#BE
배포 직후 발생하는 응답 지연을 해결하기 위한 여정 (feat. JVM 웜업)
요약: 실무에서 테스트 코드 작성 시 복잡한 데이터 셋업으로 인해 테스트의 주요 관심사에 집중하기 어려운 문제가 발생할 수 있습니다. 이를 해결하기 위해 JSON 파일이나 SQL 스크립트를 활용하여 데이터 셋업을 효율적으로 관리하고, 테스트 코드의 복잡성을 줄이는 방법을 소개했습니다.
💡 리뷰어 한줄평
winnie.bird 야심 차게 테스트 코드를 작성하려 했던 첫 의도와 달리 데이터 셋업으로 혼미해질 때,,, 이 글을 활용하시길 적극 추천드립니다 :)
ari.a 테스트를 하면서 여러 가지 어려움을 겪고, 효율적인 테스트를 하기 위해서 고민하는 분들에게 테스트 전문가 윤의 [실무에서 적용하는 테스트 코드 작성 방법과 노하우] 시리즈를 추천드립니다!
katfun.joy 보다 가독성 있고 목표가 명확한 테스트를 작성하는 것은 많은 개발자들의 지향점입니다. 이러한 고민에 대한 윤의 노하우를 확인해 보세요!
시작하며
안녕하세요. 정산플랫폼 윤입니다. 지난 시리즈 실무에서 적용하는 테스트 코드 작성 방법과 노하우 Part 1에서는 효율적으로 Mock 테스트를 진행하는 방법에 대해서 살펴봤고, 실무에서 적용하는 테스트 코드 작성 방법과 노하우 Part 2: 테스트 코드로부터 피드백 받기에서는 테스트 코드에서 주는 피드백으로부터 어떻게 구현코드를 개선해 나갈 수 있는지 살펴봤습니다. Part3에서는 테스트 코드 작성 시 자주 겪게 되는 Given 단계에서의 어려움과 이를 극복하는 방법에 대해 다루어 보겠습니다.
Given 단계는 테스트 준비 단계로 복잡한 데이터 셋업이 자주 요구됩니다. 이로 인해 다양한 테스트 코드를 작성하기 어려워지고, 결국 폭넓은 테스트 커버리지를 확보하기 힘들어집니다. 이러한 문제를 해결하기 위한 전략과 실무에서 활용할 수 있는 팁들을 소개하겠습니다. 특히 객체 기반 테스트에서 Given 데이터 셋업의 한계와 이를 극복하는 방법에 대해 자세히 설명할 것입니다.
객체 기반 데이터 셋업의 난관
실무에서 주문과 관련된 테스트 코드를 작성할 때, 다양한 데이터를 여러 케이스에 맞게 셋업해야 하는 상황을 자주 맞닥뜨리게 됩니다. 예를 들어 할인 쿠폰을 적용할 때는 쿠폰의 할인율, 적용 가능한 제품, 업체와의 쿠폰 분담 비율 등 여러 가지 변수를 고려해야 합니다. 이러한 다양한 변수들이 얽히고설켜 복잡한 데이터 셋업이 필요하게 됩니다.
주문 시스템은 상품, 회원, 쿠폰, 결제 정보 등 여러 요소가 결합된 복잡한 구조로 이루어져 있습니다. 각 요소들이 상호작용하며 다양한 시나리오가 만들어지기 때문에, 모든 경우를 테스트하기 위해서는 각기 다른 데이터 셋업이 필수적입니다. 이 작업은 매우 번거롭고 시간이 많이 소요되며, 모든 경우를 놓치지 않기 위해서는 꼼꼼한 준비가 필요합니다.
특히, 객체 기반의 데이터 셋업을 통해 테스트 코드를 작성할 때 이러한 어려움은 더욱 커집니다. 객체 기반 테스트에서는 데이터 구조가 복잡해지고 각 객체 간의 의존성을 직접 설정해야 하기 때문에, 효율적으로 데이터를 셋업 하기가 매우 어렵습니다. 이는 결국 개발자들에게 큰 부담이 되며, 다양한 시나리오를 충분히 테스트하기 위한 걸림돌이 될 수 있습니다. 그로 인해 테스트의 중요 관심사가 아닌 부분이 부각되며, 그 결과로 테스트 코드의 주요 관심사에 집중할 수 없게 됩니다.
