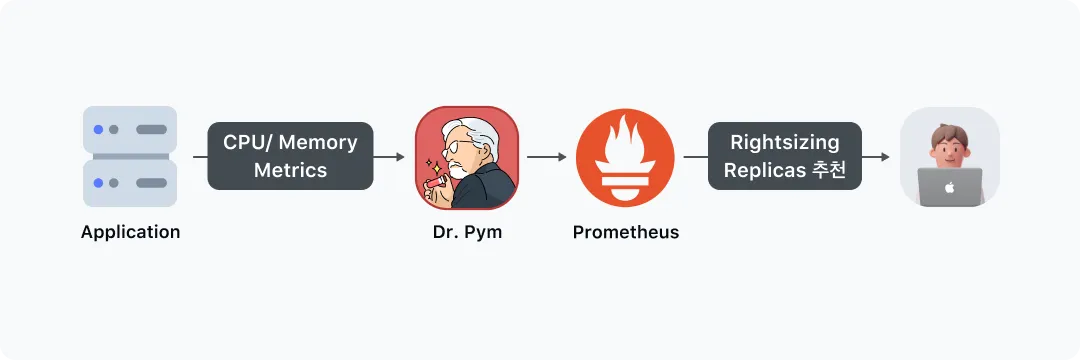
저희가 Dr.Pym 프로젝트를 계획하면서 생각했던 것은 CPU와 메모리 Metric을 활용한 상황에 맞는 Rightsizing Replicas 추천이었습니다.
예를 들면 CPU 사용률이 트래픽이 적은 시간대는 CPU의 사용량이 낮을 것이고 트래픽이 많은 시간대는 CPU의 사용량이 높겠지라고 생각을 하였고 Dr.Pym은 CPU 사용률이 낮은 시간대에 Replicas를 줄이라고 추천하면 되지 않을까라고 생각했던 것이죠.
그러나 Phase 1을 통해서 저희는 Rightsizing 된 서비스들에 대해 현황을 확인할 수 있었는데요. 현실은 대부분의 서비스들이 배포시점을 제외하고는 cpu의 편차가 크지 않았으며 메모리는 항상 일관되게 사용한다는 것이었습니다.
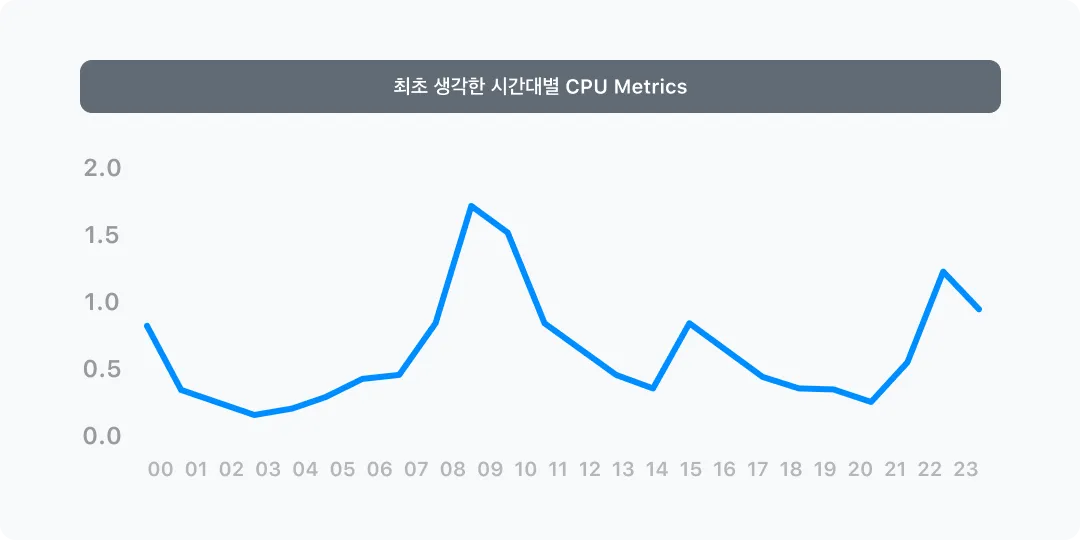
그래서 저희는 Phase 1부터 수집을 하던 CPU, Memory에 추가적으로 시간대별 요청건수와 평균응답시간까지 수집하여 활용하기로 결정하게 됩니다. 저희 서비스들의 대부분은 도메인을 통한 API통신을 하는 서비스들이었기 때문입니다. 다만 이 과정에서 API통신을 하지 않는 서비스들, 예를 들면 Consumer 같은 서비스들에 대해서는 향후 과제로 남겨놓기로 하고 진행하였습니다.
앞으로의 계획
현재 Phase 3을 통해서 구현된 추천 기능의 다양한 메트릭들을 더 추가하여 모든 서비스들이 적용가능하도록 하고 추천기능 또한 더 고도화할 계획입니다.
또한 저희가 Phase 2를 통해서 구현된 KEDA를 통해 CPU, Memory, Cron Scaler들을 사용하고 있는데요. KEDA는 그 외에도 많은 Scaler들을 제공하기 때문에 Prometheus metric를 기반한 Scaler, AI 예측기반 확장을 제공하는 PredictKube 등의 Scaler들을 플랫폼에서 제공할 수 있게 하려고 준비 중에 있습니다.
마치며
지금까지 카카오페이증권이 Dr.Pym 프로젝트를 통해 Kubernetes의 리소스 최적화를 어떻게 이루었는지에 대한 모든 내용을 설명드렸습니다. Kubernetes 운영 비용 절감이 필요하시다면 혹은 리소스 관리에 대한 관심이 생기셨다면 저희가 했던 방식을 아이디어 삼아서 진행해 보시는 건 어떨까요? 비용 절감과 서비스 안정성 두 마리 토끼를 모두 잡을 수 있습니다.
카카오페이증권에서는 플랫폼 엔지니어링을 통해 사용자(개발자) 친화적인 플랫폼들을 구성하고 확장해 가고 있습니다. 개발자들의 니즈에 맞는 적절한 환경 구성을 빠르고 완전하게 제공하고 표준화하여 관리하기 위해 노력하고 있습니다. 앞으로 카카오페이증권 DevOps 팀에 많은 관심 부탁드리면서 다음 포스트도 기대해 주세요!
감사합니다.
참고자료




















![[if kakao 2022] Batch Performance를 고려한 최선의 Aggregation](/_astro/thumb.MGIp4JrG_2cerCK.webp)
![[if kakao 2022] Batch Performance를 고려한 최선의 Reader](/_astro/thumb.CZPDDx8q_221xKf.webp)
![[if kakao 2022] 카카오페이 iOS 웹뷰 소개, 그리고 세션에서 못다한 이야기](/_astro/thumb.DTsQI1Wt_Z1kMSMB.webp)
![[if kakao 2022] ML 모델 학습 파이프라인 설계 (feat. MLOps 플랫폼)](/_astro/thumb.Dc_4_pap_ACvPj.webp)