이러한 어려움을 극복하기 위해 이번 글에서는 복잡한 데이터 셋업을 보다 효과적으로 관리할 수 있는 전략과 실무에서 활용할 수 있는 팁을 공유하고자 합니다. 구체적으로, 어떤 사례들이 이러한 복잡한 셋업 문제를 야기하는지 살펴보겠습니다.
JSON 요청 데이터 셋업의 어려움

사용자가 주문을 진행하면, 주문 API에 주문 정보를 담은 JSON 데이터를 전송합니다. 이 과정에서 API 요청을 처리하는 테스트 코드 작성이 필요할 경우, 다음과 같이 작성할 수 있습니다.
@Test
internal fun `주문 API TEST`() {
// given
val dto = OrderRequest(
orderNumber = "A00001",
status = "READY",
price = 1000L,
address = Address(
zipCode = "023",
address = "서울 중구 을지로 65",
detail = "SK텔레콤빌딩"
)
)
val requestBody = objectMapper.writeValueAsString(dto)
// when & then
mockMvc.post("/v1/orders") {
contentType = MediaType.APPLICATION_JSON
content = requestBody
}.andExpect {
status { isOk() }
}
}위 코드는 객체 기반의 데이터 셋업을 통해 테스트 코드를 작성하는 전형적인 방식입니다. 요청 JSON을 객체로 생성한 후, 이를 JSON으로 직렬화하여 API 요청을 수행합니다. 이러한 방법은 초기 단계에서는 효과적일 수 있지만, 요구사항이 점차 복잡해질수록 문제점이 발생하기 시작합니다.
예를 들어 새로운 필드나 관계가 추가되면 객체 구조가 복잡해지고, 객체 간의 의존성을 수동으로 설정해야 하는 상황이 발생할 수 있습니다. 이 같은 복잡성은 테스트 코드의 유지보수를 어렵게 하고, 다양한 시나리오를 효과적으로 테스트하는데 장애물이 될 수 있습니다.
문제점
복잡한 객체 구조 설정
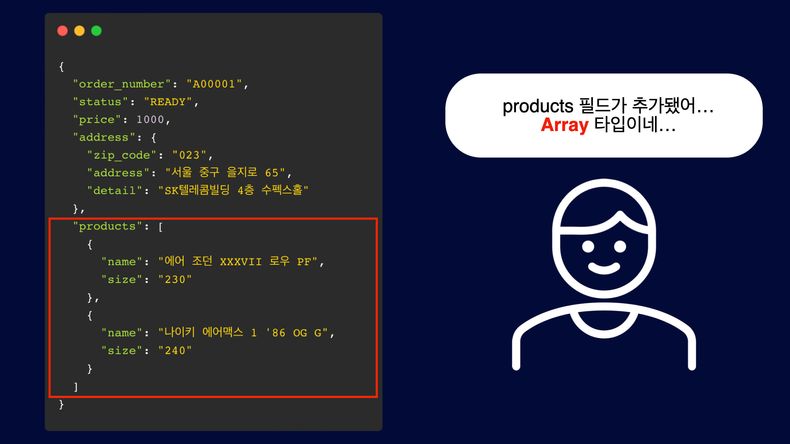
주문 API에 필드가 추가되면, 각 필드를 객체로 생성하고 설정해야 합니다. 예를 들어 product 필드가 추가되면 이를 객체 리스트로 만들어야 하고, 각 product에 대해 개별적으로 객체를 생성해야 합니다. 이러한 반복 작업은 코드의 가독성을 떨어뜨리고, 유지보수에 어려움을 줍니다.
중첩된 데이터 구조 처리의 복잡성
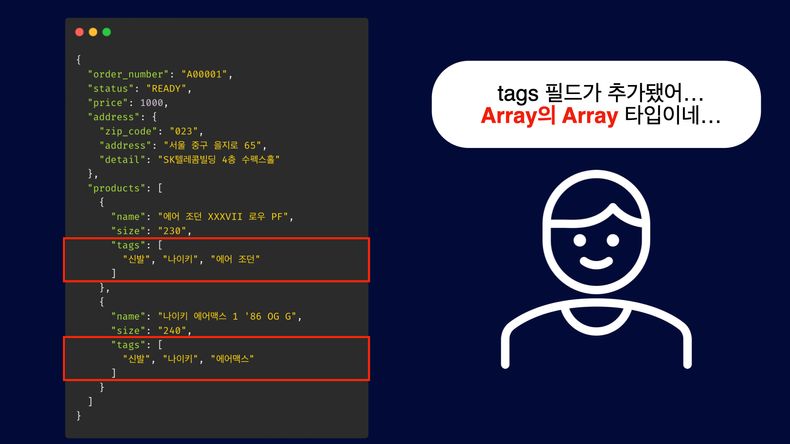
tags와 같은 중첩된 리스트 구조는 각 객체 내에 또 다른 리스트가 존재하는 형태로, 데이터 구조가 복잡해집니다. 이는 객체 생성 시 여러 단계의 중첩 리스트를 설정해야 하며, 실수를 유발할 가능성이 높아지고 코드 복잡성을 증가시킵니다. 리스트의 중첩은 특히 대규모 테스트 데이터 생성 시 문제가 됩니다.
데이터 포맷 일관성 유지의 어려움
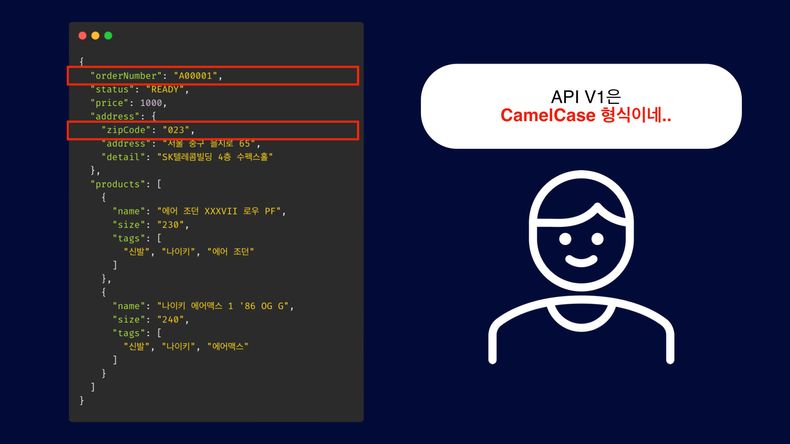
API 스펙 변경 시, 특히 필드명이 CamelCase나 SnakeCase로 변경될 경우 객체 생성 로직도 이에 맞춰 모두 수정해야 합니다. JSON 필드명이 CamelCase인 경우 복잡성이 더욱 증가하며, 데이터 포맷 일관성 유지와 코드 일관성 유지에 많은 작업이 요구됩니다.
유효하지 않은 데이터 테스트의 제약
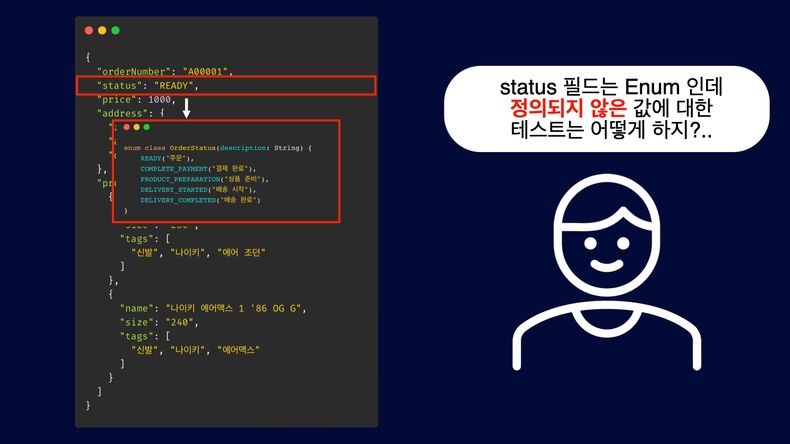
Enum 타입의 status 필드는 정의되지 않은 값을 테스트하기 어려운 환경을 만듭니다. 객체 기반 설정에서는 올바른 값만을 전송하도록 강제되기 때문에, 비정상적인 데이터 입력 시나리오를 테스트하기 위해서는 추가적인 예외 처리를 해야 합니다. 이는 코드를 더욱 복잡하게 만들고, 다양한 테스트 케이스 적용을 어렵게 합니다.
객체 기반 JSON 생성의 복잡성은 주로 이러한 문제들에서 비롯됩니다.
해결 방법
테스트 코드를 작성할 때 중요한 부분 중 하나는 테스트의 주요 관심사를 검증하는 것입니다. 테스트 코드의 목적은 주요 관심사를 검증하는 것이지, 특정 객체를 직렬화하는 것이 아닙니다. 주요 관심사가 아닌 부분 때문에 테스트 코드가 복잡해지는 것은 비효율적입니다. 따라서 테스트의 주요 관심사에 집중하여 코드를 작성해야 하며, 불필요한 부분에는 신경을 덜 쓸 수 있도록 해야 합니다. 이를 위해 JSON 파일을 이용한 데이터 셋업을 고려해 볼 수 있습니다.
@Test
internal fun `주문 API TEST`() {
// given
val requestBody = readJson("/order-1.json")
// when & then
mockMvc.post("/v1/orders") {
contentType = MediaType.APPLICATION_JSON
content = requestBody
}.andExpect {
status { isOk() }
}
}
fun readJson(path: String): String {
return IOUtils.toString(resourceLoader.getResource("classpath:$path").inputStream, StandardCharsets.UTF_8)
}요청 데이터를 JSON 파일로 관리하면 객체 기반 설정의 복잡성을 줄이고, 코드의 가독성과 유지보수성을 높일 수 있습니다. JSON 파일은 객체와 리스트를 직관적으로 표현하여 데이터 구조를 쉽게 정의하고 관리할 수 있도록 해줍니다.
복잡한 객체 구조 설정 해결
- 문제점: 객체 기반 설정에서 새로운 필드가 추가될 때마다 복잡한 객체 구조를 수동으로 생성해야 합니다.
- 해결 방법: JSON 파일을 사용하여 복잡한 객체 구조를 간단하게 설정할 수 있습니다. JSON은 직관적으로 데이터를 표현할 수 있으며, JSON 파일을 통해 객체와 필드의 추가를 쉽게 관리할 수 있습니다. 이를 통해 반복적인 객체 생성 작업을 줄이고, 코드의 가독성을 높일 수 있습니다.
- 예시: JSON 파일에서는 다양한 구조를 시각적으로 표현할 수 있어 복잡한 데이터를 직관적으로 관리할 수 있습니다.
{
"orderNumber": "A00001",
"status": "READY",
"price": 1000,
"address": {
"zipCode": "023",
"address": "서울 중구 을지로 65",
"detail": "SK텔레콤빌딩"
}
}중첩된 데이터 구조 처리의 복잡성 해결
- 문제점: 중첩된 리스트나 객체 구조가 복잡할 때 코드의 가독성과 유지보수가 어려워집니다.
- 해결 방법: JSON 파일은 계층적 구조로 중첩된 데이터를 자연스럽게 표현할 수 있습니다. 이를 통해 복잡한 중첩 구조를 간단하게 정의하고 관리할 수 있습니다.
- 예시: JSON 파일에서 중첩된 데이터를 관리할 때의 예시입니다.
{
"orderNumber": "A00001",
"status": "READY",
"products": [
{
"name": "Product 1",
"price": 500
},
{
"name": "Product 2",
"price": 500
}
],
"tags": [
["Electronics", "Gadget"],
["Special Offer", "Discount"]
]
}데이터 포맷 일관성 유지의 어려움 해결
- 문제점: API 스펙이 변경되어 데이터 포맷이 달라질 때, 객체 생성 로직도 수정해야 합니다.
- 해결 방법: JSON 파일을 통해 데이터 포맷을 한 곳에서 일괄적으로 관리할 수 있습니다. JSON 파일을 수정하면 관련된 모든 테스트에서 자동으로 적용되므로, 포맷 변경에 유연하게 대응할 수 있습니다.
- 예시: JSON 파일에서 CamelCase와 SnakeCase를 쉽게 변경할 수 있습니다.
{
"order_number": "A00001",
// SnakeCase
"status": "READY",
"zip_code": "023",
"address": "서울 중구 을지로 65",
"detail": "SK텔레콤빌딩"
}유효하지 않은 데이터 테스트의 제약 해결
- 문제점: Enum 타입의 필드에 대해 정의되지 않은 값을 테스트하기 어렵습니다.
- 해결 방법: JSON 파일을 사용하여 비정상적인 데이터 시나리오를 쉽게 테스트할 수 있습니다. JSON에서 자유롭게 값을 설정하여 다양한 케이스를 실험할 수 있습니다.
- 예시: 비정상적인 데이터 입력을 쉽게 설정할 수 있습니다.
{
"orderNumber": "A00001",
"status": "INVALID_STATUS",
// 잘못된 상태 값
"price": -100,
// 비정상적인 가격
"address": {
"zipCode": "XXX",
"address": "",
"detail": ""
}
}요약
JSON 파일을 이용한 데이터 셋업으로 테스트의 주요 관심사에 집중하는 방법을 요약하면 다음과 같습니다.
- 객체 기반 설정의 복잡성 감소: JSON 파일을 사용하여 복잡한 객체 구조를 단순화하고, 테스트의 주요 관심사에 집중할 수 있습니다.
- 유지보수 용이성: JSON 파일을 통해 데이터 구조를 쉽게 정의하고 관리하여, 코드의 가독성을 높이고 유지보수를 용이하게 합니다.
- 테스트 커버리지 확장: 다양한 테스트 시나리오를 더 간단하게 구현할 수 있어, 시스템의 견고함과 신뢰성을 높이는 데 기여합니다.
- 효율적인 데이터 셋업: JSON 파일을 사용함으로써 반복적인 객체 생성 작업에서 벗어나, 주요 기능 검증에 집중할 수 있습니다.
복잡하고 다양한 데이터 셋업의 어려움
복잡하고 다양한 데이터 셋업은 테스트 코드 작성 시 마주할 수 있는 큰 도전 과제 중 하나입니다. 특히 여러 객체 간의 복잡한 연관관계와 다양한 상태를 관리해야 하는 경우, 이를 수동으로 처리하는 것은 매우 번거롭고 오류를 유발하기 쉽습니다.
예를 들어 여러 엔터티(Entity)가 서로 얽혀 있는 상황에서 각 엔터티의 상태를 특정 시점에 맞게 설정해야 하는 경우, 객체 기반으로 일일이 설정하는 것은 많은 시간이 소요되고 유지보수도 어렵습니다. 특히 특정 시점을 검증하는 테스트 코드 작성 시, 객체 기반 데이터 구성의 설정은 복잡성과 실수 가능성을 높입니다. 이러한 문제를 해결하지 않으면 테스트 커버리지 확장이 제한되고 코드 품질 저하로 이어질 수 있습니다.
이런 상황에서, 데이터베이스의 초기 상태를 미리 정의된 SQL 스크립트를 통해 설정하는 방법이나, @Sql과 같은 도구를 활용하여 복잡한 데이터 셋업을 자동화하는 방법은 이러한 어려움을 해결하는 좋은 접근 방식이 될 수 있습니다. 이러한 도구들은 복잡한 데이터 구조를 간단하게 설정하고 관리할 수 있도록 도와주며, 개발자가 테스트의 주요 관심사에 집중할 수 있게 합니다.
특정 상태의 데이터 셋업이 필요한 경우
테스트 코드를 작성할 때 특정 시점의 데이터를 설정해야 하는 경우가 많습니다. 예를 들어 상품 준비 단계에서 배송 시작 단계로 넘어가는 테스트 코드를 작성하려면, 상품 준비 상태의 객체를 생성해야 합니다. 이때 setter 메서드가 열려 있다면 객체를 쉽게 설정할 수 있지만, 모든 setter를 열어 데이터를 조작하는 방식은 적절하지 않을 수 있습니다. 따라서, setter가 없는 프로젝트의 경우 상품 준비 상태로 데이터를 직접 설정하기가 어려워질 수 있습니다.
이러한 상황에서는 주문 -> 결제 확인 -> 상품 준비까지의 로직을 구현할 수도 있지만, 이 과정에서 테스트하려는 주요 관심사를 명확히 이해하는 것이 중요합니다. 우리가 집중하고자 하는 테스트는 상품 준비에서 배송 시작으로의 전환이지, 주문 및 결제 확인에 대한 테스트가 아닙니다. 주문과 결제 확인 로직이 변경될 경우, 주요 관심사와 무관한 부분 때문에 테스트 코드가 실패할 위험이 있습니다.
해결 방법

@Sql 기반 데이터 셋업을 활용해 이와 같은 문제를 해결할 수 있습니다. @Sql 어노테이션은 테스트 실행 전에 지정된 SQL 파일을 실행하여 데이터베이스 상태를 원하는 대로 셋업해 줍니다. 복잡한 로직을 직접 코드로 처리하지 않고, SQL 파일로 필요한 상태를 설정할 수 있어 테스트의 핵심 기능 검증에 집중할 수 있습니다. 이를 통해 객체 기반 테스트 코드의 복잡성을 줄이고, 테스트 코드 작성의 효율성을 높일 수 있습니다.
복잡한 데이터 연관관계 설정이 필요한 경우
위 이미지는 복잡한 연관관계를 가진 주문 시스템을 나타내고 있습니다. 이 시스템은 상품, 회원, 쿠폰, 결제 정보 등 여러 요소가 결합된 복잡한 구조로 이루어져 있으며, 이러한 구조 속에서 객체 간의 연관관계와 외래 키(FK) 제약 조건을 처리하는 것은 매우 번거롭고 복잡할 수 있습니다.
해결 방법
@SqlGroup을 사용해 복잡한 데이터 셋업을 보다 쉽게 관리하면 위와 같은 문제를 해결할 수 있습니다. 아래 SQL 스크립트와 코드 예제를 통해 복잡한 데이터베이스 연관관계를 간단히 설정할 수 있습니다.
// schema.sql
CREATE TABLE member...;
CREATE TABLE coupon...;
CREATE TABLE product...;
CREATE TABLE payment...;
CREATE TABLE orders...;
// setup.sql
INSERT INTO member (id, name, email)
VALUES (1, 'John Doe', 'john@example.com'),
(2, 'Jane Smith', 'jane@example.com');
INSERT INTO coupon (id, discount, member_id)
VALUES (1, 10.00, 1),
(2, 15.00, 2);
INSERT INTO product (id, name, price)
VALUES (1, 'Product A', 100.00),
(2, 'Product B', 200.00);
INSERT INTO payment (id, order_id, amount, payment_date)
VALUES (1, 1, 300.00, NOW()),
(2, 2, 600.00, NOW());
INSERT INTO orders (id, orderer_id, created_at)
VALUES (1, 1, NOW()),
(2, 2, NOW());
// delete.sql
delete from member...;
delete from coupon...;
delete from product...;
delete from payment...;
delete from orders...;*.sql 파일을 통해 스키마를 설정하고, FK(외래 키) 관계를 가진 데이터를 직관적이고 쉽게 설정할 수 있습니다. 또한, 테스트 후 데이터를 삭제하는 쿼리를 통해 테스트 환경을 초기 상태로 되돌리는 방법도 포함되어 있어, 데이터 셋업과 정리 과정을 명확하게 관리할 수 있습니다.
@SqlGroup(
Sql(
value = ["/schema.sql", "/setup.sql"],
config = SqlConfig(
dataSource = "dataSource",
transactionManager = "transactionManager"
),
executionPhase = Sql.ExecutionPhase.BEFORE_TEST_METHOD
),
Sql(
value = ["/delete.sql"],
config = SqlConfig(
dataSource = "dataSource",
transactionManager = "transactionManager"
),
executionPhase = Sql.ExecutionPhase.AFTER_TEST_METHOD
)
)
@Test
fun `sql test`() {
// when
val payments = paymentRepository.findAll().toList()
// then
then(payments).hasSize(12)
...
}위 예제에서는 @SqlGroup을 사용하여 여러 SQL 파일을 한 번에 실행하고 관리함으로써 데이터베이스 스키마 설정 schema.sql, 데이터 셋업 setup.sql, 그리고 테스트 후 데이터 정리 delete.sql까지 효율적으로 처리할 수 있습니다. @Sql과 @SqlGroup을 활용하면 복잡한 데이터 구조 설정 및 관리가 간편해지고, 개발자는 테스트의 주요 관심사에 집중할 수 있습니다. 또한 여러 데이터베이스를 사용하는 환경에서도 데이터소스 지정을 통해 복잡한 데이터 구성을 손쉽게 설정할 수 있어 다양한 환경에서의 테스트가 더욱 용이해집니다.
특히, 다양한 데이터를 에그리게이션(aggregation)하여 데이터를 가공하는 배치 애플리케이션의 테스트 코드에서는 이러한 방식이 매우 적합합니다. 복잡한 데이터 변환과 집계 작업을 손쉽게 검증할 수 있도록, 여러 단계의 데이터 셋업과 정리가 필요한 경우에도 @Sql과 @SqlGroup을 통해 효율적으로 테스트 환경을 구축할 수 있습니다.
요약
.sql 파일을 이용한 데이터 셋업으로 테스트의 주요 관심사에 집중하는 방법을 요약하면 다음과 같습니다.
- 비즈니스 로직과의 분리: 비즈니스 로직의 변경과 무관하게 테스트 셋업을 수행할 수 있어, 테스트가 필요한 동작에 집중할 수 있습니다.
- 유연성: SQL 스크립트를 통해 복잡한 데이터 시나리오를 빠르게 설정할 수 있으며, 객체 생성을 반복적으로 하지 않아도 됩니다.
- 유지보수 용이성: SQL 스크립트를 통해 테스트 데이터 셋업을 관리함으로써, 데이터 준비와 테스트 검증을 분리하여 코드를 더 깔끔하고 유지보수하기 쉽게 만듭니다.
- 복잡한 데이터 집계 작업의 용이성: 다양한 데이터를 에그리게이션(aggregation)이 필요한 경우 SQL 스크립트를 통해 여러 단계의 데이터 셋업과 그 흐름을 효율적으로 관리할 수 있습니다.
마치며
테스트 코드 작성 시 다양한 케이스를 충족하는 것은 매우 중요하며, 이를 위해서는 유연한 데이터 셋업이 필수입니다. 하지만 객체 기반으로 데이터 셋업 환경을 구축하는 것은 꽤나 복잡하고 비효율적일 수 있습니다. 필연적으로 많은 코드를 요구하여 테스트의 핵심 목표인 주요 관심사 검증에 집중하기 어렵게 만들기 때문입니다. 이는 결국 테스트의 본질을 흐리고 주객전도를 초래할 수 있습니다.
이러한 문제를 해결하기 위해 여러 방법을 고려할 수 있고, 위에 제시한 방법 외에도 다양한 해결책이 존재할 수 있습니다. 중요한 것은 상황에 맞는 효율적인 방법을 찾아 적용하는 것입니다. 마지막으로, 테스트 코드 역시 운영 코드와 마찬가지로 지속적인 관리와 개선이 필요하다는 점을 강조하고 싶습니다. 테스트 코드 작성에 어려움을 느낀다면 원인을 분석하고, 더 쉽고 다양한 테스트 코드를 작성할 수 있도록 지속적으로 개선해 나가야 합니다. 이러한 노력은 궁극적으로 시스템 안정성과 신뢰성 향상에 큰 도움이 될 것입니다.





















![[Project Loom] Virtual Thread에 봄(Spring)은 왔는가](/_astro/thumb.04c0dd4c_ZhvlpT.avif)


















![[if kakao 2022] Batch Performance를 고려한 최선의 Aggregation](/_astro/thumb.84295604_ZC835U.avif)
![[if kakao 2022] Batch Performance를 고려한 최선의 Reader](/_astro/thumb.f4bb869d_19IKlP.avif)